
自然言語処理⑥~LDA~

前回で書き切ろうと思っていましたが、長ぁくなりそうだったため今回LDAと100本ノック5章を扱う回にします。
(追記:100本ノック5章は自分の理解が少しまだ甘いため、後日再度復習時にします〜)
LDAは自分が以前勉強した際には出てこなく、本当に最近知りました。
簡単に言えば、その文書がどういうジャンル(スポーツか経済かエンタメなのか?)ということを教師なしで分類していくことです。
では今回もよろしくお願いします。
1・LDAの外観を理解する
いつもながらまずはイメージなどでLDA(潜在ディリクレ配分)を理解していきます。
本格的な理論理解となるとベイズ推定などが出てくるので、自分が理解できそうであればしますw
できなければコードのみにしますw
まずは図である程度説明して行きます。
まずテーマは解析する文書がどういうトピックなのか?です。

そこで各文書の中のキーワード(のちのコードをみると、形態素解析した後にCountvectorizerに入れて文書のベクトル化をしているイメージ)を取り出して判別してみます。
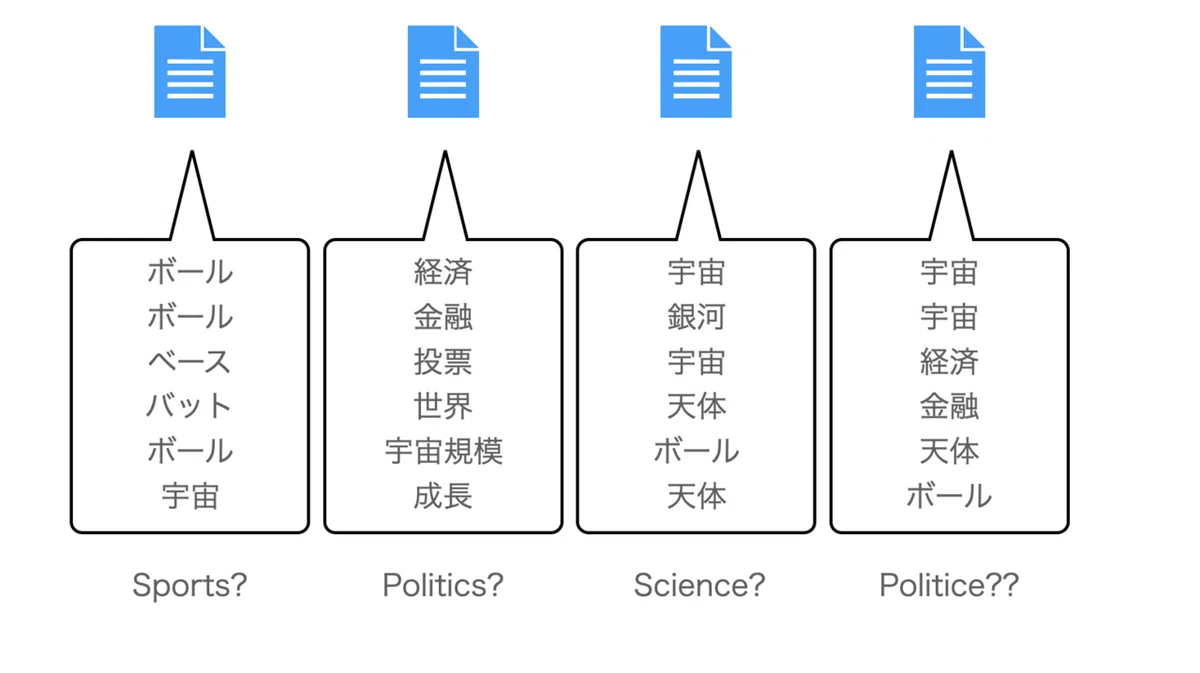
実際にこのトピックの名前は機械では難しいため、我々が頭を使って考える領域となります。
ここで、一般的なディリクレ分布と言われるグラフを見ながらちょっと深掘りしてみます。
およそトピックの検討をつけるためにこれらを確率的に配置したものがディリクレ分布となります。
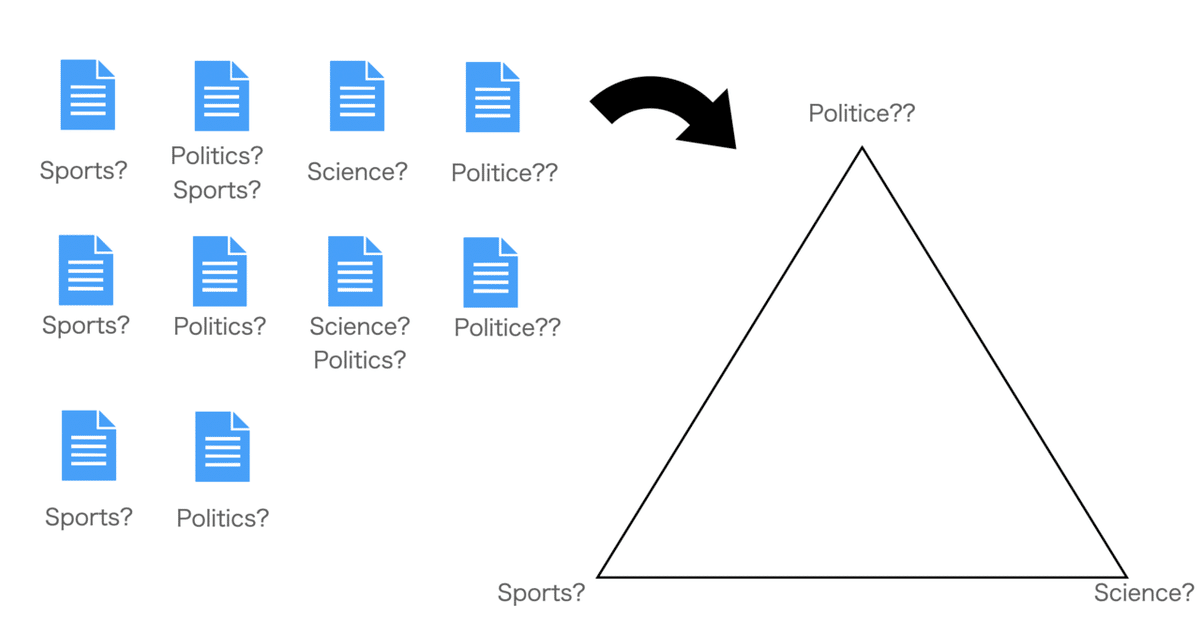

