
DP.19:使うアルゴリズムを切り替える - Strategyパターン -【Python】

【1】Strategyパターン
Strategyパターンは
入力された値によって問題解決に使用するアルゴリズムを切り替える
という書き方。
たいていの問題はいくつものアルゴリズムが編み出されている。
入力されるデータや環境によって、スピード・精度・負荷・・・等の重視すべき観点が違うため、採用するアルゴリズムも変わってくる。
あらゆる状況に対し、一番良いパフォーマンスを出すような唯一無二のアルゴリズムは存在しない。
■例:ソートアルゴリズム
例えば、ソートアルゴリズムを使う時には次のような点を考慮する。
・要素数(入力サイズ)
・時間計算量(ステップ数、オーダー) ←これが基本的な判断要素
・メモリ消費量 ※特にIoT、組み込み系で重要になりやすい
・ソートの安定性 ※同じ値同士の並び方
・コードの複雑さ ※同じような性能ならよりシンプルな方がメンテが楽
・・・等々
【2】アルゴリズムが切り替わる実例
■Pythonのsorted()、list.sort()
Pythonの「sorted()」や「list.sort()」には「key」というパラメータがある。これによりソート基準が変わるが、入力値によっては裏で使用するアルゴリズムが切り替わっている。
ソートの話ばかりになってしまったが、「データ暗号化・復号化」「データ圧縮」「画像フォーマット(jpg, png, bmp・・・)」・・・など様々な分野で複数のアルゴリズムがあり、Strategyパターンを用いることができる。
■プラットフォーム(OS)による文字コード・改行の違いを吸収する
Windows、Unix/Linux、macOSといったプラットフォームによって改行コードや文字コードは違っていても、エディタを開くといい感じに自動判定して改行が正しくできていたり、適切な文字コードを検出したりする。
→ 適切なアルゴリズムを選ぶことで、文字化けせずに表示される。
【3】例題:pangram:パングラム判定
例題として『pangram判定:1回以上全ての文字(26個のアルファベット)を使って文章を作っているか』を判定する。
pangram例文:
The quick brown fox jumps over the lazy dog.
▲35文字で構成される文章。1回以上全てのアルファベット(大文字/小文字区別なし)を使っている。
■(1):「for 文」+「if - in構文」で判定する
1つ目のアルゴリズムは、for文でループを回して「全26個のアルファベット(大文字/小文字区別なし)」を1文字ずつ、入力文章内に含んでいるかチェックしていく方法。
【プログラム1】
from string import ascii_lowercase
# アルゴリズム1:「for文」+「if-in構文」
def check_pangram_with_loop(text):
# 入力テキストを小文字に統一
lowered_text = text.lower()
# 全アルファベットを取り出して
for ch in ascii_lowercase:
if not ch in lowered_text: # 入力テキストに含まれるかチェック
return False
return True
▲今回はpython組み込みの「文字列定数:string.ascii_lowercase」と「str.lower()」を駆使して、小文字アルファベットに統一して判定処理している。
【文字列定数:string.ascii_lowercase について】
【str.lower()】
■(2):set型の集合演算(部分集合判定)を活用する
簡単に言うと「set型」は
「順序を持たない」・「要素の重複を許可しない」オブジェクトのコレクション。
・値(要素)が集合に属しているかを判定する
・和集合や積集合の計算をする
・・・
といったときに使用する。
なお計算コストは以下参照。
↓
「set型がもつ部分集合判定:issubset()」を活用することでpangram判定をコーディングすることもできる。
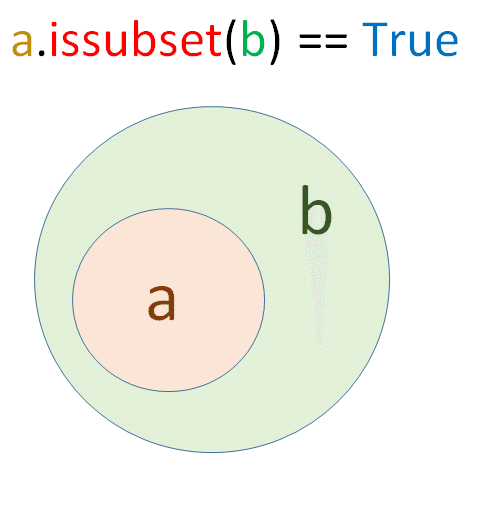
【issubset()のイメージ図】
「a.issubset(b)」では、「集合a」が「集合b」の部分集合ならTrueが返ってくる。
<Trueとなる場合のイメージ図>
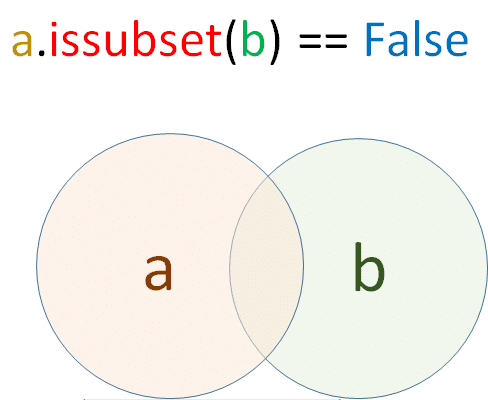
<Falseとなる場合のイメージ>
↓ この仕組みを使って以下のように書ける
【プログラム2】
from string import ascii_lowercase
def check_pangram_with_set(text):
ascii_lowercase_set = set(ascii_lowercase) # set型作成
lowered_text_set = set(text.lower()) # set型作成
# 部分集合の判定
if ascii_lowercase_set.issubset(lowered_text_set) == True:
return True
else:
return False
