
フットボール統計学 パス一意性をモデリングする(翻訳)

April 11, 2019
Modeling Passing Uniqueness
By Derrick Yam
**********
StatsBombは、プロフットボールのより優れたプロフィールのパサーに3つの新しいパス指標を明らかにしている。なぜパス指標か。これはフットボールでありパスは遍在するためである。良くも悪くも、偏在する出来事はすでに与えているよりずっと注意を必要とするかもしれない。これらの指標を通じてパサーの創造性、予測可能性、そして率直に言って全体的なパス能力を評価することが目的である。公に利用可能にされた仲間によるいくつかの素晴らしい作業のおかげで、あまりにも多くの時間を浪費する革新なしでこれらをまとめることができた。喜びを広げ、全ての人々の熱心さをピークにするために一連の投稿で指標を解放する。今日発表する最初の指標は「パス一意性」である。
パス一意性の方法論
「パス一意性」は以前の作業のバリエーションである(このアイデアの新規性をごくわずかに主張しているのではないが、StatsBombでの膨大な量のデータのおかげでそれを拡大する)。元の方法論はFC RStatのGitHubで利用可能で、元のコードさえ見つけられる。一意性指標の利点は、どの選手が他よりも一般的なパスを行わないかを確認することである。元のメモを書いているように、あまり一般的でないパスは必ずしも有利なパスではないが。それは完全に不安定なこともあるが、それ自体は一意的である。後続の投稿では、有利なパスを特定することについて話す。
A "Unique" Passing Model - Explainer & Findings
— FC rSTATS (@FC_rstats) October 16, 2018
I built a passing model with @StatsBomb World Cup data & wrote a full report:
PDF (without video clips) : https://t.co/tghB7RdXo8
Keynote (with video clips) : https://t.co/dExZ8idd33
Likes & Retweets appreciated
Comments loved pic.twitter.com/UmGcSCTKzo
これらの方法の基本は前の反復とほぼ同じだが、少し異なる方法を必要とするいくつかの重要な拡張を行う。各パスを記述する次のような類似の変数を抽出する。
duration
length
angle
height.id (1 = グラウンドパス、2 = 低いパス、3 = 高いパス)
body_part.id (1 = 右足、2 = 左足、3 = その他)
location.x
location.y
end_location.x
end_location.y
大会レベルで、各個別パス(ターゲット)に最も類似した20本のパス(k = 20)をk近傍法で検索する。最も類似しているとは、ユークリッド距離内でターゲットのパスに最も近いパスとして定義される。「一意性」指標は、全てのk = 20回のパスについてのユークリッド距離の合計として計算される。より正式に、
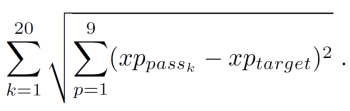
k近傍法(k-nearest neighbor algorithm、kNN)は、特徴空間における最も近い訓練例に基づいた分類の手法であり、パターン認識でよく使われる。最近傍探索問題の一つ。k近傍法は、インスタンスに基づく学習の一種であり、怠惰学習 (lazy learning) の一種である。その関数は局所的な近似に過ぎず、全ての計算は分類時まで後回しにされる。また、回帰分析にも使われる。
