
Tableau2022.3 テーブル拡張機能で形態素分析をやってみた

Tableau 2022.3の新機能、テーブル拡張機能を紹介します。
TableauとPython、R、Einstein Discoveryと接続してデータを変換したり前処理したりして高度な分析が可能になりました。
今までは、行レベルで変換することは可能でしたが、今回テーブル自体を変換できるようになりました。
今回は、岸田首相の記者会見内容をテキストとして入力し、そのテキストに出現する単語をPython/MeCabで出現回数を計算し、Tableauで可視化します。
Tableau2022.3のテーブル拡張機能を試してみました。
— ハラヨワ | Harayowa (@jito60261993) October 27, 2022
岸田首相の記者会見テキストをPython/Mecabで単語の出現回数を計算、Tableauで可視化。
左:入力データ、ただのテキスト(1行1列)
右:表拡張機能を使ってデータフレームにしたのを可視化#tableau #python #TableExtensions #MeCab pic.twitter.com/ng9MyIvvQi
準備
Tabpyを立ち上げます。
*インストールがまだの方は以下を参考にしてください。
Tabpy - Tableau + Python 連携 を使ってみよう!(その1:Tabpy導入編)
Tabpyとは?コンセプトやメリット、インストール方法まで解説
入力データ

*以下は、どうやって作ったかです。読み飛ばしてOK。
岸田首相の記者会見テキストは以下からコピペ。
Tableauに読み込ませるために少し前処理が必要で、
・改行を消す(改行を残すとTableauで行として認識されます)
・列名を加える(ここでは”内容”としました)
テーブル拡張機能
1. いつも通り、Tableau Desktopを開き、上記データに接続

2. 元のファイルを削除してから、左のペインからテーブル拡張機能を右にドラッグ&ドロップ
削除
「新しいテーブル拡張機能」をドラッグ&ドロップ(もしくはダブルクリック)


3.入力データを「テーブル拡張機能」にドラッグ&ドロップ

4.スクリプトに以下を貼り付け
import pandas as pd
import collections
import MeCab
def getWords(text):
tagger =MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
word_list=[]
while node:
word_type = node.feature.split(',')[0]
if word_type in ["名詞",'代名詞']:
word_list.append(node.surface)
node=node.next
word_chain=' '.join(word_list)
c = collections.Counter(word_list)
return c
df = (pd.DataFrame(_arg1))
text = df['内容'][0]
c = getWords(text)
d = c.most_common()
dff = pd.DataFrame(d)
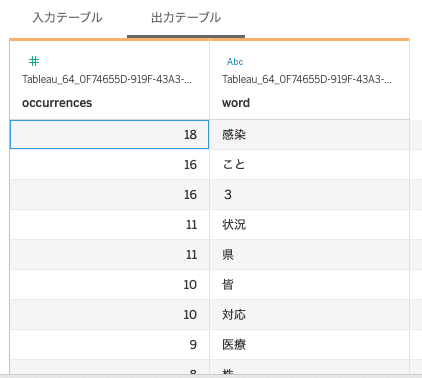
dff.columns = ['word', 'occurrences']
return dff.to_dict(orient='list')スクリプトは以下のブログを参考にしています。
https://python-man.club/python_morphological_analysis/
TabPyの注意点は、
・入力は、df = (pd.DataFrame(_arg1))
・出力は、dff.to_dict(orient='list') で辞書型
にする、です。
4.「適用」をクリックすると、データが出力される

下部ウィンドウの出力テーブルで、作成したデータフレームを見ることができます。
5.Tableauで可視化
ワークシートに移動。
wordをテキストに、occurencesを色とサイズに入れる。
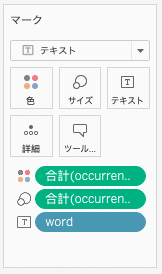
列と行には何もいれなくていいです。
すると以下のように見えるはずなので、これで完成です。

この記事が気に入ったらサポートをしてみませんか?