隅にいけば行くほどより明確に分類できていますが、どちらかわからない場合はその間をうろうろします。
また、どのトピックも同じくらいありうる場合は真ん中に寄って行きます。
ちゃんとした書き方をする場合、一つ一つに確率が割り当てられ、
(a=0.88, b=0.1, c=0.02)のような表示でそれぞれ位置しています。
少し理論的な話の補足をすると、ディリクレ分布とは出てきた単語の回数を入力すると、それぞれの単語の確率を出してくれるような関数をイメージしておくといいでしょう。
・LDAの実際の理論(簡素)
やや込み入った話になりますが、できる限り平易な言葉を使って行きます(前回の内容などの用語は出てくるかと思いますが、、)
先ほどまでの外観を理解したところで、実際の生成過程の話になります。(基本的に他のサイトで十分わかりやすいかと思います。)
まず先にイメージを見て、細かく見ていくことにします。

順を追って説明します。
まずは上二つ。

αをディリクレ分布のパラメータ(それぞれの単語の回数)からそれぞれの単語が出現する確率を出力します。
この確率と単語の総回数N使って次に多項分布により書くトピックの単語を振り分けます。
例えば、N=10と、トピックのそれぞれの確率(スポーツ50%, 政治30%, 科学20%)があると、θ_dで返す値は
(スポーツの単語, 政治の単語, 科学の単語)= (5, 3, 2)(回)
となります。
これと同じことが左下部分でも行われます

ここではトピックに関する単語の出現確率を出力しています。
これによりどのトピックにどういう単語が現れやすいのかを次に入力することができます。
残りの部分でそれぞれの入力からBoWを生成します。

