
ざっくり株価予測 データ取得、処理から機械学習までひととおりやってみる

今回使うライブラリ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from pandas_datareader import data as pdr
import seaborn as sns
sns.set()
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.layers import Dropout
from keras import losses
import sklearn.preprocessing as sp
from sklearn import preprocess・データ取得から処理まで
・データ取得
yf.pdr_override()
df = pd.DataFrame()
code = '9984.T'
start = '2021-01-05'
end = '2021-06-29'
df = pdr.get_data_yahoo(code,start=start,end=end)pandas_datareaderを使うと簡単に株価がダウンロードできます。
1:yahoofinanceのapiを使うためにyf.pdr_override()でpandas_datareaderをオーバーライドします。
2:表形式のデータが返ってくるので、変数df (data_frameの略)にpd.DataFrame()として、返されたデータをpd.DataFrameに対応した形で保存します。あとでデータを色々いじくるのですが、pd.DataFrameはいじくりやすいのでこの形にしています。どういう意味か例えるなら、音楽データをCDに書き込むかカセットテープに書き込むかみたいな選べるものだと思ってもらえれば大丈夫です。
3:変数 code に文字列で'9984.T'と指定します。9984がソフトバンクの証券コードでドットTのTは東証のTです。他の証券コードにしておけば後でデータを取得するとき、別の企業の株価も取得できます。
4:変数 start と変数 end に取得したい期間を文字列で指定します。ここでは2021年の1月5日から2021年の6月29日までとしています。年始は取引がなくてデータがいいかげんなので1月5日からにしています。
5:さっき表計算がしやすいようにとpd.DataFrameの形にした変数 df にpdr.get_data_yahoo(code,start=start,end=end)としてデータをダウンロードします。カッコ内のcodeとかstartにはさっき指定した変数が入ります。('9984.T',start='2021-01-05',end='2021-06-29)になります。

こんな感じのデータがとれました。日足のデータで、Closeがその日の終値でVolumeは出来高です。あとは高値とか安値とかも入っていますね。
plt.plot(df['Close'])plt.plot(表示したいデータ) でグラフの作成ができます。さっきダウンロードしたデータは変数 df に入っていてその中の'Close'を指定することで、終値がグラフで可視化できます。
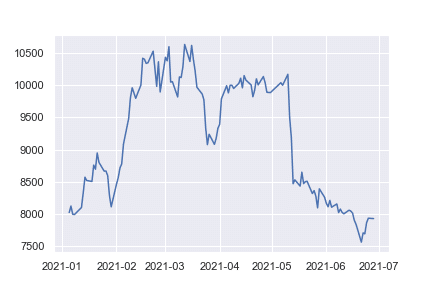
縦軸が終値で横軸が日付になっています。指定した期間でデータがちゃんととれているようです。
・テクニカル指標を追加する
テクニカル指標を追加するための関数を書いていきます。
def sma(df,window):
df['SMA' +str(window)] = df['Close'].rolling(window=window).mean()
df['Moving_average_divergence' +str(window)] = 100.0 *(df['Close'] -df['SMA' +str(window)]) /df['SMA' +str(window)]
return dfdef から始まる文で自分で関数を作れます。ここではSMA(単純移動平均:Simple Moving Average)を計算する関数を書いています。
pd.DataFrameは色んな計算が簡単にできるようになっているので複雑な計算式をかなり簡単な文章に落とし込めるようになっています。なので関数に渡す変数もdf(pd.DataFrame)とwindow(移動平均を取る日数)だけで大丈夫です。
df['SMA' +str(window)] = とすることで、もとのpd.DataFrameに新しい列 'SMA(何日)' を追加できます。イコールの先に移動平均の計算式を書くとその行に計算結果が追加される仕組みです。
イコールの先df['Close']はさっきダウンロードしたデータの終値ですね。rolling(window=window)で指定した日数分の終値データをひっこぬいてくれます。最後のmean()でひっこぬいたデータの平均を計算します。これはそのまんま移動平均の計算式ですね。
その下のdf['Moving_average....の文は移動平均乖離率の計算式です。
関数ができたらさっそく使ってみます。
df = sma(df,7)smaという名前で作った関数にdf(自分自身)と7(移動平均の日数)を渡してあげると、関数の中の計算をしてくれて結果が返ってきます。

