SD XLのUNetについて

SD XL-baseのUNet構造をみていきます~。多分どこか間違っています。
v1/v2についてはこちらに書いてありますよ~~。
全体構造

ResNetのグラデーションは入出力でチャンネル数が変わるという意味
Transformer層の中の数字は層の深さ
v1/v2と比べて画像が8分の1に縮小される部分が省略されていて、ブロックの数(UNetのスキップコネクションの数)は少なくなっています。ただし内側の層のTransformerの深さが非常に大きくなっており、これがUNetが巨大化した要因になっています。チャンネル数はv1/v2と同じ感じですね。
各ブロックの条件付け
上の図では省略されていますが、各ブロックにはテキスト・画像サイズ・時刻の三つの条件が入力されます。
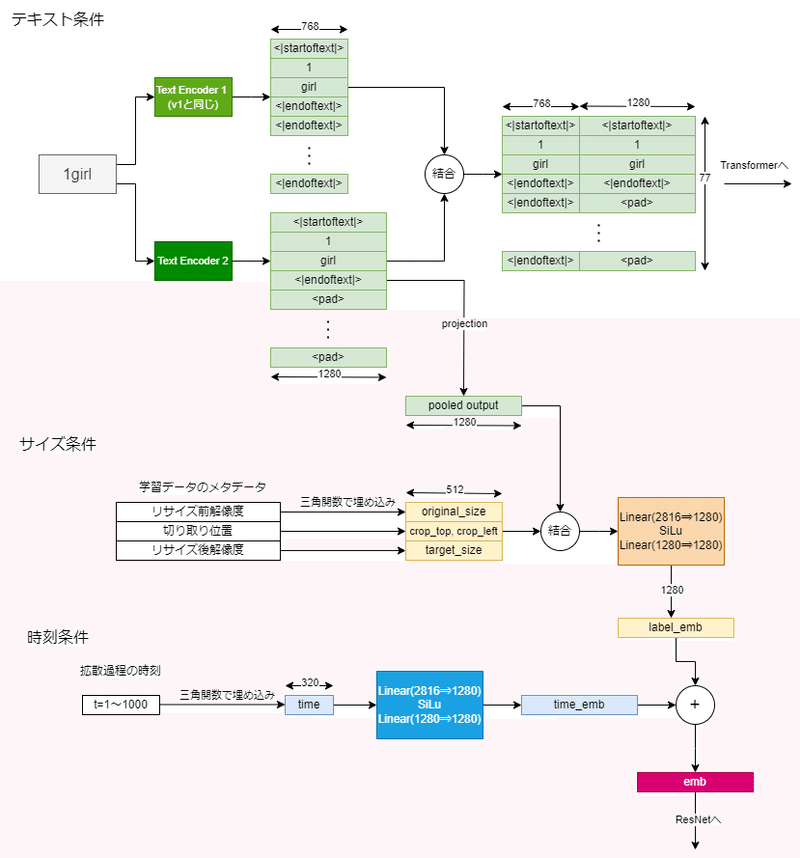
テキスト条件
プロンプトに関する条件付けです。v2までと違って二つのテキストエンコーダを使います。最後から二番目の隠れ層の出力を結合し、Transformerへ入力されます。さらに二つ目のテキストエンコーダのEOS部分が、ResNet側に入力する条件として使われます。v2まではResNet側にはテキストの情報は使われなかったのですが、XLではResNet側にも情報が与えられます。
サイズ条件
画像のサイズに関する情報を入力します。リサイズ前の解像度、切り取り位置、リサイズ後の解像度(生成解像度)の三種類があります。最初の二つは学習時に学習データが元々どのくらいの解像度であったかとか切り取られたものであるとかを教えることによって精度を上げるためのものです。三つ目は実際に生成する解像度であって、これによってUNet自身が今どんな解像度の画像を作ればいいかを知ることができます。実はv2までの構造ではUNetは自分がどのくらいのサイズの画像を生成しているのかを分かっていませんでした。
時刻条件
拡散過程のどの時刻にいるかを入力するもので、v1/v2から既に存在していて変わっていません。この条件付けのおかげで各ステップで同じUNetを使いまわすことができます。
ここから各層の説明に移っていきます。といってもv1/v2からほとんど変わってないんですけど、図とかもうちょっとわかりやすくします。
ResNet層

