
データの事前処理

Tableau DATA Saberの第一の技術力の試練の復習も兼ねて、Tableauの基礎を複数回に分けてまとめていこうと思います。
まずはデータの事前処理について。
データを分析する以前に大事なことがあります。それはデータが使える状態になっていること。これがちゃんとできていないと当たり前ですが分析ができません。
データをつなげる
複数のデータをつなぐ方法として結合とブレンドがありますが、2つの大きな違いは集計が実行されるタイミングです。
結合 … データが組み合わされる → 集計される
ブレンド … データが集計される → 組み合わされる
もう少し詳しく説明します。
<結合>
2つのデータソースに共通するカラムを指定して1つの表として結合することです。Tableauではデータソース画面で結合の種類を選択できます。

以下のサンプルデータテーブルを例に解説します。仮にテーブルデータAとBをユーザーIDで結合したい、とします。

内部結合
両方のテーブルに一致する値を含む行でテーブルが作成される

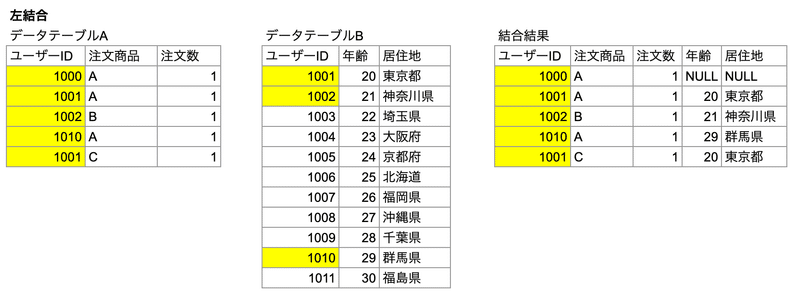
左結合
左のテーブルの全ての値を含む行でテーブルが作成される
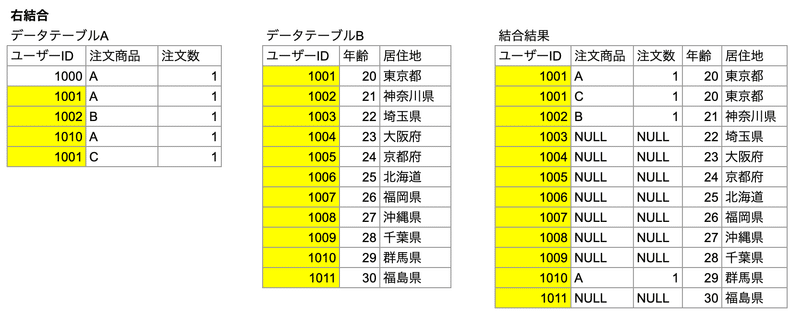
右結合
右のテーブルの全ての値を含む行でテーブルが作成される
完全外部結合
両方の全ての行でテーブルが作成される

<ブレンド>
結合とは別のやり方で、複数のソースからデータを組み合わせる方法のひとつとしてブレンドがあります。プライマリ(一番優先される)データを基準に、セカンダリデータから追加情報が取り込まれます。左結合のイメージです。
冒頭に記載したとおり、ブレンドは結合とは異なり、何かしらの集計がされた結果としてデータが組み合わされます。ですので、結合のようなテーブルはつくられません。