SMA7という列が増えていて、計算結果が各行に書き込まれています。7日移動平均は、7つの時系列データがそろって初めて最初の数値を計算できるので、上から6番目まではデータなし(NaN)になっていますね。
def macd(df):
FastEMA_period = 12
SlowEMA_period = 26
SignalSMA_period = 9
df['MACD'] = df['Close'].ewm(span=FastEMA_period).mean() -df['Close'].ewm(span=SlowEMA_period).mean()
df['Signal'] = df['MACD'].rolling(SignalSMA_period).mean()
return df
def rsi(df,window):
df_diff = df['Close'].diff(1)
df_up, df_down = df_diff.copy(), df_diff.copy()
df_up[df_up <0] = 0
df_down[df_down >0] = 0
df_down = df_down *-1
df_up_sma = df_up.rolling(window=window,center=False).mean()
df_down_sma = df_down.rolling(window=window,center=False).mean()
df['RSI'+str(window)] = 100.0 *(df_up_sma /(df_up_sma +df_down_sma))
return df
def sigma(df,window):
df_mean = df['Close'].rolling(window=window).mean()
df_std = df['Close'].rolling(window=window).std()
df['sigma' +str(window)] = (df['Close'] -df_mean) /df_std
return df同じ感じでMACDとRSIとシグマを計算する関数も作っていきます。
df = sma(df,7)
df = sma(df,14)
df = sma(df,24)
df = macd(df)
df = rsi(df,7)
df = rsi(df,14)
df = rsi(df,24)
df = sigma(df,7)
df = sigma(df,14)
df = sigma(df,24)全部同じpd.DataFrameに書き込んでいきます。これでもとの表に色々なテクニカル指標が書き込まれました。もうひと処理加えて機械学習にかけていきます。
今作った表にはいろんな大きさの数字が書き込まれています。終値と7日移動平均から計算したシグマの数値を表示してみます。

縦軸がシグマで横軸が終値ですね。シグマの値は-2~+2の間で分布していて、終値の値は7500~10500円ぐらいの間で分布していることがわかります。

例えば、○○日後株価が下がったグループと株価が上がったグループでグループ分けをしたとします。上の画像のような線を引いて、線より上が○○日後株価が下がったグループ、線より下が逆に株価が上がったグループみたいな感じで分けたいとします。

でも、データの数字のスケールの違いで実際の空間ではこんなデータの分布になっていて、うまく線引きができません。シグマの値が-2~+2の間に収まっているせいで、株価みたいな4ケタ、5ケタの数字のデータと一緒にするとちぢこまって区別がつかなくなってしまいます。
なので、各データの数字をまるごといい感じの数字の範囲内に収めてあげます。これを標準化といいます。
#正規化
def mean_norm(df_input):
return df_input.apply(lambda x: (x-x.mean())/ x.std(), axis=0)pd.DataFrameをまるごと標準化する関数です。
#使う行
use_cols = ['SMA7','Moving_average_divergence7',
'SMA14','Moving_average_divergence14',
'SMA24','Moving_average_divergence24',
'MACD',
'RSI7','RSI14','RSI24',
'sigma7','sigma14','sigma24']標準化したい行をまとめて、
n_df = mean_norm(df[use_cols])新しい変数n_df(norm_dataframeの略)に保存します。データがどうなったか見てみましょう。
plt.plot(df['SMA7'])標準化前のDataFrameのSMA7を表示します。