# 以下のように1行でもOK
#return set(ascii_lowercase).issubset(set(text.lower()))イメージ図は以下のような感じ。

【4】Strategyパターンで切り替えられるようにする
コールする関数を切り替えられるようにするために、それぞれのプログラムを起動させるラッパを用意すればよい。
from string import ascii_lowercase
# for文をまわしてチェック
def check_pangram_with_loop(text):
# 入力テキストを小文字に統一
lowered_text = text.lower()
# 全アルファベットを取り出して
for ch in ascii_lowercase:
if not ch in lowered_text: # 入力テキストに含まれるかチェック
return False
return True
# setを使う
def check_pangram_with_set(text):
ascii_lowercase_set = set(ascii_lowercase)
lowered_text_set = set(text.lower())
if ascii_lowercase_set.issubset(lowered_text_set) == True:
return True
else:
return False
# 以下のように1行でもOK
#return set(ascii_lowercase).issubset(set(text.lower()))
# 指定のアルゴリズムを起動させるラッパ
def is_pangram(text,strategy):
return strategy(text)【使い方】
# サンプル文章
sentence = "The quick onyx goblin jumps over the lazy dwarf."
# dict型に登録しておく
strategies = {
"1": check_pangram_with_loop,
"2": check_pangram_with_set
}
strategy = strategies["2"] # 指定の関数をセット
result = is_pangram(sentence, strategy) # 入力文とセットした判定関数を渡して起動する
print(result)前回も使用したやり方だが、pythonの「第一級オブジェクト(first-class object)」の仕組みを活用してコールしたい関数を辞書に積んでいる。
【5】全体コード
from string import ascii_lowercase
# アルゴリズム1:for-loop
def check_pangram_with_loop(text):
# 入力テキストを小文字に統一
lowered_text = text.lower()
# 全アルファベットを取り出して
for ch in ascii_lowercase:
if not ch in lowered_text: # 入力テキストに含まれるかチェック
return False
return True
def check_pangram_with_set(text):
ascii_lowercase_set = set(ascii_lowercase)
lowered_text_set = set(text.lower())
if ascii_lowercase_set.issubset(lowered_text_set) == True:
return True
else:
return False
# 以下のように1行でもOK
#return set(ascii_lowercase).issubset(set(text.lower()))
# 指定のアルゴリズムを起動させるラッパ
def is_pangram(text,strategy):
return strategy(text)
### 動作確認 ####
def main():
print("---- Is Pangram ? -----")
sentence = input("type sentence: ")
strategies = {
"1": check_pangram_with_loop,
"2": check_pangram_with_set
}
picked_strategy = input("Choose strategy:[1] for-loop, [2] Set : ")
try:
strategy = strategies[picked_strategy]
result = is_pangram(sentence,strategy) # 入力文字とアルゴリズムをわたして起動する
print(result)
except KeyError as err:
print("Incorrect option")
if __name__ == '__main__':
main()【実行結果】
# for文を使った場合1:Trueパターン
(myenv) ... ... > python main.py
---- Is Pangram ? -----
type sentence: The five boxing wizards jump quickly.
