
自然言語処理⑧ ~RNN(入門)~

100本ノックの6, 7章が今までの投稿の内容を総まとめしているものだったので、次回以降の近いうちに100本ノックの6, 7章の回を設ける予定です。
ちなみに5章はクセが個人的に強く、ちょっと後回しにしています。
今回はRNNを扱います。
自分も存在自体は知っていましたが、
NLとかディープラーニングの(個人的偏見にまみれた)イメージは「どうせtensorflowのテンプレートつかうだけしょ!」っていう印象がめちゃ強くて、どうやって勉強していこうかしら?なんて思っていました。
しかし、自然言語処理でもどうせBERTとかtransformerとか扱う上でRNNも避けれなかったりするので、自分も書きながら学び、そしてあなたも読みながら学んでいくのがいいのかなと思います。
いつもながらわかりやすく解説しているサイト・動画なんてありふれてますから、適宜他のサイトも大いに参考にしちゃってください
では、今回もよろしくお願いいたします。
~RNNイントロ~
いきなり数式どん!ってなると離脱がすごいので簡単にイントロを。
RNNはrecurrent Neural Network(再帰的ニューラルネットワーク)で、いわゆる時系列データを扱うようなニューラルネットをイメージしてもらえればと思います。
つまり、、、
時間軸に沿ってデータを学習して行きます。
具体的な活用事例には
音声データ・音楽・株価・・・など本当にたくさん用いられています。
もちろん完璧なものなんてないので、RNNにも弱点がありますが、それを補うアプローチ(LSTMなど)も追って説明していけたらと思います。
では、以下からRNNの中身に参ります。
~RNNの概論~
いきなり数式どん!とか、グラフのイメージは〜とか、中間層が〜というより、身近な例から考えてみます
日本語で「私は山田です。」という文章を英語に翻訳することを例に取りましょう。
もちろん、I am Yamada. が正解になるわけですが、ほぼ無意識に翻訳できるこの流れを少し詳細に考えてみます。
日本語で「私は山田です。」をみた時に必ず
私→は→山田→です
という順番で文章の仕組みを考えます。
『私』で「あ、主語は『私』なのね」と理解し、
『は』で「『私は』何か、なのね」となり、
『山田』で「『私は山田のなんか』、なのね」となり、
『です』で「『私=山田』!」っなるわけです。
この処理にかかる時間なんて、コンマ1秒もないレベルで処理していますが、実際はこのような流れで文章理解をしていますよね。
では、これを理解して英語に翻訳するときの流れを見て行きます。
初めに「私は山田です」という文章を書きたい!っていう要望を実現したいことから、それを地道に実現していくことになります。
まずは「I (私)」を書き、そのあとは「=山田」であることを書きさえすればいいので、「am Yamada」を付け、最後に「. (ピリオド)」を打って完成!
ってなります。
これをRNNに即したグラフにしてみると以下になります。

大丈夫です、ちゃんと説明しますw
一旦xやらy やらの記号は全無視して、先程の流れだけをみると、
上の段で日本語で意味を理解し、下の段では理解した意味をどう英語に落とし込むのか?という流れとなります。
では、(私も含めて)xとかyとかhとかh'とか、何?は?まじで?なんやねん?って方に向けてもう少し掘り下げてみます。
少しわかりにくくても、ふんわりと読むくらいでも大丈夫です。
x_0という入力(ここでは左から順番に見ていく単語)から始まり、文章を繋げるような関数hに入れて行きます。
次にその情報を保持した状態で次の入力x_1(ここでは「は」という用語)が入力されます。
すこし噛み砕くと、h_0で「私」という情報を保持して、その後に「は」というワードが入力されたので、h_1では「私は」という状況を保持しています。
それを順番に繰り返し、上の段の最終点x_t(「。」)でh_tには「私は山田です(私=山田)」を理解した状態になります。
下の段では上の段で生成されたタスクh_tをスタート地点(h'_0)として、そのタスクを解決するように流れが発生します。
そのために、逐次的に出力y_iが吐き出され、それに応じてタスクh'_iが更新されていく仕組みになります。
上記をまとめると以下のようになります。