上の部分では入力として総数からトピックの確率が出力、左部分ではトピックにおける単語の確率が格納されているため、それぞれをinputした時に結果的に出てくる単語回数を格納したvectorが最終的に返ってきます。
スポーツの色に「選挙」が入っているのは、あくまで確率を格納しているため、スポーツトピックに選挙という言葉がある確率が0でない限り、出力される可能性があります。その例として記載しています。
これがLDAの外観とざっくりとした理論です。
掴みにくいな〜と思った方は他のサイトにもわかりやすい例があるので、ぜひご覧ください。
ちなみに、これを最終的に数式で表しますが、以下のURLを参照することに止めようと思います。
・pythonでLDAの実装
では、実装をしてみて実際の使い方などを見てみましょう。
まずはデータの準備から。
今回も大量の文書を扱いたい関係で映画のデータセットを使うことにします。
!wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -zxf aclImdb_v1.tar.gzimport os
import pandas as pd
import numpy as np
basepath = 'aclImdb'
labels = {'pos': 1, 'neg': 0}
df = pd.DataFrame()
for data_path in ('test', 'train'):
for sentiment in ('pos', 'neg'):
path = os.path.join(basepath, data_path, sentiment)
for file in sorted(os.listdir(path)):
with open(os.path.join(path, file), 'r', encoding='utf-8') as infile:
txt = infile.read()
df = df.append([[txt, labels[sentiment]]], ignore_index=True)
df.columns = ['review', 'sentiment']
np.random.seed(0)
df = df.reindex(np.random.permutation(df.index))上記は特に気にせずコピペでまずは準備しちゃいましょう。
では、実際にLDAを。
まずはコードから見て行きます。(ちなみに以下のコードは多少時間がかかりますため、ローカル環境の方はご注意ください。)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
count = CountVectorizer(stop_words='english', max_df=.1, max_features=5000)
X = count.fit_transform(df['review'].values)
lda = LatentDirichletAllocation(n_components=10, random_state=123, learning_method='batch')
X_topics = lda.fit_transform(X)今回は全てのデータをメモリに載せるので、CountVectorizerが使えます。
parameterのmax_df=.1により、10%以上の頻度で出てくる単語は排除して、さらに総出現回数が5000以上となる単語も排除しています(この辺は各自調整してみるとまたいろんなトピックを得られることができるので試してみても面白いと思います。)
class sklearn.decomposition.LatentDirichletAllocation(n_components=10, *, doc_topic_prior=None, topic_word_prior=None, learning_method='batch', learning_decay=0.7, learning_offset=10.0, max_iter=10, batch_size=128, evaluate_every=- 1, total_samples=1000000.0, perp_tol=0.1, mean_change_tol=0.001, max_doc_update_iter=100, n_jobs=None, verbose=0, random_state=None)
(PCAと同じく次元削減の関数が多く格納されているdecompositionですね)
n_components: 欲しいトピックの数を指定
doc_topic_prior: 文書トピックをガンマ分布にて優先度を決定(=1であればα分布)
topic_word_prior: 単語トピックの優先度を決める
learning_method: {‘batch’, ‘online’}で指定。fitメソッドのときに使用され、online の方がbatchよりも高速処理が可能。
learning_decay: learning_method='online'の時に学習率の指定が可能
(残りは割愛)
LDAのもつ属性のうち、components_を指定することでトピック数(今回は10)と単語の重要度が格納されたndarrayが出力されます。
lda.components_.shape
>>> (10, 5000)メソッドに関してはいつものfit などやonline利用時に使えるpartial_fitなどもありますが、特筆して書いた方がいいものも思いつかないので、一旦割愛します。
それぞれのトピックに対してどういう単語が出てくるのかをみてみます。
n_top_words = 5
feature_names = count.get_feature_names()
print(feature_names[:3])
print(feature_names[-5:])
for topic_idx, topic in enumerate(lda.components_):
print(f'Topic {topic_idx + 1}')
print(topic.argsort()[:-n_top_words - 1: -1])
words = ' '.join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1: -1]])
print(words)
feature_namesにより特徴量の名前を取得し、lda.components_でそれぞれのリストにある重要度の数値を高い順に並び替えて、argsort()にすることでインデックス番号で単語を取得して行きます。
今回の結果でそれぞれの単語からトピックを人間が命名して行きます
例えば、topic 2 などであれば家族映画(movies about families)など
では、index 5 に関しての上位3つの最初の単語300個を見てみましょう。
horror = X_topics[:, 5].argsort()[::-1]
print(horror[:3])
for iter_idx, movie_idx in enumerate(horror[:3]):
print(f'Horror movie #{iter_idx + 1}')
print('--')
print(f"{df['review'][movie_idx][:300]}, ...")
ってなわけで、LDAをみてきました
やや細かめに解説しましたが、実例は意外と簡素だったかもしれませんね。。。
kaggleなどでも良い例があればみて行きたいですが、一旦はこれで区切りましょう・
・100本ノック第5章(保留)
cabochaを使ってゴリゴリするのですが、自分がcabochaやかかり受けの理解が少し微妙だったため後日。。
・終わり
次回はDoc2Vecに関して行い、余力がありそうならSVMとかを使った文書分類までいけたらと思います(あと100本ノックも。。)
では、次回!
この記事が気に入ったらサポートをしてみませんか?