解析学においてノルム(norm)は、平面あるいは空間における幾何学的ベクトルの "長さ" の概念の一般化であり、ベクトル空間に対して「距離」を与えるための数学の道具である。ノルムの定義されたベクトル空間を線型ノルム空間または単にノルム空間という。
数学におけるユークリッド距離(Euclidean distance)とは、人が定規で測るような二点間の「通常の」距離のことであり、ピタゴラスの公式によって与えられる。この公式を距離函数として用いればユークリッド空間は距離空間となる。ユークリッド距離に付随するノルムはユークリッドノルムと呼ばれる。古い書籍などはピタゴラス計量(英: Pythagorean metric)と呼んでいることがある。
height.idやbody_part.idのような質的なデータ(カテゴリー変数)でユークリッド距離を使用することにはいくつかの論争がある。ただし単純化のため、意図的で素朴な仮定でそれらの数値IDは連続していると仮定し、グラウンドパスが低いパスに近く、低いパスは高いパスに近くなるように直感的に並べる。カテゴリー変数をよりよく説明するための他の指標があり、KNN距離指標のための良い参照は以下で見つけられる。ユークリッド距離は検索内のすべての変数にわたって集計されるので、すべての変数を同じ平均0、標準偏差1を持つようにスケールする(標準化)ことが重要である。そうでなければ、個々の距離計量が他の共変量よりも大きくなるという理由で、より大きなスケール上の変数は不当により多くの重みを持つことになる。
RパッケージFNNはこの検索を非常に速くし、320万パスのデータセットを実行するのに約2分かかる。次元を減らし、各検索のサンプルをより均質に保つために、各リーグ内の最近傍点のみを検索し、1シーズンまでの日付を更新する。ここで制限に注意することが重要である。サンプルサイズが大きいほど、ユークリッド距離が小さく、類似するパスが多くなり、その結果一意的なパスが少なくなるという制限がある。規模の大小が異なる大会で一意性指標をより測定可能にするためには、各大会内の総人口の割合に等しいkを設定することは意味がある。
その制限を別の方法で説明する。KNN検索をモデルベースの方法に拡張する。各リーグのKNN検索から計算された「一意性」の値を使用して、元の検索で同じ共変量の一意性の値を回帰する。これを単純な線形回帰で行うこともできるが、位置座標と一意性の間の非線形関係を正しく指定する必要がある。代わりに、非線形性をシームレスに処理するためにツリーベースの方法を使用する。XGBoost(eXtreme Gradient Boosting)を使用して、1000ラウンドのトレーニングで最大深度12の異なる予測子の組み合わせのツリーを構築する。
XGBoostはC++、Java、Python、R、およびJuliaの勾配ブースティングのフレームワークを提供するオープンソースのソフトウェアライブラリである。Linux、Windows、およびmacOSで動作する。プロジェクトの説明から、「測定可能、移植可能、分散された勾配ブースティング(GBM、GBRT、GBDT)ライブラリ」を提供することを目指す。単一のマシンで実行する以外に、Apache Hadoop、Apache Spark、およびApache Flinkの分散処理フレームワークもサポートする。最近、機械学習大会で優勝した多くのチームにとって最適なアルゴリズムとして、多くの人気と注目を集めている。
歴史
XGBoostは当初、Tianqi Chen氏による分散(深層)機械学習コミュニティ(DMLC)グループの一員としての研究プロジェクトとして始まった。当初、libsvm構成ファイルを使って設定できる端末アプリケーションとして始まった。それは、Higgs Machine Learning Challengeの優勝ソリューションで使用された後、機械学習大会でよく知られるようになった。その後すぐに、PythonとRのパッケージが構築され、XGBoostはJulia、Scala、Java、そして他の言語のパッケージ実装を持つようになった。これはライブラリをより多くの開発者にもたらし、Kaggleコミュニティの間でその人気が高まったことで貢献した。
