
arXivを用いた研究プレイヤーの調査手法 - LLM関連論文を例に

はじめに
arXivに登録されているLLM関連論文を調査した論文が公開されました(Topics, Authors, and Networks in Large Language Model Research: Trends from a Survey of 17K arXiv Papers)。調査内容・結果の詳細は、下記のAIDBの記事が参考になります。
もしarXivについてあまり知らない方がいれば、以前、下記のようなnoteを書いたので、ご参考にしていただければと思います。
話を戻します。この調査論文は内容もさることながら、arXivを用いた調査手法も参考になります。データやコードも公開されているので、実際に触ってみると良いでしょう。このnoteでは、その手法に着目して紹介したいと思います。
ちなみに、この論文で収集したLLM関連論文は、下記のキーワードがタイトル・アブストラクトに含むものです。2018年以降のもので、16,979件ヒットするようです。
"language model" OR "foundation model" OR BERT OR XLNet OR GPT-2 OR GPT-3 OR GPT-4 OR GPT-Neo OR GPT-J OR ChatGPT OR PaLM OR LLaMA
では、この論文では、どんな調査の工夫がされているでしょうか。大きな調査フローは下記の通りです。
要約情報から二次元可視化&クラスタリングして、各クラスタにラベルをつける。そのラベルを用いて、技術動向を追う。
組織名は、論文本文PDFから抽出している。具体的には、最初の100行からメールドメインを取得して推定している。
被引用数はSemantic Scholarを利用して取得している。
オープンソースツールを使って、著者名から性別推定をしている。
ちなみに、3のSmantic Scholar APIを使って被引用数を取得する方法としては、下記の記事が参考になります。また、4については、nomquamgenderというツールを使って、著者名から性別推定をしているようです。
arXivにおけるプレイヤー調査の工夫
このnoteでは、特に2. プレイヤー調査手法について詳しく見ていこうと思います。実はarXiv APIで取得できるデータの中には、所属機関名がありません。いや、正確には、affiliationという情報があるのですが、ほとんどデータが空白なので使い物になりません。論文や特許等を調査していると、どうしてもプレイヤーの動向は追いたくなります。ただ、arXivではその情報が取得できなかったので、プレイヤー動向を調査しにくい点が問題でした。しかし、このLLM調査論文では、下記のようなプレイヤー集計結果が掲載されています。

この集計グラフはどのように作成されているのでしょうか?公開されているコードを見ると、下記の要領で実施しています。
論文PDFの最初の100行から、メールドメインを正規表現で抽出する。例えば、1つのメールアドレスであれば「'[\w.-]+@[\w.-]+.[a-zA-Z]{2,}(?!\d)'」、複数のメールアドレス({author1, author2}@domainパターン)であれば「'{[\w.,| ]+}@[\w.-]+.[a-zA-Z]{2,}(?!\d)'」 という正規表現で取得している(preprocess_utils.pyのget_all_emails関数を参照)。
メールドメインの件数を集計し、上位50を組織名に変換して棒グラフ化している(affiliation_analysis.ipybを参照)。ドメインから組織名への変換はdomain_to_abbreviated_nameで登録されている辞書を適用している。この辞書は、おそらく上位100ドメインと一部有名組織のドメインについて、手作業で組織名を対応付たものだと考えられる。
メールアドレスを取得するという方法は、NISTEPの調査「研究活動におけるオープンソース・データの利用に関する簡易調査」でも実施されています。そこでは、組織名を特定するというよりは、ドメインの国名を見て、国別動向を調査する目的でした。詳細は、下記のnoteでも書いたので、興味ある方はご覧ください。
本プレイヤー調査手法の注意点
このように、本来であれば、論文PDFから組織名を直接抽出できれば良いのですが、表現パターンが多いため、ここでは表現のブレが比較的少ないメールアドレス抽出をしたのだと思います。とても良いアイデアだと思うのと同時に、注意点がいくつか考えられます。
1つの組織で複数ドメインがある可能性があるから、プレイヤー集計するときは、ドメインで集計した結果をそのまま使ってはいけない。ドメインを組織名に変換した後に、その組織名で集計しないといけない。
ドメインから組織名に変換する効率的な手法はあるか。
メールアドレスを取得できなかったものは、何かしら組織名らしいものを抽出するなどの工夫が必要である。
注意点1についてですが、実際、この論文で提示されているプレイヤー上位50者は不正確な部分がありました。例えば、トロント大学には、toronto.eduとutoronto.caの2つのドメインが存在しています。この2つのを合わせて集計すると93件となり、オックスフォード大学と同じ位置にランクインすることになりますが、元々のランキングでは上位50には入ってきていません。