縦軸の値が8000から10500の間に収まっていますね。横軸は日付です。
標準化後のSMA7も見てみます。
plt.plot(n_df['SMA7'])
グラフの形がおなじなのに、縦軸が-1.5から1.2ぐらいの値に収まっているのがわかると思います。ほかのデータも同じ感じになっているので、全部ごちゃまぜにしても線引きが簡単にできそうですね。
・訓練データと正解データ作り
正規化が終わったところで、機械学習にかけるために、訓練データと正解データを作っていきます。今回は今作った表から、10日分ずつデータを抜き出して学習用のデータとして、その10日分のデータの最後の終値から3日後の終値がどれくらい上昇、下落したのかを正解データとして、最後に学習を進めていきたいと思います。

10日分の色んなデータのイメージ。3つだけ表示しています。

入力した10日分のデータから3日後の株価を予測していきたいと思います。
docx, docy = [],[]
n_prev = 10
n_df = n_df[30:]
for i in range(len(n_df) -13):
#0->30行目までの使用するデータ
docx.append(n_df.iloc[i:i+n_prev][use_cols].values)
#3日後の株価の増減率
docy.append(100.0 *(n_df.iloc[i+13]['Close'] -n_df.iloc[i+10]['Close']) /n_df.iloc[i+10]['Close'])1:空のリスト docx とdocy を作成します。docx には10日分のデータを表から取れるだけ、docy には実際に株価がどの水準になったか、といったいわゆる正解データを入れていきたいと思います。
2:n_prev = 10 として、変数n_prevに数字の10を格納します。
3:n_df = n_df[30:]とすることで、標準化したpd.DataFrameの最初の30行をスキップします。これは上で24日単純移動平均などのデータをいれているのですが、計算の都合上最初の24日分にはデータなしとなっているので、雑に最初の30日を削って全部のデータがきちんとそろっている状態にするためです。
4:for i in range(len(n_df -13): として、ループ処理をn_dfの行マイナス13回分繰り返します。具体的にはfor i の i に0から75までの数字が順番に代入されて、下の処理の部分の i に送られます。
5:docx.append()とすることでカッコ内のなんらかのデータが、空のリストdocxに追加されます。
カッコ内の説明です。 n_df.ilocとすることでn_dfから [ ] 内の場所を探して抜き出します。ここで、 [ ]は i : i+n_prev となっていますね。i はループ処理でまず0が代入されて、0 : 0 +n_prev となり、n_prevは最初に指定した変数n_prevから数字の10が代入されて最終的に 0 : 10となります。これでn_df.iloc[0:10]となり、DataFrameの0行目から10行目までを抜き出せます。次のカッコ[ use_cols ]はちょっと上のほうで指定した使いたい行の使いまわしですね。一緒につけると0行目から10行目の使いたい行だけを抜き出します。最後の.valuesで抜き出した表から数字を抜き出します。
docy.append()とすることでカッコ内のなんらかのデータが空のリストdocyに追加されます。
カッコ内n_df.iloc[ i +13 ]['Close'] で i に0が代入されて、13行目の終値を抜き出します。n_df.iloc[ i + 10 ]['Close'] で10行目の終値を抜き出します。
なのでカッコ内を文章にすると(13行目の終値マイナス10行目の終値)割る10行目の終値 ×100 になりますね。これは3日後の株価の増減率の計算式になっています。
これをループ処理で1行ずつずらしながらリストに追加していきます。
arrayX = np.array(docx)
arrayY = np.array(docy)出来上がったリストをnp.arrayの形で保存します。これもカセットに録音するかCDに録音するかみたいな話です。あとでいじりやすくするためです。
出来上がったarrayYを見てみましょう。arrayYはdocyをnp.arrayの形にしたものでしたね。docyには3日後の株価の増減率のデータが沢山入っているはずです。
plt.plot(arrayY)
3日後の株価の増減率はおおむね-5%から+5%のあいだで変動しているようですね。3日持っていたら-17%ぐらい下落したような日もあるみたいですね。大体の変化率はわかりましたが、このままでは正解データとして使えません。