すぐに他の複数のパッケージと一緒に使われるようになり、それぞれのコミュニティで使いやすくなった。Pythonユーザーのためのscikit-learnとの統合、およびRユーザーのためのcaretパッケージとの統合も行われる。抽象化されたRabitとXGBoost4Jを使用して、Apache Spark、Apache Hadoop、Apache FlinkなどのData Flowフレームワークに統合することもできる。XGBoostの作業はTianqi Chen氏とCarlos Guestrin氏によっても公開されている。
次に、KNN検索による実際の一意性とxgboostメソッドによる予測される一意性の間の相関関係を確認する。結果の散布図を以下に示す。

相関
かなりうまくいったように見える。観測された一意性と予測された一意性の間の相関は0.967だった。
それでは、なぜこのモデルベースの拡張が役に立つのか。いくつかの理由がある。まず一意性指標の元のフレームワークでは、更新ごとに大会全体を検索する必要がある。特に、週に2〜3回競技会を更新する必要がある場合、計算コストが高くなる。第二に、結果は参加している個々の大会に依存しているため、新しい大会、特に試合数の少ない大会には容易に拡張できない。モデルベースのアプローチを使用することで、「一意性」の指標を新しい対戦や大会での新しいパスにすばやく拡張できる。モデルベースのアプローチでは、実際の「一意性」の値に影響を与える最も重要な機能をさらに調査することもできる。

応用
その長い方法論で邪魔にならないように、すべてのクールで興味をそそる応用に入る。一意性指標は、ほとんどの場合よりも珍しいパスを表す。並外れたパサーと普通のパサーを分け、そしてパスの難易度、予測可能性、そして積極的な攻撃への貢献をより良く評価するのに使用できる。まず、様々な選手のポジションに対するパスの一意性の分布を見る。

上記の密度プロットは非常に興味深い点を証明しており、またこの指標の潜在的に制限的な要素を強調する。GKはゲーム内で最も「一意的な」パサーである。最愛で尊敬されていないポジションを叫びたいが、残念ながらそうではない。GKがゲーム中で最もユニークなパサーだったとしたら、彼らはネットでプレーすることはできない。ここで実際に見ているのは、KNN検索の欠陥で、GKはフィールドでその他よりも物理的にパスの頻度が低いため、KNN検索での一致率はそれほど高くなく、したがってそのパスがわずかであっても「一意性」の値は高くなる。次にユニークなポジションカテゴリはFWである。これら2グループが他よりもユニークなパサーということは、実際に意味を成す。彼らはパスが最も少ない場所でパスを行っており、従ってゲーム中で最も一般的なパスではない。この潜在的な位置の偏りを思い出して、ポジションカテゴリの中で比較をし続ける。
各ポジションの「ユニークな」パスがどのように見えるかを見る。一意性値におけるduration変数の重要性を思い出して、2.5秒より長い期間を有する全てのパスを除外する。これらのパスは後ろからのロングボールになる可能性があり、便宜上ここでまとめる。

この時点で、指標が意味を成し始めていることを願う。最もユニークなパスは、空中高くのショートパス、狭い角度での奇妙な場所への高いパス、ピッチを横切る長いグラウンドパス、そして興味深い角度での低いパスである。この指標の有効性にかなり慣れ始めたので、この指標でできることを詳しく説明する。