これをグラフで表したのが、よくみるRNNの図になります。

いままでよくわからない!って方も少しは見やすくなりましたか??
ちなみに、さらに簡素に書けば以下(こっちも見たことあるかもです)

・RNNの3つのカテゴリ
大体の外観はわかったかな〜というところですが、
深掘りしますと、RNNには3種類のタスクがあります。
その前提として、先程の図に戻ってみます。(ちょっと変更してます)

この図からinput(要素⇨)とoutput(→要素)の2パターンがあります。
そして、そのinput, outputにも細分化すると
input: x_i or h_(-1)
output: ( y_i or h_i ) or ( y(t) or h(t) )
(y_i全てもしくはy_tのみ、or h_i全てもしくはh_tのみというパターン)
があります。
それぞれseq2vec, vec2seq, seq2seqと言われたりします。
順に説明します。
- seq2vec(多対一)
自然言語処理だけでなく、系列データをそもそもsequenceデータと言います。
シーケンスが入力されて、vectorで返されます
以前に解説したLDAの文書→トピックをラベルづけするイメージが近く、感情分析などに使われます。
あるいは、株価予測などもあります。
可変長の特性がRNNではもてはやされることがありますが、このように多次元の長さをベクトルに変えれるようなことができるため、非常に処理としてありがたいケースがあります。
- vec2Seq(一対多)
代表的なのは画像のキャプション生成がよく言われます。
画像をまずCNNなどで畳み込み情報をうまく抽出した後にRNNにそれをinputすることで、画像の情報を文章にするイメージです。
少し噛み砕くと、りんごの画像があったときに、CNNで畳み込み、RNNで「りんごです」という文章を生成するイメージ。
- seq2seq(多対多)
sequenceの入力に対して、sequenceが出力されます。
最初に取り上げた翻訳のようなもの(ちなみにseq2seqの遅延モデルという。このほかには同期モデルというのもある)やチャットbotなどもこちらになります。
- RNNのシンプルなモデルとGRU
ここまででRNNの「概論の概論」を見てきました。
では、もう少し踏み込んでみます。
そのためにRNNには勾配爆発や勾配消失などの問題(いまは気にせず読みましょうw)がありまして、それを解決するためにLSTMやこの章で話すGRUが必要となります。
その前に、SimpleRNN(いままで示してきたような中間層一つのRNN。単層RNN)では限界がある、ということを見て行きます。
やや込み入った数式が出てきますが、都度解説しますので、お付き合いください(どうしても嫌!って方は流し見でも今はおけです!)
上のおさらいとして、
入力にはx_0, ..., x_tもしくは最初の時点で既に持っている情報h_(-1)が、
出力にはy_0, ..., y_t、最後の隠れ層h_tが出てきました。
ここで、記号の準備として、以下を定義しておきます。

これを踏まえた上で、SimpleRNNは以下の式となります

初見殺し、数学嫌いなやつを門前払いするような数式ですが、少し細かく見て補足を入れて行きます。
(参考書によってはtanhではなく、φとして表記されていることもありますが、tensorflow.keras.layersのSimpleRNNの活性化関数のデフォルトがtanhであるため、上記のような表記で進めます。)
先ほども書きましたが、今回の入力はx_t, h_(t-1)(ちなみにどちらも次元数は隠れ層と同じ)であり、それらを重みが入った行列にかけて線型結合しています。
ちなみに、b_nはバイアスと言われるもので、今は気にしなくても進めれるので、そんなのが足されてるな〜くらいで進めちゃいましょう。
tanhというのは「タンジェントハイパボリック」と読み、高校数学で
y = tan(x)を見たことがあると思いますが、その兄弟のようなものです。
関数の取り扱いなどはここで踏み込みませんが、性質を簡単に紹介すると
x -> -∞, +∞ のとき、tanh -> -1, 1となります。
めちゃくちゃ莫大な範囲をぎゅっとできる関数なんだな〜くらいでおけです(踏み込みすぎると私がパンクするのでw)
この関数をみると、出力されたh_tの値というのはかなり頻繁に変わってしまいます。
(ちょっと込み入った話をすると|W_hh| > 1 or < 1 であるとき、t-kが大きいなら、W_hh**(t-k)が非常に大きく(小さく)なる)
噛み砕くと、基本的には一つ前の単語と隠れ層を参照しているわけで、長文の文書を読み込むと「あれ?最初の方、何言ってたっけ?」ってなるわけです。
そこで出てくるのがGRUとなります。
GRUの理論
では、GRUの何がいいのか?どういうものなのか?に踏み込んでみましょう。
この章も数式を使いますため、アレルギーのある方は読み飛ばす、もしくはかいつまんで読むだけで大丈夫です(噛み砕いた説明も加えるつもりですので。)
ちょっと大胆ですが、先に式をみます。