中をのぞいてみると数値がかなり具体的でかつばらばらですね。今回予測して返ってくる答えを-3%,-2%,-1%,0%,+1%,+2%,+3%のなかでどの%になる確率がどれくらいあるのか?という予測を想定しているので、ちょっと加工していきます。
arrayY[arrayY <= -2.5] = -3
arrayY[(arrayY > -2.5) & (arrayY <= -1.5)] = -2
arrayY[(arrayY > -1.5) & (arrayY <= -0.5)] = -1
arrayY[(arrayY > -0.5) & (arrayY < 0.5)] = 0
arrayY[(arrayY >= 0.5) & (arrayY < 1.5)] = 1
arrayY[(arrayY >= 1.5) & (arrayY < 2.5)] = 2
arrayY[arrayY >= 2.5] = 31:arrayY[ ]でさっきのデータarrayYを指定しています。
カッコ内arrayY <= -2.5 とすることで、arrayYの中の数値が -2.5以下の部分を指定します。
イコール -3 とすることで、さっき指定した部分が全部-3に置き換えられます。
2:同様に2行目 arrayY > -2.5 & arrayY <= -1.5 とすることで、arrayYの中の数字-2.5より大きくて かつ -1.5より小さい数字を -2に置き換えています。
3:あとは同じ感じでばらばらの数字を何個かの決まった数字に置き換えてしまいます。
置き換えたあとのarrayYを見てみます。
plt.plot(arrayY)
-17%から+5%ぐらいまでの間でばらばらだった増減率が-3%,-2%,-1%,0%,+1%,+2%,+3%のどれかに置き換えられています。

-17%などの大きな数字を無視してしまっていますが、これで全ての値が-3%~+3%の7つのカテゴリーの内のどれかに所属するようになりましたね。ここで作った数字をワンホットエンコーダーにかけていきます。
enc = sp.OneHotEncoder(sparse=False)
arrayY = enc.fit_transform(arrayY.reshape(-1,1))
数字の形が横に7列の0と1だけの情報になってしまいました。7列というのがさっきカテゴリー分けしたときのカテゴリーの数ですね。1になっている部分が元の数字がどのカテゴリーなのかを表現しています。これをワンホットラベリング等と呼びます。
例えば1行目は0,0,0,0,1,0,0なのでカテゴリ5の+1%だったよ、という意味です。
これで、10日分の各テクニカル指標が入ったデータと、カテゴリ分けされた株価の増減率のデータができました。これを学習用のデータと、学習ができたかどうかのテストデータにわけていきます。
今作ったデータの内、90%を学習用に、残りの10%をテストデータにします。学習後の機械学習モデルにテストデータを与えて予測させることで、どれくらい正解できるのかをみていきます。
ntrn = round(len(arrayX) *(1 -0.1))
ntrn = int(ntrn)
ntrn
68今作ったデータarrayXの90%が何行なのか計算します。68とでたので、30行スキップした1月5日から6月29日までの10日ずつのデータの90%は68個です、ということですね。
X_train, y_train = arrayX[0:ntrn], arrayY[0:ntrn]
X_test, y_test = arrayX[ntrn:], arrayY[ntrn:]X_train を訓練データ、y_trainをその正解データ、X_testをテストデータ、y_testをテストの正解データにします。
arrayX[0: ntrn] でさっきの68が代入されてX_trainはarrayXのなかの0行目から68行目が指定されました。同様にy_trainはarrayYのなかの0行目から68行目のデータになっていますね。
arrayX[ntrn: ]とすることで、X_testには68行目から終わりまでのデータが入っています。残りの10%の部分ですね。y_testも同様です。
・機械学習モデルの構築と学習
hidden_dim = 128
model = Sequential()
model.add(LSTM(hidden_dim,input_shape=(10,13),stateful=False,return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(7))
model.add(Activation('softmax'))
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])ここが今回データを入れて学習させる脳みその部分になります。機械学習のモデルについても詳しく解説したいのですが、めちゃくちゃ文章が増えてしまうのでざっくり解説します。
model = Sequential()で以下にmodel.addで追加されるレイヤー(特別な計算をする関数みたいなものだと思って貰えれば大丈夫です)に対して上から順番に計算を流していくモデルとしています。
model.add(LSTM... でLSTMモデルという時系列データの学習がうまくできるレイヤーを追加しています。hidden_dimは上の変数hidden_dimから128が代入されて、隠れ層が128個あることを意味します。隠れ層を多くすると計算時間は多くなるものの、学習がより柔軟に行えるようになります。input_shapeには(10,13)と指定しています。入力データが(データ数,10日分,13個のテクニカル指標)の行列で出来ているのでこの数字になっています。
model.add(Dropout(0.2))として、上からの計算の流れを意図的に20%無効にしてしまいます。学習のやり過ぎで未知のデータに対する予測能力の低下を防ぐ効果があります。
model.add(Dense(7))として、出力を7つの数字にしています。正解データが-3%~+3%までの7つのデータだったので、同じ数の数字が出力されるようにしています。
最後にmodel.add(Activation('softmax'))として自身の最後に出力した7次元のデータの合計を1になるように変換します。今回このモデルは入力データをガチャガチャ計算して最終的に7つの数字の並びになるようになっています。ここで出てくる7つは-3%,-2%,-1%,0%,+1%,+2%,+3%のカテゴリのうちどれになる確率がどれくらいあるか?を想定していましたね。しかし、確率の合計は必ず1(100%)なのに対して、いま出てくる7つの数字は1を超えていたり、1より少なかったりします。それでは確率としてとらえられないので、最後にこのソフトマックス関数と呼ばれる関数に通します。

