hierarchical softmaxについて

hierarchical softmaxとは
word2vecのskip-gramモデルやGNNのrandom walkモデルでは,損失関数にsoftmaxを計算する場合があります.その時に,word2vecでは単語の数がたくさんあり,GNNではnodeの数がたくさんあり,softmaxの計算は非常に時間がかかります.
単純にsoftmaxを計算するのではなく近似法として,hierarchical softmaxと呼ばれるテクニックがあります.neagtive samplingなども同じ問題を解決するための方法の一つですが,今回はhierarchical softmaxを解説します.
softmaxを木の構造で捉える
より具体的に考えた方がわかりやすいので,word2vecのCBOWモデルを使って考えていきます.face, fix, dog, eat, in, parkの6つの単語があるとします.
そして,contextが,eat, in, parkでそれに対するpositive sampleがdogだとします.
まず通常のsoftmaxについて考えてみます.
全体の単語数が6個です.contextの単語のeat,in,parkのembeddingを求めて,何らかのaggregate functionを噛ませることで,一つのベクトルcを精製します.そしてそのベクトルcと中間層であるembedding層の行列との積を計算し,各単語のスコアが計算します.そこからsoftmaxを計算できます.

図 1. Contextのembeddingの計算方法
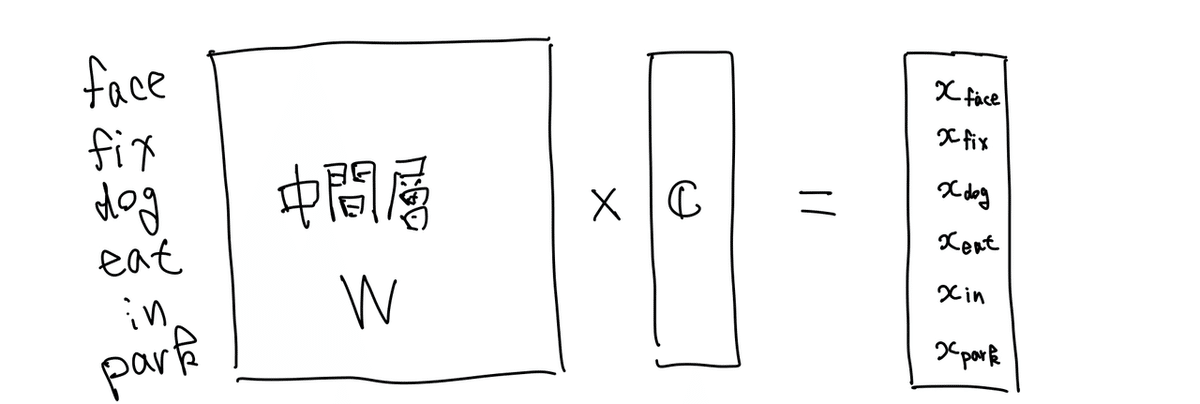
図 2. スコアの計算方法
この場合は6つの単語のスコアに対するsoftmaxを計算することになるので,単語の数が大きくなると非常に時間がかかります.expの計算が,O(1)と仮定すると,単語の数nとすれば,softmaxで確率を計算するには,O(n)かかります.
計算量を減らすテクニックとして,Hierarchical softmaxがあります.そのために,まずsoftmaxの計算を木の構造として見てみます.

図 3. softmaxの木の構造
以下のようにroot nodeから各単語のnodeに対してedgeがあり,そのedgeに確率が割り振ってあります.
実は,これ自体もHierarchical softmaxと呼べますが,中間nodeを足して,木を深くすると効用が分かります.以下のように木の深さが2の場合を見てみます(図4).同じようにedgeに確率が割り振られていて,あるnodeからその子nodeに移動する確率の合計は1になるようにします.例えば,図4では,P(1->2) = 0.3,P(1->3) = 0.4,P(1-> 4) = 0.3となります.

図4. Hierarchical softmaxの例
これによって,leafに到達する確率は合計で1になります.実際に,leafの確率を計算するには,nodeの移動の確率をかけていけば良いです.例えば,P(dog) = P(1->3) * P(3-> dog) = 0.4 * 0.9 = 0.36となります.
edgeの確率の計算方法
ただedgeの確率はどう計算すればいいのでしょうか.単純なsoftmaxの場合は,中間層とコンテキストから得られたベクトルcの掛け算をして,全ての単語のスコアを計算し,softmaxを計算していました.
Hierarchical softmaxの場合は,中間層を使わず,各edgeにembeddingを持ち,ベクトルcとそのembeddingの内積でスコアを計算します.そして,それを使ってsoftmaxをnodeごとに計算します.
そうすると,上の例であれば,通常のsoftmaxであれば,6回計算するところが,5回で終わります.
単語の数が小さい例だとあまりわからないですが,単語が10000個あるとして,木の深さが2で子nodeの数が100だとします.そうすると,10000回の計算が,100 * 2 = 200回の計算ですみます.
デメリット
計算量はO(log n)になるのですが,デメリットもあります.
より多くのEmbeddingが必要
通常のsoftmaxであれば,単語の数の分だけのembeddingを持っておけばよかったですが,Hierarchical softmaxの場合は,edgeの数だけembeddingを持つので,メモリをより多く使います.
木の構築
どのように木を作ればいいかも自明ではないです.そこにも新たな計算やアルゴリズムが必要になります.
補足
Hierarchical Softmaxは,上のデメリットもあり,negative samplingなどがよく使われているように思えます.
Reference
この記事が気に入ったらサポートをしてみませんか?