
第1回: 生成AIの紹介(基礎知識と主要な技術)

現代のテクノロジーの進歩により、生成AI(Generative AI)が注目を集めています。生成AIは、人工知能が新しいコンテンツを生成する技術の総称であり、テキスト、画像、動画など様々な形式のデータを作り出すことができます。本コラムでは、生成AIの基本的な説明、その種類、そして基本的な動作原理について紹介します。
生成AIとは?
生成AIは、既存のデータから新しいデータを生成する能力を持つ人工知能の一分野です。この技術は、ニューラルネットワーク、特にディープラーニングの進展によって大きく発展しました。生成AIは、単に既存のデータを分析するだけでなく、創造的なコンテンツを作り出すことができるため、幅広い応用が期待されています。
生成AIの種類
生成AIには主に以下の3つの種類があります。
1. テキスト生成
テキスト生成AIは、自然言語処理(NLP)技術を活用して新しい文章を生成します。代表的なモデルとして、OpenAIが開発したGPT(Generative Pre-trained Transformer)シリーズがあります。これらのモデルは、インターネット上の膨大なテキストデータを学習し、ユーザーの入力(プロンプト)に応じて自然な文章を生成します。GPTモデルは、トランスフォーマーアーキテクチャに基づいており、自己注意機構(Self-Attention Mechanism)を利用して文脈を理解します。
2. 画像生成
画像生成AIは、テキストプロンプトや他の画像から敵対的生成ネットワーク(GAN)や潜在拡散モデル(Latent Diffusion Model)の技術を使用して、新しい画像を生成します。代表的なモデルには、OpenAIのDALL-EやStability AIのStable Diffusion、NVIDIAのStyleGANがあります。これらのモデルは、様々なスタイルやコンセプトに基づいて高品質な画像を生成します。
3. 動画生成
動画生成AIは、連続するフレームを生成して動画を作り出します。3Dモデリング技術を使用して、リアルな動画やアニメーションを生成します。これにより、映画、ゲーム、バーチャルリアリティ(VR)のコンテンツ制作が大きく進化しています。最近ではOpenAIのSoraやStability AIのStable Video Diffusionなどが注目されています。
技術的背景
動画生成では、時間的な連続性を考慮する必要があります。そこで、3D CNNやRNN(Recurrent Neural Network)を用いることが一般的です。また、動画生成GAN(VideoGAN)などの技術が使用されます。これらのモデルは、フレーム間の一貫性を維持しつつ、リアルな動画を生成します。


Source: https://openai.com/index/video-generation-models-as-world-simulators/
基本的な動作原理
生成AIの基本的な動作原理には、ニューラルネットワークとディープラーニングが重要な役割を果たしています。以下に主要な技術を紹介します。
ニューラルネットワーク
ニューラルネットワークは、人間の脳の神経回路を模倣したモデルで、入力データを処理して出力を生成します。層状に配置されたニューロン(ノード)が、データを段階的に処理し、特徴を抽出します。特にディープラーニングでは、多層のニューラルネットワークを使用することで、高度なパターン認識と生成が可能です。

トランスフォーマー
トランスフォーマーは、特に自然言語処理において効果的なアーキテクチャです。自己注意機構(Self-Attention Mechanism)を使用して、入力データの重要な部分に注目し、文脈を理解します。これにより、長文のテキストでも一貫性のある生成が可能になります。GPTシリーズは、このトランスフォーマーを基盤としています。
具体的には、入力されたテキストシーケンス𝑋=(𝑥1,𝑥2,...,𝑥𝑛)に対して、各単語の埋め込みベクトル𝐸(𝑥𝑖)を計算し、それを基に自己注意機構を適用して文脈情報を抽出します。
$$
Attention(Q,K,V) = softmax(\frac {QK^T} {\sqrt {d_k}})V
$$
ここで、𝑄,𝐾,𝑉はそれぞれクエリ、キー、バリューの行列、𝑑𝑘はキーの次元数です。この計算により、モデルはテキストの重要な部分に焦点を合わせ、適切な単語を生成します。