ソフトマックス関数の数式はこんな感じ。
S はこれはソフトマックス関数ですみたいな意味です。カッコ内のyiをソフトマックス関数にいれると、その次のイコールの先の計算式が返ってきますよ、という意味です。分子のほうのeはネイピア数で、yiが指数になっていますね。ここのeは別の数字でも合計を1にしてくれるのですが、機械学習が微分を沢山使うので、微分がしやすいeになっているだけです。
分母の∑はシグマと読みます。他にもyなんとかがあれば、eの指数にして全部足してね、という意味です。
わかりやすく、明日の天気が晴れ、雨、曇りのどれになるかを出力した場合を考えてみましょう。普通、確率になると、晴れ30%(0.3)、雨10%(0.1)、曇り60%(0.6)みたいに合計で1にならないといけませんね。でも出力はめちゃくちゃで、晴れ1、雨2、曇り5みたいになっているとします。

それぞれの数字をソフトマックス関数に通すとこんな感じ。
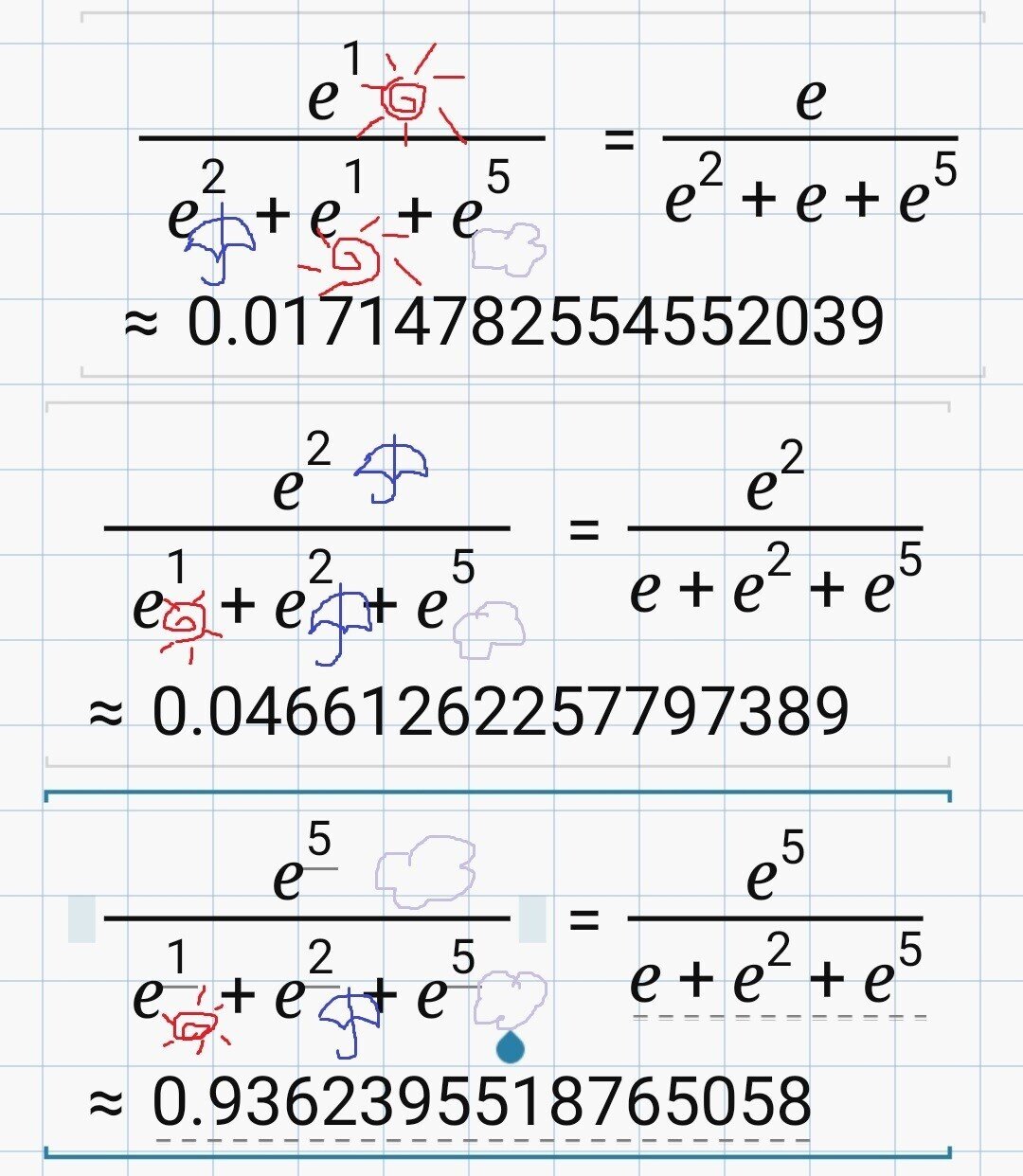
さっきの yi を y晴れ として読み替えると、y晴れは1だったので、eの1乗ですね。分母側は、ほかにも y があればeに乗せて足して下さいということだったので、y晴れ、y雨、y曇り(=1、2、5)をeの指数にして足し算しています。すると y晴れイコール0.017となりました。