最初の質問は、最もユニークな通行人は誰かである。これを調査するときは注意して進めなければならず、もし単純に一意性の中央値または他の分位点に基づいて選手をランク付けすると、パスの多い選手が少ない選手よりも一意性値が高くなる。代わりに、90分あたりのパスの90パーセンタイルよりもユニークである、成功したパスの数に基づいてパサーをランク付けする(これは元々の一意性フレームワークで選手がランク付けされた方法でもある)。
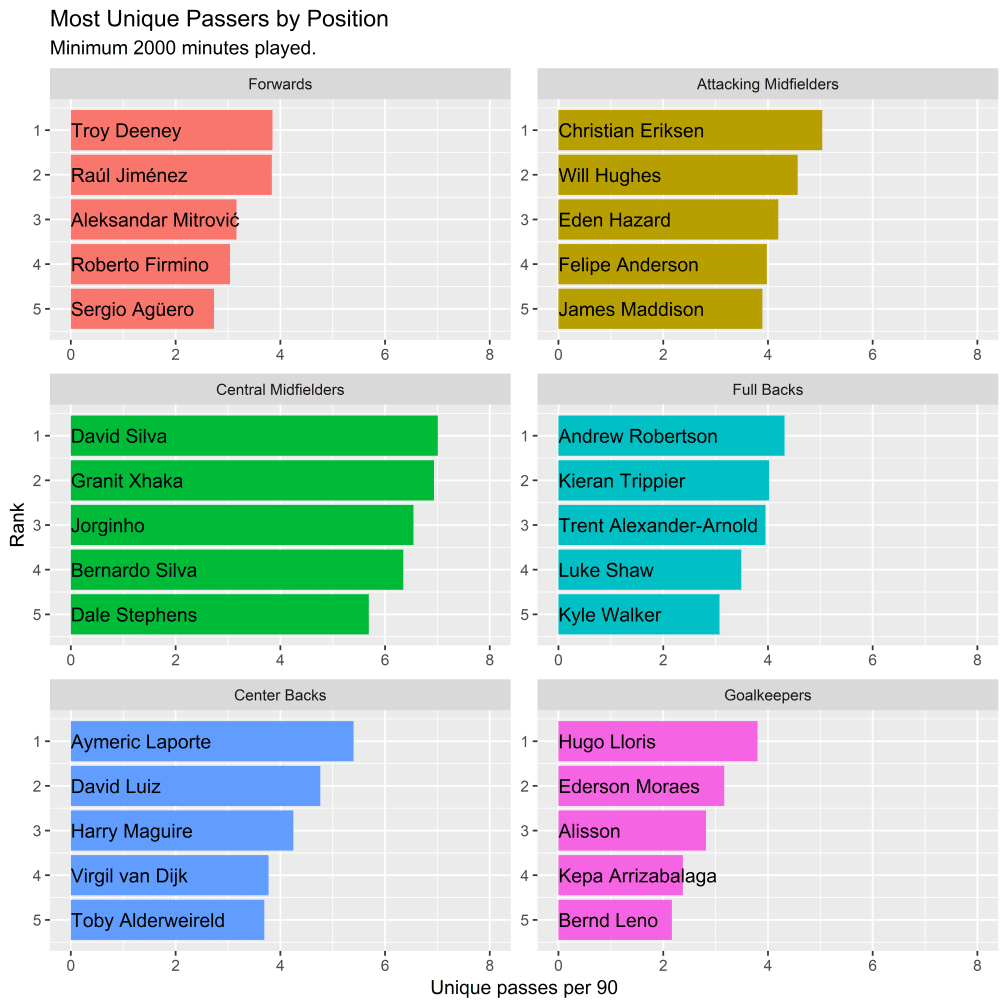
結果は分析部からのずっと厳密な検査に合格した。それは平均的な読者にとっては朝飯前に思えるかもしれないが、Euan、James、そしてクルーの名前をこっそり入れるのはそれほど簡単ではないことを保証する。それでも、まだいくつか質問がある。これらの選手はどうやってもっとユニークなのか。そして、それはなぜ重要なのか。最初の質問に答えるために、今シーズンのプレミアリーグで最もユニークなパサーであるダビド・シルバの試合例を見る。

上のプロットでは、これらのパスをビデオに合わせて、なぜ非常にユニークかを確認する。ご覧のとおり、パスは誰にとっても素晴らしいとは定義されないが、それらは確かに珍しいものとして際立つ。
それでは、もちろん次の質問に答えなければならない。なぜこれが重要なのか。そしてその理由は単純で、一意性指標は他の研究分野にも容易に拡張できる。何人かの選手は他よりも創造的か。そうである。どの選手かを見つけられるか。ちょうどそうした。これらのユニークなパスのうちどれが攻撃をより危険にしたかを見ることができるか。恐らく間もなくだが、今は間に合わない。成功率を予測するために一意性を使用できるか。決して尋ねないと思った。
パス成功率は次の応用である。簡単に言うと、パス一意性の影響は、パス成功率と関係があるか。この拡張は元のフレームワークで提案されたが、実際にテストするためのサンプルサイズが不足していた。十分幸運なことに指先でたくさんのデータを持っている。パス成功率を予測するためにパス一意性のみを使用して、単純なロジスティック回帰モデルを構築した。パス一意性指標の仮定された非線形性で、5自由度を有する自然スプライン(区分多項式)を使用してモデルを適合させる。

一意性とパス成功率の関係はかなり明白である。非常に一般的なパスでは、パス成功率と二次関係があり、一意性2.4または一意性の25分位数で90%以上の成功率のピークに達して、そして一意性3.5(一意性の70分位数)まで成功率の急激な減少があり、それほど劇的ではないが、一意性が増すにつれてパス成功率が低下し続ける。直感的に言えば、パスが一般的であるほど、成功率が高くなり、よりユニークであるほど、成功率が低くなる。
ROC(受信者操作特性)曲線を用いてモデルの精度を調べたところ、良好な結果が得られた。
ROC(受信者操作特性)曲線は、識別しきい値が変化するときの2値分類システムの診断能力を示すグラフ図である。
ROC曲線はさまざまなしきい値設定で、偽陽性率(FPR)に対して真陽性率(TPR)をプロットすることによって作成される。真陽性率は機械学習における感度、再現率、または検出確率としても知られる。偽陽性率は、フォールアウトまたは誤警報の確率としても知られており、(1 - 特異度)として計算できる。決定則の第一種過誤の関数としてのべき乗のプロットとして考えることもできる(パフォーマンスが母集団の単なるサンプルから計算される場合、それはこれらの量の推定量と考えられる)。したがって、ROC曲線はフォールアウトの関数としての感度である。一般に、検出と誤警報の両方の確率分布がわかっている場合、ROC曲線は、y軸に検出確率の累積分布関数(-∞から識別しきい値までの確率分布の下の面積)、x軸に誤警報確率の累積分布関数をプロットすることによって生成できる。
ROC分析はコストの文脈やクラス分布から独立して(かつ指定する前に)、最適と思われるモデルを選択し、最適とは言えないモデルを破棄するためのツールを提供する。ROC分析は、直接的かつ自然な形で診断の意思決定の費用対効果分析に関連する。