結合とブレンドそれぞれ違いがありますが、じゃぁどっちを使えばいいの?と言うと、データの粒度が異なる場合はデータブレンドの方が良い、というのが公式の見解です。確かに、粒度が異なるものを無理やり結合するとよくわからないテーブルになってしまいそうです。
関連付け
ブレンドしたときに、データがうまく紐づかないときは、解決方法の一つとして簡単な方法があります。
以下はTableau DATA Saber学習用のサンプルデータですが、”サンプルスーパーストア”と”Maker”のテーブルを利用したいとき、製品のIDをキーに紐づけをしたいが、データの名称が”製品ID”と”製品id”で異なりTableauは自動では同じデータだと認識してくれません。そのとき同じ名称に整えることでTableauが自動でリレーションシップを作成してくれ、リンクアイコンが表示されます。
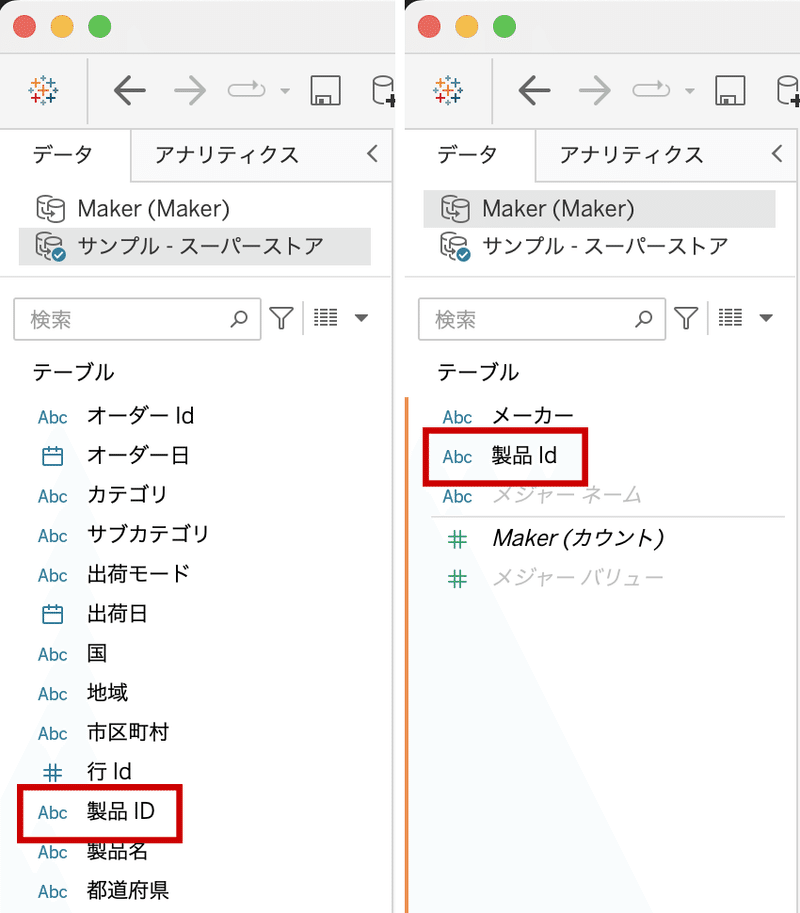
以下のように”Maker”のテーブルの”製品id”を”製品ID”に修正することでリンクマークが出て紐づけができました。
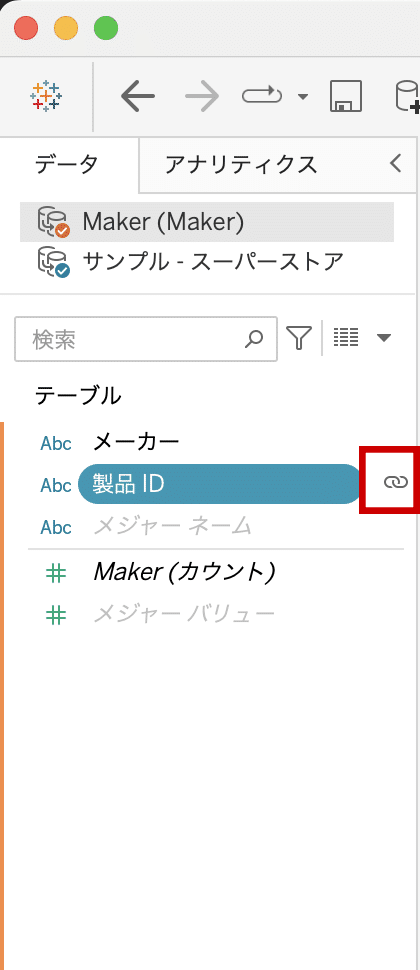
もしくは、データソース画面からリレーションシップの編集ができます。

