ざっくりとしたデジタルツインのためのLoRA作成のガイド#1

前提
ローカルでWebuiでStableDiffuisionの画像生成ができる環境になっている。Colab版は使ったことがないので、すみませんがほかの資料と読み合せてください。
自撮り加工した画像を複数枚(20枚くらい)用意できる。 また、HelloFaceなどを購入していわゆる憑依画像がある。(学習に適した画像は後述)自撮りからの加工については、在宅のアーマーさんのこちらの記事を参考にしてみてください。
例としたフォルダ構成は
C:\lora\kohya-ss 以下にKohya-SS一式インストール
C:\lora\source に素材画像
C:\lora\output\100_sts に学習用タグと画像が入るので空フォルダを用意
ざっくりとした流れ
kohya-SSのインストール。
画像の準備。自作画像から学習に適した画像を選抜します。簡単に言えば
バストアップで正面、斜め、横などがあることが望ましい。ただし横向きはむつかしい場合が多いと思うので、斜め程度で大丈夫です。背景はなるべくシンプルなものが望ましいです。これを20枚くらい。
全身ショット。憑依動画からの切り出しを5枚程度。おなじくなるべく背景がシンプルなもの
WebUIのTrainツールで、画像サイズ変換と水増し
WebUIのDatasetTagEditorツールでタグ編集
こちらのページを参考にさせていただきました
WebUIを終了しkohya-SSのGUIを起動
kohya-SSで学習
kohya-SSを終了、WebUIを起動
できたLoRAを確認
おめでとう!
kohya-SSのインストール
私はこのページを参考にさせていただきました
https://dolls.tokyo/about-kohyas_gui-setup/
画像の準備
こんな感じで画像を用意します。サイズやアスペクトは後で調整しますので、あまり気にしなくてOK。学習に使用するのは512x512なので、それより大きいほうがいいです。

WebUIのTrainツールで、画像サイズ変換と水増し
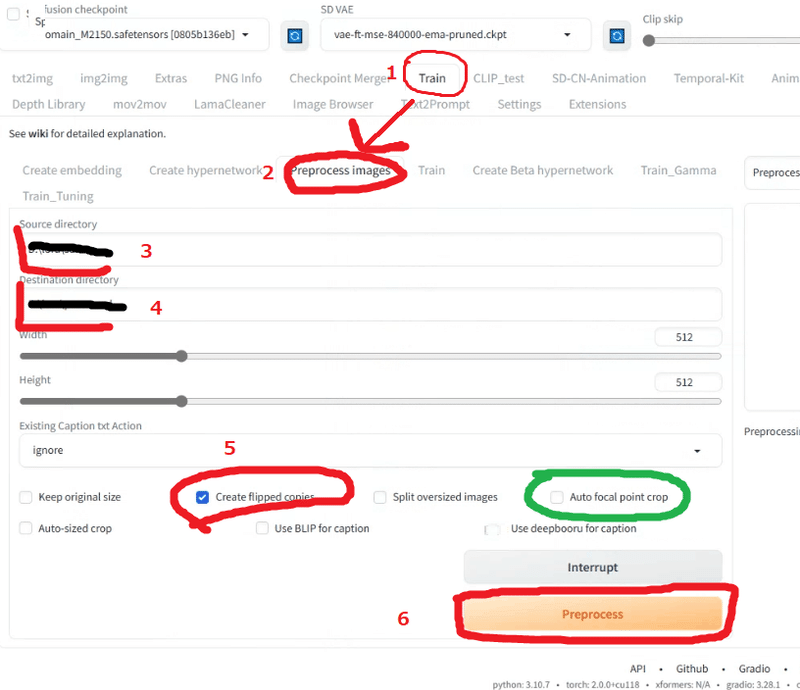
trainメニューをクリック(メニューがない場合は、たぶん何かのExtensionがインストールされてない。何だったかは覚えていないんで、後で追記します)
Process Imageタブをクリック
元画像のフォルダが入っているフォルダ名を入力。今回は、C:\lora\source なるべくシンプルなほうがいいと思います。
変換後の画像フォルダ名を入力。同じくシンプルなほうがいいです。フォルダ名に後で学習する際に必要な数値が入るので、この場合 C:\lora\output\100_sts などのフォルダ名にしてフォルダを作成。フォルダは浅いほうがいいが、ルート直下ではなく一段掘ってください。作成時にはまります。100_ の部分が重要なので、後の sts などとなっている部分は、わかりやすい簡単な文字でいいです。後述するトリガーワード(LoRAを効かせるためのキーワード)にしておくといいと思います。
Create Flipped copiesにチェック。これで左右反転イメージを作ってくれます。
PreProcessボタンを押す。