同様に、y雨イコール0.04、y曇りイコール0.93になりましたね。
晴れは0.017(1.7%)、雨は0.046(4.6%)、曇りは0.94(94%)で、全部足すと1(100%)になっていますね。微分もしやすくて、どんな数字の並びがきても0~1の間、合計が1にしてくれる。これがソフトマックス関数でした。
一番最後の行にmodel.compileとなっていて、lossにcategorical_crossentropyが指定されていますね。カテゴリカルクロスエントロピー(交差エントロピー誤差とも言います。)とは損失関数と呼ばれる関数の一種で、今回のようにカテゴリー分けする問題の時に使います。
いま作った機械学習モデルは7つの数字の並びを出力するモデルでしたね。(-3%から+3%のうちどれになる確率がどれくらいなのか?)そこで出力される数字がワンホットラベルにした0と1の正解データと近いのかどうかを知らなくてはいけません。
正解データと出力が近ければ小さな数字を返して、遠ければ大きな数字を返してくれるような計算方法があれば、その数字を小さくするようにモデルの中を調節すればモデルはより正解データに近い数字を出力するようになります。
今回の0、1の数字の並びの正解データと、ソフトマックス関数から出てきた確率の形(0~1の間に収められた)の数字の並びを比べて、1個の数字にしてくれるのが交差エントロピー誤差になります。
計算式はこんな感じ。