敵対的生成ネットワーク(GAN)
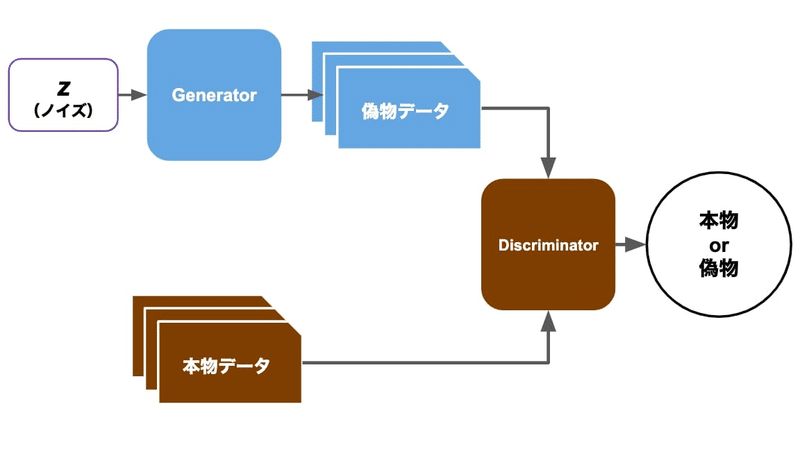
GANは、生成モデルと識別モデルの二つのニューラルネットワークが競い合う形で学習する手法です。生成モデルは新しいデータを生成し、識別モデルはそのデータが本物か偽物かを判定します。この競争により、生成モデルはよりリアルなデータを生成する能力を向上させます。GANは、画像生成や動画生成に広く使用されています。
GANは、生成モデル(ジェネレーター)と識別モデル(ディスクリミネーター)から構成されます。ジェネレーターはランダムノイズ𝑧から画像𝐺(𝑧)を生成し、ディスクリミネーターはその画像が本物か偽物かを判定します。
$$
L_{GAN} = \Bbb{E}_{x〜P_{data}(x)}[logD(x)] + \Bbb{E}_{z〜P_{z}(z)}[log(1 - D(G(z)))]
$$
この損失関数を最適化することで、ジェネレーターは本物のような画像を生成する能力を向上させます。
潜在拡散モデル(Latent Diffusion Model、LDM)
潜在拡散モデル(Latent Diffusion Model、LDM)は、生成モデルの一種で、特に画像生成タスクにおいて高い性能を発揮します。LDMは、ディフュージョンモデル(Diffusion Model)と呼ばれる技術をベースにしており、データの生成過程におけるノイズの逐次的な除去を行うことで、データの高品質な再構成を目指します。
ディフュージョンモデルは、データに対してノイズを徐々に加える過程(フォワードプロセス)と、ノイズを除去してデータを再構成する過程(リバースプロセス)の2つのステップから成ります。フォワードプロセスでは、入力データに対してガウスノイズを段階的に追加し、最終的には純粋なノイズに変換します。リバースプロセスでは、このノイズデータから元のデータを復元するように訓練されたモデルを使用します。


埋め込み空間(Embedding Space)
埋め込み空間は、高次元のデータを低次元のベクトルに変換する技術です。テキスト生成において、単語やフレーズは高次元ベクトルに埋め込まれ、これがニューラルネットワークによって処理されます。埋め込み空間は、言語の意味的な類似性を捉えることができるため、文脈を理解する上で重要です。
まとめ
生成AIは、テキスト、画像、動画など多様な形式のデータを生成することができ、その応用範囲は広がり続けています。これらの技術は、ニューラルネットワーク、トランスフォーマー、GAN、Diffusion Model、埋め込み空間などの高度なアルゴリズムに基づいています。次回のコラムでは、具体的な大規模言語モデル(LLM)の技術背景や応用例についてさらに詳しく探っていきます。生成AIの世界へようこそ。
この記事が気に入ったらサポートをしてみませんか?