何事かと思うような式ばかりですが、これがGRUとなります(ちなみに、「・」は内積ではなく、アダマール積のことです。これに関しても踏み込まないですが、行列やベクトルのそれぞれの要素を掛け合わせるものです)
数式を解説して行きますが、fにσとかtanhとかrが付いているのは、sigmoid関数もしくはtanh関数ですよ!という宣言のようなものです。
では、一つずつゆっくりと見て行きます。
--------
まず、
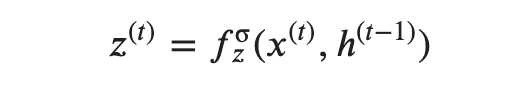
ですが、一番下の数式をみてみると、

隠れ層h_(t-1)と新しい隠れ層h`_(t-1)(便宜上「~」を「'」と記載)を1-z:zで分割していることを読み取れます。
実はここがGRUのポイントだったりします。
導入時にSimple RNNでは長い文章になると記憶が持たないという話をしました。
ここで z = 0 とおくと、h_t = h_(t-1) ってなります。
・・・・
どうです???
これ、つまり過去の情報(隠れ層)をそのまま伝番しているんですよね。
つまり、文脈が変わらないようなケース(z ≒ 0)では過去の情報をほとんど損なうことなく保持し続けていませんか??
じゃあ、z=1のときを考えます。
先程の式から、h_t = h'_t ってなります。
つまり、過去の情報を一切影響を及ぼさなくなります。
え?だめなやつやん!記憶の話してるのに!
っていう方もいるかもしれませんが、話はシンプルで、
文章の区切りや転換
をイメージしてもらえると、そこからガラッと話が変わることがありますよね。
つまり、そういう状況ではz → 1に近づきます
これが

です。
つまりz というのは隠れ層hをどのくらい更新するのか?(過去を織り交ぜる?いらない?)ということを指します。
一つの数式でも定義と、それが意味するものがわかればなんかこの数式が文章のように思えてきませんか?(私だけでしょうか。)
では、次にいきます。
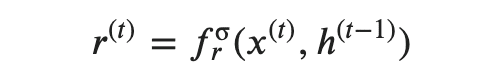
この r が何を考えるために、その下の式をみてみると
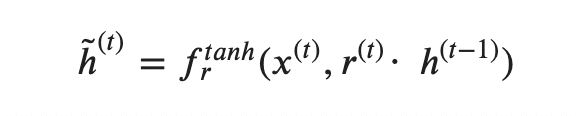
この式でr = 0 を考えると r • h_(t-1) -> 0 となり、h'_t = f_tanh(x, 0)となります。
つまり入力にはほとんど以前までの情報を保持しないことを意味します。
反対に r= 1であれば、xとh_(t-1)を両方台頭に考慮しますよ〜みたいな感じです。
r を使うのはh'を決める前に、sigmoidでxとh_(t-1)で算出しておきます
では、(避けてきた)h' って何?と言われると、
h_t を作る時にh_1 をmixし、さらにxの情報も保持して隠れ層を更新するためのものです。
・・・
大体こんな感じです。
つまり、長々と書きましたが、GRUにより以前の記憶をどの程度保持(もしくは忘却)するのかを制御することで長期的な記憶を持つようになるんですね!
ここでほとんどGRUの概論理解自体はおけだと思うのですが、参考書をみると癖の強いアートみたいな図が出てきます。