なんか難しそう!!!でもゆっくり考えていけば大丈夫です。
ここにでてくる変数は t と y だけです。t はさっき作った正解データで、 y はモデルが出力した数字です、
しかも、t はこんな感じのデータでしたね、

つまり、t には0か1かどちらかしか入りません。tn の n は何番目かを表しているだけなので、例えば上の画像でt0なら0、t1なら1、t2なら0、t3なら0といった感じです。
t に0が入るとどうなるでしょうか。

ゼロ × log yn となって式の左側が消えて、1 × log(1 -yn) となってlog(1 -yn) だけが残りますね。
では t に1が入るとどうなるでしょうか。

(1 -1)log(1 -yn) は ゼロ × log(1 -yn) なので今度は式の右側が消えてしまいます。代わりに左側が 1 × log yn で log yn だけが残ります。
このように、t の役目は正解データ t が0か1かによって式の右側を残すか、左側を残すか選ぶような仕組みになっていることがわかりました。
次に y も見ていきましょう。y はモデルが出力する数字で、ソフトマックス関数を通すことによって0から1までの確率のような数字に収められていましたね。なので、t が 0 で y が 0のパターン1、t が 0 で y が 1 のパターン2,t が 1 で y が 0 のパターン3,t が 1 で y が 1 のパターン4の4つを見てきたいと思います。損失関数はどうなるでしょう。

t=0,y=0 つまり、正解データと出力データが同じ時、損失関数は0になりました。

t=0,y=1 つまり、正解データと出力データが最高にずれているとき、損失関数は∞になりました。

t=1,y=0 これも、正解データと出力データが最高にずれているとき、損失関数は∞になりました。

もうなんとなくわかってきましたね、t=1,y=1 正解データと出力データが同じ時、損失関数は0になりました。
こんな感じで、交差エントロピー誤差は自分たちで作ったワンホットラベルの正解データと、ソフトマックス関数にかけられたモデルの出力をくらべて、値がずれているほど大きい数字を返すめちゃくちゃ便利な関数です。この数字を頼りにモデルは自身のパラメーターを調節して、交差エントロピー誤差が小さくなる出力を出すように訓練していきます。
ざっくり理解したところで、モデルを学習していきます。
history = model.fit(X_train,y_train,batch_size=128,epochs=100,validation_split=0.2)学習に必要なのはこの一文だけです。あとは勝手にパラメーターを更新してくれます。

こんな感じで学習を繰り返してくれます。accuracyの部分がモデルの精度になります。1で100%なので94.4%ぐらいの精度ですね。
学習がどのように進んで行ったかを表示してみます。
plt.plot(history.history['accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train'], loc='upper left')
plt.show()
縦軸が精度で、横軸が学習を繰り返した回数です。100回ほどの繰り返しの学習で精度がだいたい100%になっているのがわかります。
モデルの学習が終わったので、出来上がったモデルに最新のデータを入れてみましょう。予測して、7つのカテゴリごとの確率を出力してくれます。
columns = ['-3%','-2%','-1%',
'0%',
'+1%','+2%','+3%']
predict = model.predict(n_df.iloc[-10:][use_cols].values.reshape(1,10,13))
pred = pd.DataFrame(predict,columns=columns)
pred
こんな感じで確率が返ってきました。0%、ほぼ変わらないが26%で、-3%、-2%、-1%も16%ぐらい。なんとなく株価は下がりそうな雰囲気ですね。
・おわりに
いかがでしたでしょうか、全部独学で文系卒なので色々間違えて解釈してしまっている部分があるかもしれません。もし、これは違うよ!という部分がありましたらご指摘いただけると幸いです。
今回構築したモデルで予測した株価は、実際の株価を必ずしも予測できているとは限りません。より良い予測にはより深い株式投資への理解とより深い機械学習の知識、より良いデータ、より良いパソコンが必要です。
この記事がプログラミングや投資、機械学習のなんらかの部分でつまづいている人たちの参考になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?