ResNet層は入出力でチャンネル数が違う場合があります。違う場合は1個目の畳み込み層及びスキップコネクションの1×1畳み込み層でチャンネル数が変更されます。また途中で条件埋め込みが足されます。条件埋め込みは出力チャンネル数と合わせるように線形層で変換され、1層目の出力に足されます。足すときはピクセル方向にブロードキャストします。GroupNormの32はグループ数のことです。
Transformer層
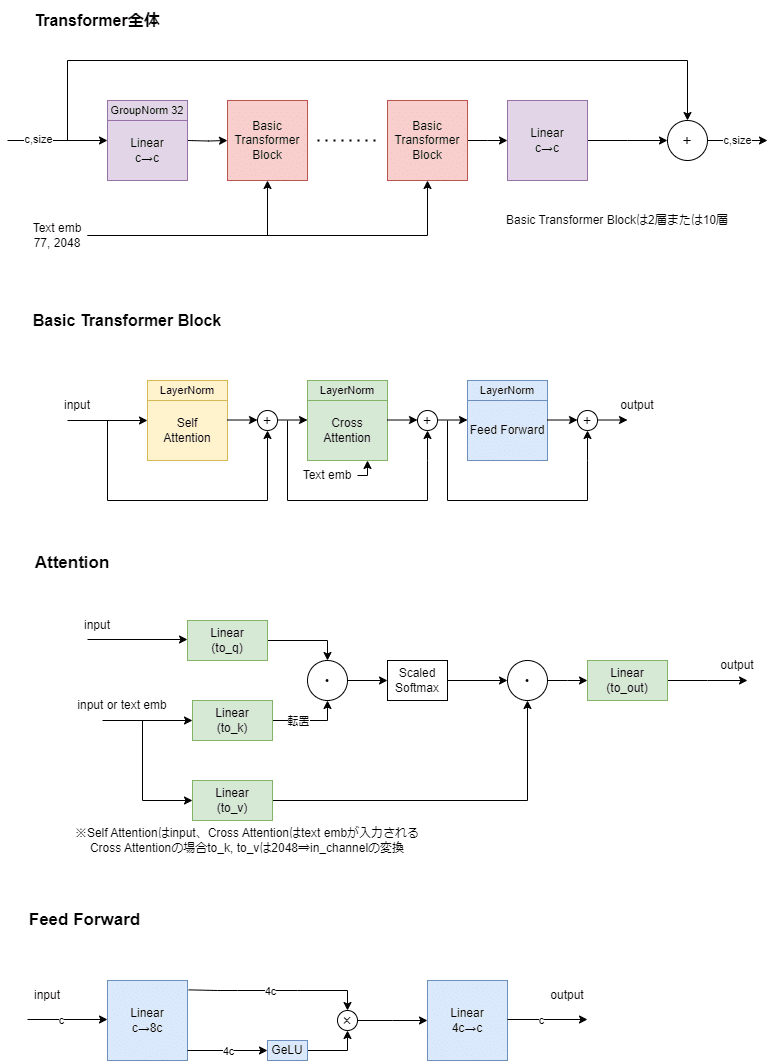
Transformer層は入出力でサイズ不変なのでサイズは結構省略しています。v1/v2と比べて一つのTransformerブロックに複数の層があります。画像が2分の1に縮小されている層では2層、4分の1に縮小されている層では10層もあります。
Attention層ではmulti head attentionが適用されています。各headの次元が64になるようにhead数を調整しています。この辺りはv2の変更点をそのまま踏襲しています。
Downsample層、Upsample層

Downsampleはstride=2の畳み込み層によって画像を縦横2分の1ずつに縮小します。Upsample層は最近傍補間によって縮小前のサイズに戻してから畳み込み層を適用します。
Downsample層は2回適用されるので、画像のサイズが32の倍数(=潜在変数のサイズが4の倍数)であれば割り切れますが、そうでない場合は切り上げられます(切り上げでいいんだよね?)。そのためUpsample層は単に2倍にする処理ではなく、対応するDownsample層による縮小前のサイズに合わせるように拡大します。そうしないとUNetのスキップコネクション部分でサイズが合わないエラーが起きます(StabilityAIの実装は単に2倍にするだけなのでそうなります)。
アーキテクチャ考察
この構造から予想できることを自分なりに書いていきます。
深さ増やして幅はそのまま
UNetのサイズは大きくなりましたが、チャンネル数は変わっていません。幅が変わらないので一度に計算する規模が大きくならずVRAM使用量を抑えられている・・・のかな?まあモデルサイズそのものや解像度は大きくなっているので結局VRAMはいっぱい必要になっていますけど。
ResNet層がより重要に→LoConが推奨される?
ResNet層には解像度などの情報やv1/v2では入力されていなかったテキストの情報が入力されるようになっています。さらにDownsampleが適用されていない元のサイズのまま扱う層からTransformerが削除されてResNet層だけになっています。そのためLoRAにおいてもResNet層まで学習できるLoConにした方がよさそうな感じがします。そもそもResNetにくらべてTransformerが非常に大きくなっているので、LoRAとLoConのサイズはそこまで変わらなくなっていると思います。
Transformer層の深さが大きく変わった
Transformers層はv1/v2では1層でしたが、XLではUNetの内側の層では10層と大きく拡大されています。その代わりUNetの外側の層ではTransformer層が削除されています。これはTransformerが大域的な情報を解析するといわれていることや、計算量がピクセル数の二乗になることから自然な構造なんだと思います。
計算量削減法の一つであるToken Merging(私の解説記事)では外側のTransformer層に適用することで効果をあげていましたが、XLではその外側のTransformer層が無くなってしまったので、相性が悪いかもしれません。
ControlNetはどうするんだろう
ControlNetはDown側からmid側までのブロックをコピーしたものを学習し、スキップコネクションに出力を足す形になっています。XLではスキップコネクションの数が減った分与えられる情報はむしろ減っています。モデルのサイズが大きくなったにもかかわらず入力部分が縮小されているというのはどうもよくないような気がしますが、構造上の変更はあるんでしょうか?
VAEがくそ
UNetと直接は関係ありませんが、VAEも構造は同じです。ただし新しく学習したものを使うようで、今までのVAEとは互換性がありません。この新しいVAEはfloat16で計算するとほぼ確実にNaNになる素晴らしいモデルです。
技術レポートの考察
ついでに技術レポートを読んで思ったことを書いていきます。
学習
256の正方形で学習→512の正方形で学習→1024付近の複数のアスペクト比で学習という流れらしいです。また三段階目はnoise offsetを0.05適用しています。色んな所で512画像の生成がうまくいかないという話を聞きますが、noise offsetを適用せず学習しているからだったりするのかな?
評価指標
人間の評価はXLがv1/v2を圧倒していますが、FID的には負けているらしいです。それでFIDなんて役に立たん!と書いてありますが私もそう思いますね。Imagenやその追試であるDeepFloyd IFとかがFID争いをしている中で、SD XLはユーザーからの評価が高い複数アスペクト比学習やnoise offsetを取り入れたりと、本当にユーザーが求める画像生成AIを目指している感じがします。
まとめ
すごそうな予感がすごくします。