pandasにcsvをファイルではなく変数から読み込む

pandasのDataFrameにcsvファイルからデータを読み込むのはread_csv()で簡単に出来るが、いわゆるヒアドキュメントとなっているcsvフォーマットのデータを読み込む簡単な方法(ライブラリ)がなかったのであんまりすっきりしないが備忘録でやり方を書いておく。
DATA="""
日時,日時べた,個数
2022-11-22 21:54:27.884993,20221122 215427,123
2022-12-23 21:57:21.885405,20221223 215721,179
2022-09-07 15:15:30.885458,20220907 151530,101
2022-09-27 09:54:56.885495,20220927 095456,108
2022-10-11 17:52:50.885529,20221011 175250,192
2022-10-24 10:07:04.885561,20221024 100704,190
2022-10-04 09:08:16.885593,20221004 090816,132
2022-10-21 21:38:34.885624,20221021 213834,166
"""
import pandas as pd
dataset = []
columns = []
line1st = True
for line in DATA.split('\n'):
if len(line) == 0:
continue
if line1st:
columns = line.split(',')
line1st = False
else:
dataset.append(line.split(','))
df = pd.DataFrame(dataset, columns=columns)
df
何をやっているかというと、ヒアドキュメントのデータ(DATA)を改行区切りで1行ずつ読み込み、1行目はpandasのDataFrameのcolumnsに指定するデータとし、それ以降の行をデータとしている。ヒアドキュメントから読み込む際に空行が読み込まれているのでそれを弾いている。
結果
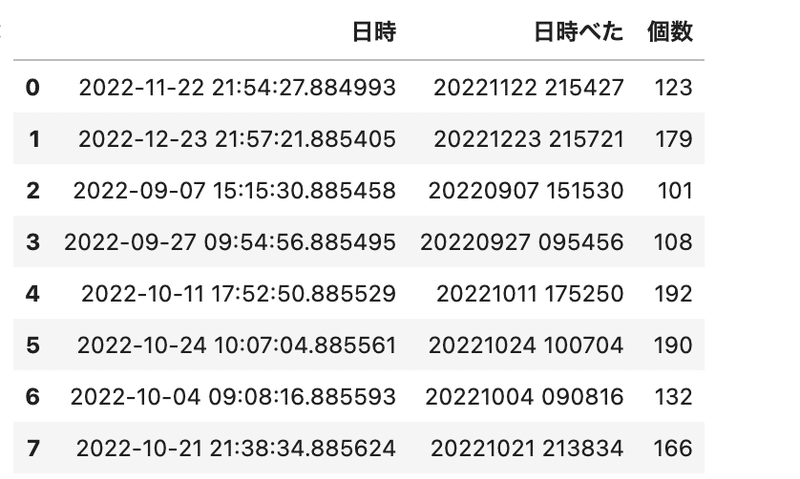
ということで無事にDataFrameに収めることが出来た。
なんとなく一発で読み込む方法があるのではないかという気がしてならないが。
この記事が気に入ったらサポートをしてみませんか?