
#78【ChatGPT×Python】AIにwebスクレイピングのコードを書いてもらう

おはようございます。
23営業日後に『生成AI活用法』セミナーを開催するアヒルです。サッカー界は出会いと別れの季節ですね。
webサイトから任意の情報を抜き出したい時ってありますよね。コピー&ペーストがあまりに面倒だったので、ChatGPTを使って自動化していきます。
webスクレイピングとは?
Webスクレイピングとは、webサイトから自動的にデータを抽出する技術や方法のことです。
プログラムを使って特定のウェブページを訪問し、そのページのHTMLコードを解析して必要な情報を取得します。
これによって、大量のデータを効率的に収集することが可能になります。
よくあるのは、商品価格を抜いてきたり、ニュース記事を集めたり、まぁとにかくデータ分析のために情報を収集するのに使われます。
noteの記事一覧からタイトルを抽出する
では今回は、試しにアヒルのnoteの記事ページにある記事タイトルを抽出してみようと思います。
(⚠️サイトによっては、違法なスクレイピングは法的な問題を引き起こす可能性があるため、注意が必要です。noteの利用規約を見た限りは、ダメですとは書いてありませんでした。)
記事ページはこちら。
16個の記事が並んでいるので、プログラムを組んで一括取得したいと思います。
やり方
注目するのは、HTMLです。
HTML(HyperText Markup Language)とは、webページを作成するための標準的なマークアップ言語です。
HTMLはwebの基本的な構成要素で、全てのwebページはHTMLで記述されています。
では、ページの裏側、HTMLの構造を見てみます。PCですと右クリック>ページのソースを表示、もしくはCtrl + Uキーで、以下のような画面が見られます。

この中に、記事タイトルがいるわけです。
Ctrl + Fキーで、前回の記事「#77【ChatGPTでワードクラウド作成】検索ボリュームを見える化したら」と検索してみます。

記事のタイトルは、青い部分「<h3 class="o-textNote_title" data-v-7decbd66>」と「</h3>」で囲まれていることがわかります。
この「h3」は見出しに使われるタグです。
同様に他の記事のタイトルも、同じタグで囲まれていました。
そのことをChatGPTに伝えて、Pythonのコードを作成してもらいます。

そして生成されたコードが以下です。
import requests
from bs4 import BeautifulSoup
# URL of the webpage
url = “https://note.com/generative100/all"
# Send a GET request to the webpage
respanse : requests.get(url)
# Parse the webpage content
soup = BeautifulSoup(response.content,“html.parser')
# Find all article titles
titles = soup.find_all ('h3',class_='o-textNote_title')
# Extract the text from each tit le and print it
for i, title in enumerate (titles,1):
print(f"Article {i}:{title.get_text()}")できたコードをGoogleColaboratory上で動かしていきます。
Pythonコードを実行する
パソコンにPythonをインストールしていなくても、Pythonコードを実行できる無料のツールがGoogleColaboratoryです。
使い方はとっても簡単です。