データを整える
データの型を整える
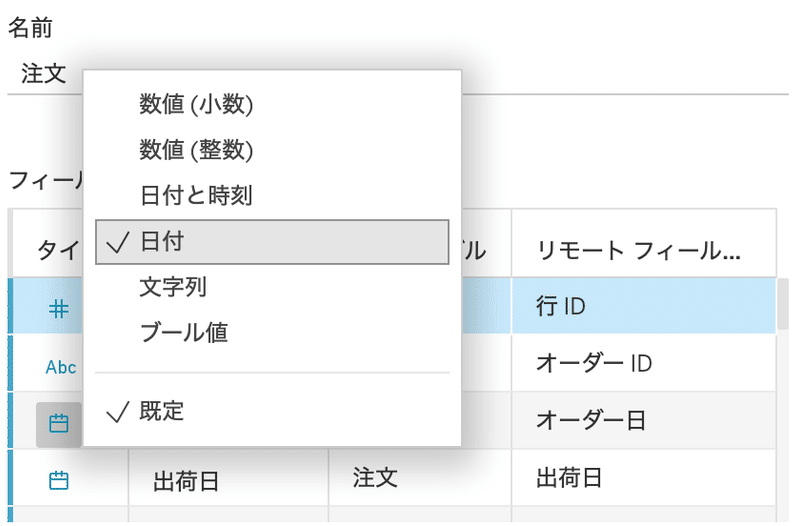
データの型とは、数値、日付(時刻)、文字列、成否、地理的役割などを指します。
このデータ型が整っていないと思ったような分析ができないので注意です。
Tableauでは、データソースの画面からデータの型(タイプ)を変更することができます。

データを分割する
データ型の変更だけではうまくいかないこともあります。
例えば、製品ID情報から製品のカテゴリを抽出するために、データを分割したいとき、Tableauでは簡単に分割ができます。
分割したいデータを右クリックもしくは右側の▼をクリック>「変換」>「分割」もしくは「カスタム分割」をクリックします。(今回は「カスタム分割」を選択します)
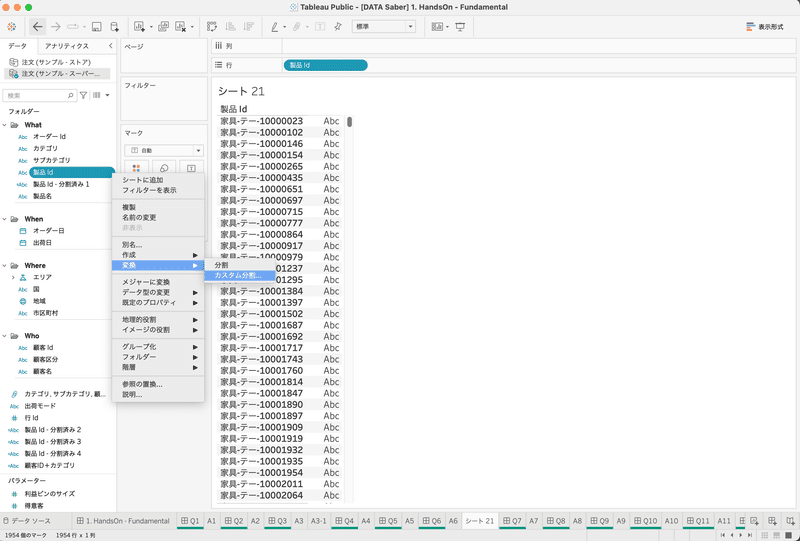
「カスタム分割」を選択するとどう分割するかを設定できます。

今回は区切り文字を「-」ハイフン、分割を「最初」「1列」で設定します。

すると、「製品id - 分割済み 1 」のデータが作られ、中身を見ると「製品id」の最初のハイフン前のデータで分割されていることがわかります。

他にもデータを整える方法はたくさんありますが、一旦ここまで。
エンジニアやデータサイエンティストなど普段からテーブルに触れている方にとっては基礎的な内容だと思いますが、直接テーブルに触れない私のような人にとっては分析の大前提となる学びでした。
この記事が気に入ったらサポートをしてみませんか?