
NISTEP(科学技術・学術政策研究所)の調査研究におけるChatGPTの活用アイディア

NISTEPの調査報告書は面白い
2023年1月、NISTEPから「研究活動におけるオープンソース・データの利用に関する簡易調査」の報告書が公開された。この調査では、arXivでのオープンソース・データの言及回数を調査している。結果としては、githubは緩やかな増加傾向にあるが、figshareやZenodoは少なく、これらを通じたデータ共有・活用はまだ普及していないことを明らかにした。
下記グラフはgithub言及原稿数の国別動向である。このグラフを見て違和感を感じる方もいるだろう。凡例を見て分かる通りUSが明示されていないのである。この点については後で触れる。
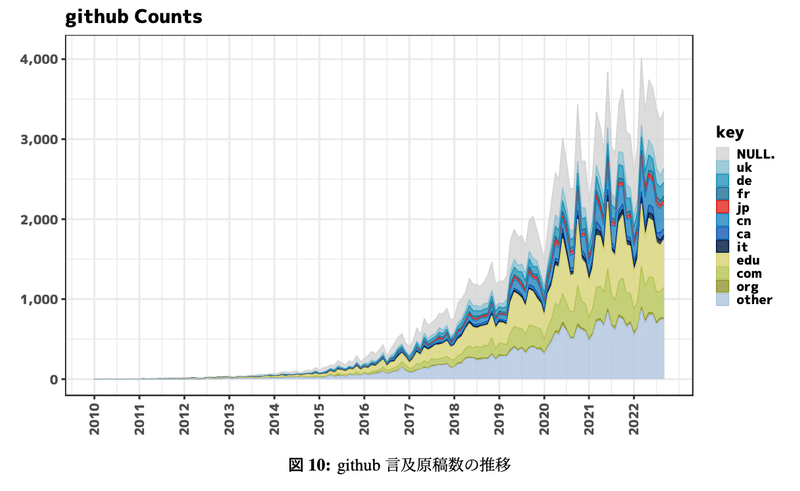
本調査では、英国と日本の差について詳細に記載しており、英国ではgithubに言及している投稿原稿は3割弱であるのに対して、日本ではまだ1割程度である。お互いの時系列推移を比較すると、2022 年 9 月の日本のステータスは、英国の41 ヶ月前の 2019 年 4 月の状況に相当し、英国に約3年半後れをとっていることが分かった。

このように、NISTEPの調査研究は、日本と世界の科学技術・研究開発動向について、参考になる情報を発信している。
データ処理の観点でも参考になる
普段から調査分析を行っている人にとっては、このような調査研究で行われている手法も参考になるだろう。前述した通り、本調査研究ではarXivの国別動向を調査している。しかし、arXivから取得できるデータには国情報はない。組織情報も取得はできるが空白であるケースが多い(arXiv APIを用いたデータ取得方法は下記noteにまとめている)。では、NISTEPではどうやって国別動向を調べたのか?
その手法は報告書の「2.3節 データ」に下記のように記載されている。
■国籍の割り付け
国籍は先行研究を参考に,原稿 PDF からテキスト抽出した後,テキスト中に出てくる最初のメールアドレスをベースに,そのトップレベルドメインに基づいて割り付けることにした。 したがって,研究者の国籍ではなく,あくまで所属機関の国籍であって,かつ,著者全員ではなくテキスト解析上最初に検出されたメールアドレス 1 件のみである点に注意が必要である。
さらにこの際,「XXX.com」のようなものについて whois 情報から国籍を割り付けることはしない。 メールアドレスはアットマーク (@) をベースに検出するため,「XXX[.at.]XXX.XX.XX」のような形式の場合は検出できない。 米国は国を示すトップレベルドメインを用いないので,基本的には検出されない。 トップレベルドメインにおける国名 (ccTLD) は基本的には ISO 3166 に準じるが,英国は .uk を用いるなど例外がある。また,本報告書では簡単ため「国籍」としているが,ISO 3166 は「.hk(香港)」 など地域も含む。ccTLD 以外のものは原則として国籍不明 (NULL) とするが,「.com」「.edu」「.org」の 3 種類は参考情報として残す。
つまり、API等で取得できる書誌情報ではなく、原稿PDFからメールアドレスを検知して国情報を抽出しているのである。この方法の制約についてを改めてまとめると下記のようになる。
はじめに出現するメールアドレスだけを対象に国を抽出しているため、複数著者がいる場合は、他の国が漏れる可能性がある。
メールアドレスは@で検出しているので、[at]と書かれている場合は検出できない。
米国はトップレベルドメインを使わないので、明示的に検出することが出できない。
このような制約を克服できる方法はないのであろうか?
ChatGPTを使った国情報抽出のアイディア
著者や所属機関情報は、投稿原稿PDFの1ページには掲載されていることが多いであろう。そこで、PDF1ページ目をテキスト化し、それをChatGPTに読み込ませて、著者名・所属機関名・国名を抽出するようにプロンプトを打てば良いのではないか。例えば、"A phonon laser in the quantum regime"を事例に試した結果を下記に示す。著者名・所属機関名・国名、いずれもうまく抽出できていることが分かる。おそらく、NISTEPの方法では、はじめに出てくるメールアドレスである***@phys.ethz.chを検出し、スイス(ch)と判定することになるが、実際はスイスと米国の共著である。

まだ少しの事例でしか試していないが、どれもうまく抽出できていた。ただし、100%全てうまくいくことはあり得ないので、上手くできないケースも発見し、それを解決するプロンプトエンジニアリングも必要であろう。この方法の課題としては下記のようなことが考えられる。
大量のデータで試した時、どのくらいの精度なのか定かではない。
一般的に論文で著者や所属組織名が書かれている箇所以外に組織名が出現するケース。例えば、アブストラクトやイントロダクション中に、著者自身の所属機関ではなく、他の機関名が出てくる場合、それを著者の所属機関として認識してしまう可能性がある(Goolgeが作ったX modelを利用した等の表現)。
このようにChatGPTをうまく活用することで、データ処理が効率化されるだけでなく、これまで一定のルールーベースロジックでは難しかった処理もできるようになる可能性を秘めている。是非、NISTEPには、調査研究の中で、このようなAIを用いた新しいデータ処理も実験し、報告書を公開していただけることを楽しみにしている。