貼り付けたら、コードのすぐ左に再生(実行)ボタンが出てくるので、押すと、すぐに結果が下の方に出力されます。
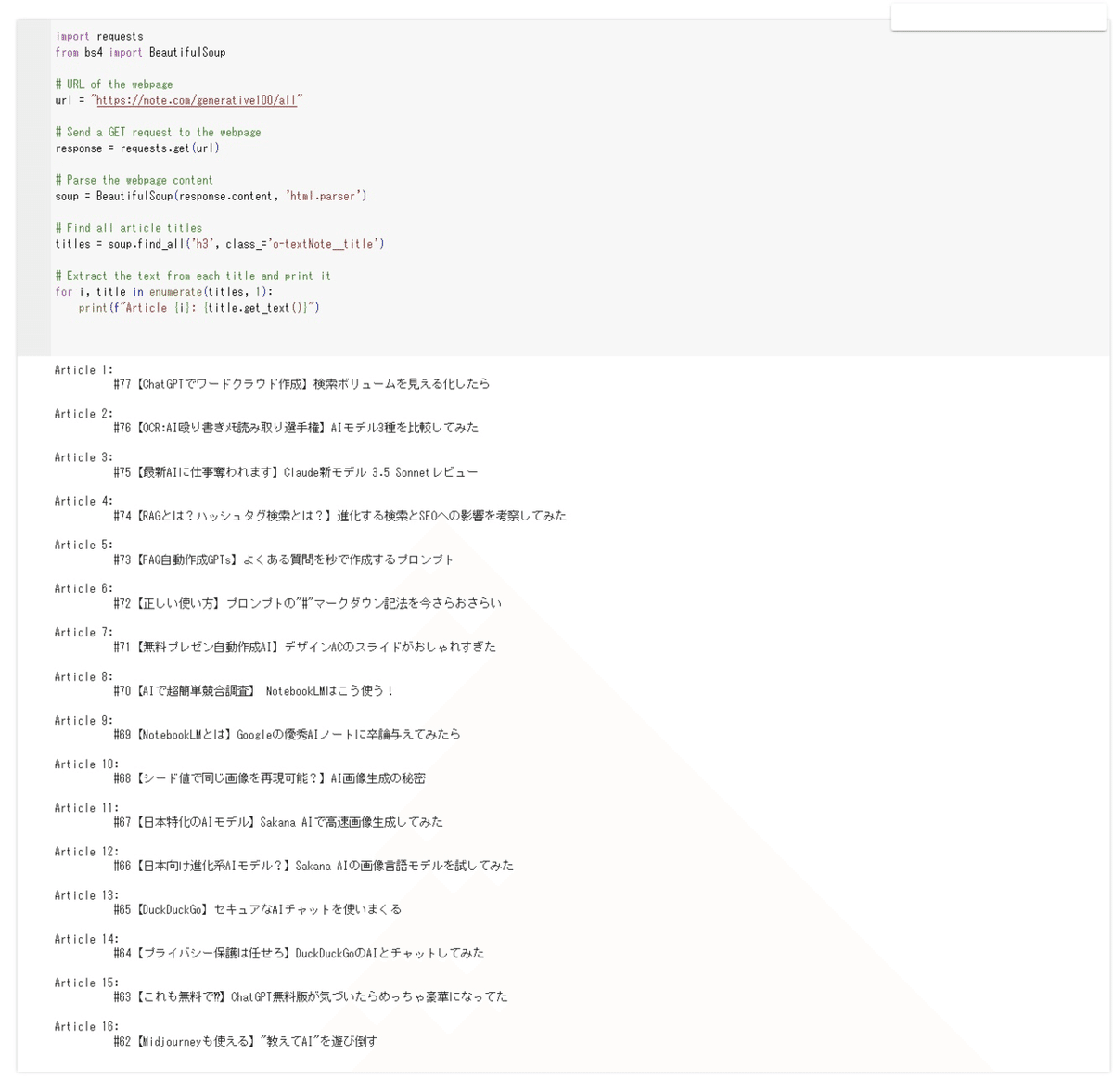
これで完成です。
HTMLに着目すれば、他にも様々な要素を抽出することができます。
実はそんなことしなくても
ChatGPTに作成してもらったコードをGoogleColaboratory上で実行しましたが、実はGoogleスプレッドシートなら、もっとシンプルにできます。
IMPORTXML関数というスプレッドシート限定の関数を使うと、一行の関数で解決します。
自分は競合分析でスクレイピングする時はこっちを使うことが多いです。AIではないので深くは触れませんが、関数はこのような感じです。
=IMPORTXML(url, xpath_query)"xpath"というのが聞き馴染みがないと思いますが、これは、XMLやHTML文書の中から特定の部分を選択するための言語です。
例えば、とあるサイトで「h1」タグの内容を抜き出したい時は、
=IMPORTXML("https://example.com", "//h1")といった感じです。
個人的には、複数URLを一気に分析したい時はこっちの関数を使う方が楽なのかなと思ったりもします。
まとめ
ChatGPTとPythonを使って、webスクレイピングを行う方法をまとめました。
スクレイピング自体をChatGPTに頼んでもみましたが、サイト内の情報をそのまま持ってくることはできないと言われてしまいました。
AIを使って作業するのか、AIに手伝ってもらって別のツールを使うのかの区別ができるようになるといいなと改めて感じました。
今週もお読みいただきありがとうございました!