おそらくここまできている方は単に4つの式を単に書いているだけなんだなと理解できると思いますが、最初にみてもなんじゃいなってなっちゃいますね。。
・Simple RNNを実装してみる
理論ばかりでは疲れる(?)と思いますので、実装の方をしてみましょう。
今回からtensorflowを使いますため、colaboratory上で行おうと思います。
(めちゃくちゃ重い処理をするわけでもないですが、一応。)
先にtensorflowを使えるようにするため、以下のコマンドをコマンドラインやターミナルで実行をお願いしまする。(既にインストール済みであれば飛ばしておけです)
!pip install tensorflow
!pip install tensorflow-gpuちなみに、自分もtensorflow熟練者でもなんでもないので拙い説明になることをご了承くださいませ。(ちなみに、いつになるか不明ですが、tensorflow基礎というのも投稿したいです。)
では、まずはコードから。
import tensorflow as tf
tf.random.set_seed(1)
rnn_layer = tf.keras.layers.SimpleRNN(units=2, use_bias=True, return_sequences=True)
rnn_layer.build(input_shape=(None, None, 5))
w_xh, w_oo, b_h = rnn_layer.weights
print(f'W_xh shape: {w_xh.shape}')
print(f'W_oo shape: {w_oo.shape}')
print(f'b_h shape: {b_h.shape}')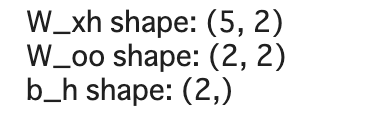
次に一つずつ解説して行きます。
今回のSimpleRNNの公式ドキュメント。(keras単体ならこちら)
tf.keras.layers.SimpleRNN(
units, activation='tanh', use_bias=True,
kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal',
bias_initializer='zeros', kernel_regularizer=None,
recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, recurrent_constraint=None, bias_constraint=None,
dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False,
go_backwards=False, stateful=False, unroll=False, **kwargs
)
tensorflowの公式ドキュメントは割とみやすいかな〜と思いますが、ちょこちょこと説明します。
units: 出力層の次元数を指定
activation: 活性化関数の指定(=Noneなら、f(x)=x)
use_bias: バイアスvectorを加味するかどうか
~_initializer: ~を初期化するか、もしくは何を初期値として指定するか
~_regularizer: ~を標準化する関数の指定
~_constraint: ~を制限(non_neg 非負など)するような関数を指定
return_sequences: sequenceを全て返すか、最後のみを返すか
残りは割愛
いろんなサイトを見た限り、return_sequences=Trueは結構お決まりだったりします。
これにより、RNNのリカレント(出力)層を出してくれます。
次に、buildするためにinput=(a, b, c)として[バッチ次元(バッチの中のデータ数), sequenceの次元、特徴量の次元]で指定します。可変である時はNoneを指定します。
どちらかといえば、Sequentialを使った例をよく見かけます.
なので、ちょっとだけ触れておきましょう
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
tf.random.set_seed(111)
model = Sequential()
model.add(SimpleRNN(units=2, input_shape=(None, 5), return_sequences=True))
model.add(Dense(2, activation='linear'))
model.compile(loss='mean_squared_error', optimizer='sgd')
print(model.summary())
このnoteではまだtensorflowのことをしていないため、何がなんやら。。っていう方もいると思うのですが、一旦は飛ばしても大丈夫です。
tensorflowは自然言語のガッツリとした分析前にちゃんと投稿しよう(自分が勉強しよう)と思っているので、今は理論をふんわり理解してもらえればと思います。
・LSTM・・の前に一旦区切り
RNNにはLSTMという山場とseq2seqなどまだまだ理論や実装がてんこ盛りなのですが、長くなってきましたので、一旦区切ります。
次回は100本ノックの6, 7章を扱うか、LSTMか、tensorflow基礎にするかにします。
では、また次回もよろしくお願いします。
この記事が気に入ったらサポートをしてみませんか?