ROC曲線は、戦場で敵対象を検出するために第二次世界大戦中に電気技術者とレーダー技術者によって最初に開発され、すぐに刺激の知覚的検出を説明するために心理学に導入された。それ以来ROC分析は医学、放射線医学、バイオメトリクス、自然災害の予測、気象学、モデル性能評価などの分野で何十年にもわたって使用されてきており、機械学習やデータマイニング研究でますます使用されている。
ROCは基準が変化したときの2つの動作特性(TPRとFPR)の比較であるため、相対動作特性曲線としても知られる。
第一種過誤(Type I error)または偽陽性(False positive)と第二種過誤(Type II error)または偽陰性(False negative)は、仮説検定において過誤を表す用語である。第一種過誤をα過誤(α error)、第二種過誤をβ過誤(β error)とも呼ぶ。なお「過誤」とは、誤差によって二項分類などの分類を間違うことを意味する。
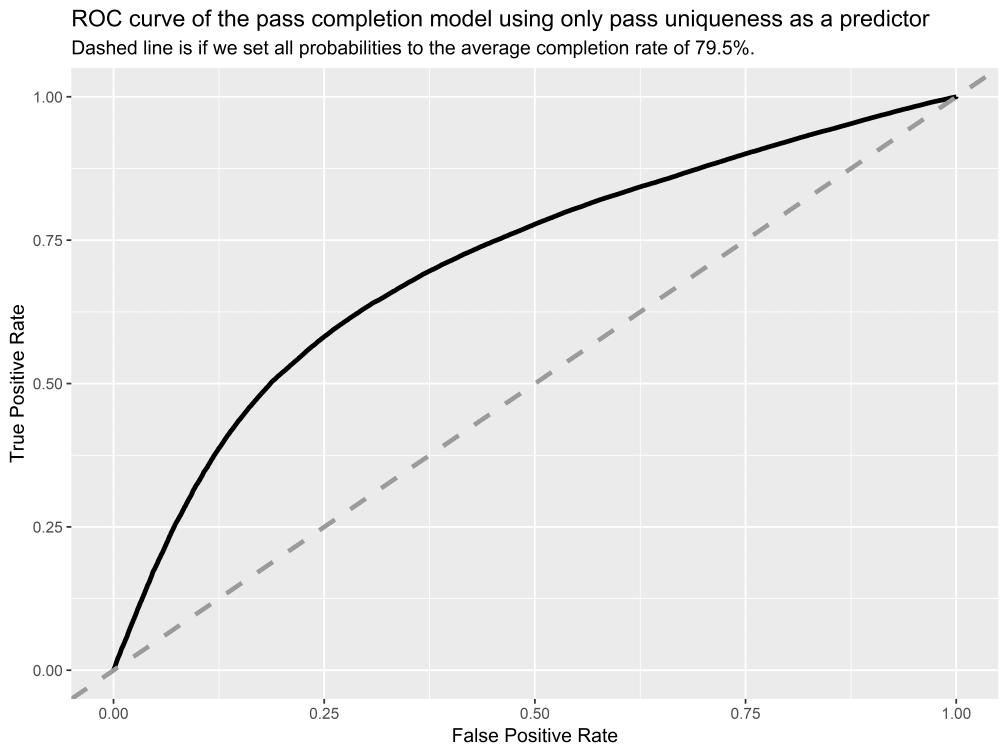
このモデルは、すべてのパスに平均成功率を割り当てるよりもパフォーマンスが優れるが、確実に改善の余地がある。曲線下の面積は0.71で、これはモデルがない場合の0.5よりもはるかに大きいが、場合は完全なモデルの1.0からかなり離れている。次の投稿では、より包括的なパス難易度モデルを使用して作業を進める。
この指標の拡張は無限であり、それらにさらに飛び込むことに興奮している。初心者にとって、一意性指標は、パス特性とパス難易度の間のかなり複雑な関係をすでに要約している。良かれ悪かれフットボールの規範に逆らうパサーを得る。これは最大の課題であり、ただボールを前進させるだけではなく、即座の報酬だけでなく、ポゼッション全体のビルドアッププレーを向上させる、ユニークで積極的に貢献するパスを抽出することである。間もなくこのシリーズの次回の記事へ続く。
**********
StatsBomb is unveiling three new (to us) passing metrics to better profile passers in professional football. Why passing metrics? Because this is football and passing is omnipresent. For better or for worse, the ubiquitous event may need even more attention than we’re already giving it. It is our objective through these metrics to evaluate a passer’s creativity, their predictability and frankly their overall passing ability. Thanks to some of the great work by peers made publicly available, we were able to put these together without too much time consuming innovation. We will release the metrics in a series of posts to spread out the joy and peak the eagerness for all you nerds. The first metric we are releasing today is “Pass Uniqueness”.
Pass Uniqueness Methodology
ここから先は
¥ 100
#フットボール統計学