これで変換後のフォルダにリサイズと左右反転して水増しした画像が作れます。全身画像で顔が切れたものがある場合は、緑で囲ったAuto Focul Point cropにチェックを入れてみてください。顔を中心にクロップしてくれるはずです。Auto Focul Point crop使って顔がきれちゃったりした場合は、自分で正方形に切り抜いておいてください。
WebUIのDatasetTagEditorツールでタグ編集
「画像のタグを自動生成する」の、チャプター以降の作業になります。
1girl,womanあたりのタグだけ消して、トリガーワードを追加するぐらいでいいと思います。残っているタグが、属性に残らないというのがポイントです。
C:\lora\output\100_sts のフォルダには画像と画像と同じファイル名で拡張子.txtのファイルが入っています。自分の場合拡張子がないタグファイルができていましたが、一応消しました。(原因不明)多分消したほうがいいと思います。
それぞれの画像ファイルには、こんな感じで拡張子.txtのファイルが作られます。
sts, solo, long_hair, looking_at_viewer, brown_hair, brown_eyes, closed_mouth, lips, eyelashes, portrait, forehead, realistic, nose
WebUIを終了しkohya-SSのGUIを起動
PowerShell から起動。
同じく、こちらのページを参考にさせていただきました。
StableなLoRA学習環境がローカルマシンでもできるKohya’s GUIの設定方法 | 徒労日記 (dolls.tokyo)
3.学習画像の準備 以降あたりから見てください。
キモは、
標準のSDモデルで学習
設定済み環境ファイルを使用
素材フォルダ名に注意(変なキャラクターが入っていないか確認)
kohya-SSで学習
うまく始まるとこんな感じの表示がPowerShellに出ます。

完了すると、こんな感じで止まります。GUI側には変化がなかったような。

自分の環境だと終了まで30分程度でした。
RTX3080 Mem32G SSD2T CPU AMDの何だったか忘れた
できたLoraはC:\lora\output\ 以下に拡張子 .safetensorsで入っていますので、ほかのLoRAが入っているフォルダにコピー
kohya-SSを終了、WebUIを起動
できたLoRAを確認
プロンプトにはトリガーワードのみ。 LoRA の効き具合は1で

おそらく微妙におかしい画像になってますが、おおむね近い画像が出ていればOKだと思います。通常は 0.6ぐらいで使用します。ネガティブプロンプトを足して、いい感じになれば大丈夫。
この後
普通のLoRAなんで、そのまま使えますが、若干コツが必要です。
続編をご覧ください。
できたLoRAを適用し、さらにイメージに近い画像を生成し、それをベースにさらにLoRAの精度を上げていくことも考えていますが、面倒なので手を出していません。その際、自撮りでできない角度の画像は、推測で作られるので、ガチャ要素高めになると思います。
このフレームワークを使用していろいろな顔の角度の画像を用意して、新たにLoRAを作るといいかと思います。ぜひ挑戦してみてください。
GitHub - Zuntan03/CharFramework: AI画像生成でキャラクターの扱いをしくみ化してフレームワークにしてみる
間違いあったらすみません。ご指摘お願いします。
この記事が気に入ったらサポートをしてみませんか?