Choose strategy:[1] for-loop, [2] Set : 1
True
# setを使った場合1:Trueパターン
(myenv) ... ... > python main.py
---- Is Pangram ? -----
type sentence: The five boxing wizards jump quickly.
Choose strategy:[1] for-loop, [2] Set : 2
True
# for文を使った場合2:Falseパターン
(myenv) ... ... > python main.py
---- Is Pangram ? -----
type sentence: Imagination means nothing without doing.
Choose strategy:[1] for-loop, [2] Set : 1
False
# setを使った場合2:Falseパターン
(myenv) ... ... > python main.py
---- Is Pangram ? -----
type sentence: Imagination means nothing without doing.
Choose strategy:[1] for-loop, [2] Set : 2
False
【6】おまけ
似たような内容になるが、
・入力した「単語」について、文字の重複があるかどうかを判定する
・「判定アルゴリズム」を2つ用意して切り替えられるようにする
・単語の文字数によってはアルゴリズムが遅くなるようにする
というプログラムを作ってみる。
今回は、単語の文字数「6」を基準にsleep()をかけるかどうか切り替えるようにしている。(→アルゴリズムによる計算速度の違いを疑似的に表現するため用。)
判定方法も「ソートして隣の文字と重複判定パターン」と「set型で重複判定パターン」の2つを用意した。
import time
import sys
SLOW = 3 # sleep時間
LIMIT = 6 # 基準にする文字数
# イテレータ用
def pairs(seq):
n = len(seq)
for i in range(n):
yield seq[i], seq[(i+1) % n] # 一回実行したら状態保存してreturnする
# 文字列をソート+隣の文字と比較して重複判定
def allUniqueSort(s):
if len(s) > LIMIT: # (LIMIT)個より文字数が長いとsleep()がかかる(要素が多いと遅くなる演出)
print(f"over {LIMIT} character! this is slow algorithm...")
time.sleep(SLOW)
sorted_str = sorted(s)
for c1, c2 in pairs(sorted_str):
if c1 == c2:
return False
return True
# setオブジェクトで重複チェックするアルゴリズム
def allUniqueSet(s):
if len(s) < LIMIT: # (Limit)個より文字数が短いとsleep()がかかる(少ない要素だとが遅くなる演出)
print(f"under {LIMIT} character ! slow algorithm....")
time.sleep(SLOW)
return True if len(set(s)) == len(s) else False
#指定のアルゴリズムを起動させるラッパ
def allUnique(word, strategy):
return strategy(word) # 渡されたアルゴリズムを実行して結果を返す
### 動作確認 ####
def main():
print("----check all the unique?-----")
word = input("type words (type quit to exit):")
if word == 'quit':
sys.exit(0)
strategies = {
"1": allUniqueSet,
"2": allUniqueSort
}
picked_strategy = input("Choose [1] Use a set, [2] Sort and pair: ")
try:
strategy = strategies[picked_strategy]
result = allUnique(word,strategy) # 入力文字とアルゴリズムをわたして起動する
print(result)
except KeyError as err:
print("Incorrect option")
if __name__ == '__main__':
main()■実行結果
(myenv) ... ... > python main2.py
type words (type quit to exit):algorithm
Choose [1] Use a set, [2] Sort and pair: 1
True
(myenv) ... ... > python main2.py
type words (type quit to exit):algorithm
Choose [1] Use a set, [2] Sort and pair: 2
over 6 character! this is slow algorithm...
True
(myenv) ... ... > python main2.py
----check all the unique?-----
type words (type quit to exit):hello
Choose [1] Use a set, [2] Sort and pair: 1
under 6 character ! slow algorithm....
False
(myenv) ... ... > python main2.py
----check all the unique?-----
type words (type quit to exit):hello
Choose [1] Use a set, [2] Sort and pair: 2
False
もっと応援したいなと思っていただけた場合、よろしければサポートをおねがいします。いただいたサポートは活動費に使わせていただきます。