次に、注意点2についてですが、本論文ではドメイン上位100プラスα(OpenAI等)について、ドメインと組織名の対応辞書を用意しています。おそらく、手作業で辞書を作ったのかと思います。

では、100位より下位のドメインについては、どうすれば良いでしょうか。手作業で人間がやっていくのも限界があります。こういうときこそ、ChatGPTに頼ってみるのも良いかもしれません。

日本のプレイヤー調査
以上が、本論文で提案されているプレイヤー情報の抽出・集計手法でした。プレイヤー集計結果を見て、日本にいる皆さんは、「日本の組織がいない」と思ったのではないでしょうか。せっかくデータが公開されているので、日本の組織も見てみましょう。

上位10は、東大、京大、東北大、NII、理研、東工大、NAIST、早稲田、NTT、阪大です。民間企業だと、NTT、Studio Ousia、サイバーエージェント、KDDI、ホンダ 、KDDI、PFN、ブレインパッド、東芝、Rist、NHK、Fast Accounting、NTTデータ、デンソー、レトリバ、リクルート、NRIが存在します。
例えば、Hondaでは、Collaborative Storytelling with Large-scale Neural Language Models、DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Modelsといったストーリーテーリングや音声モデルに取り組んでいます。また、ブレインパッドでは、Inductive-bias Learning: Generating Code Models with Large Language Modelといったコードの生成モデルについて研究しています。
なお、日本の組織を判定するのに、ドメインにjpが含まれているものを全て組織名に変換して、その組織名で集計しています。ですので、ドメインにjpが含まれていないものは集計から漏れている可能性がある点はご留意ください。ちなみに東大のドメインは「u-tokyo.ac」となっており、jpが抜けていましたが、発見できたので集計に含めています。
より正確に集計するには、全てのドメインを組織名に変換する辞書を作れば良いですが、そう簡単では無いと思います。その場合、「ドメインにjpを含むものを組織名に変更」→「組織名で集計して、それらの組織でjpがつかないドメインがないか調査」→「もしあればその分も組織名に変換して再集計」、という作業を実施した方が良いでしょう。
企業のプレイヤー調査
企業に絞って集計した上位 20を下記に示します。米国、中国の企業が多く存在しています。Naverやサムスンといった韓国勢も存在します。Appleもランクインしており、Unified Vision and Language Prompt LearningやPopulation Expansion for Training Language Models with Private Federated Learning、Gender bias and stereotypes in Large Language Modelsといった視覚・言語学習、言語モデルの連合学習、LLMにおける性別バイアス・ステレオタイプの把握等に取り組んでいます。
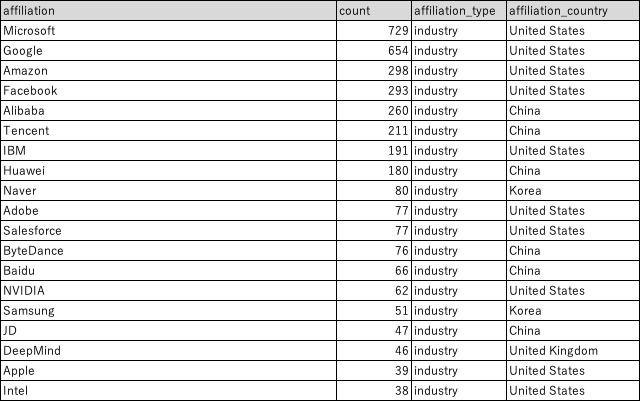
なお、こちらの集計結果は、ドメイン上位100プラスαと日本ドメインを組織名に直して集計した結果です。抜け漏れの可能性はあります。
さいごに
こういった調査論文は、調査結果もさることながら、手法自体も大変参考になります。特に今回の論文では、コードやデータを公開していただいているので、読者も動かすことができて勉強になります。私も、こういった調査手法の発展に貢献したいと思いました。
参考に、日本のプレイヤー情報も追加したデータを下記に掲載します。affiliation_nameカラムは、domainsから上位100ドメインと日本組織ドメインを組織名に変換したものです。affiliation_countryカラムは、それらの組織の国情報を追加したものです。他のカラムは、公開されているデータから抽出したものです。
また、affiliation_nameを集計した結果も掲載します。全てのドメインを組織名に直して集計したわけではないので、抜け漏れはあると思います。参考情報としてご覧ください。