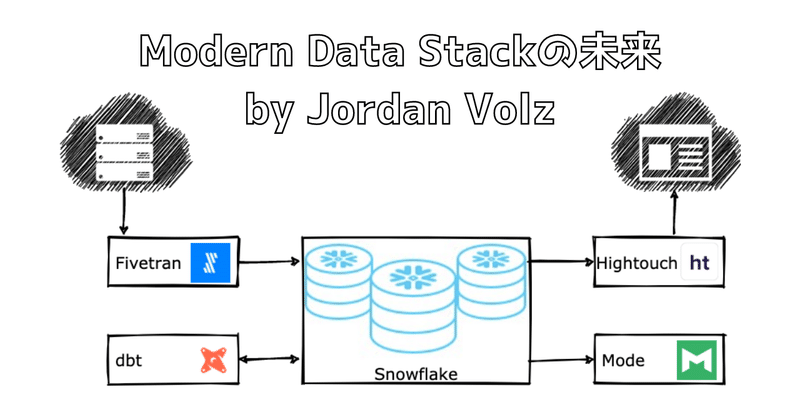
Modern Data Stackの未来 by Jordan Volz

日本でも"Modern Data Stack"という言葉を耳にする機会が少しづつ出てきました。アメリカを中心に、モダンデータスタックは、クラウドデータアーキテクチャの代表格として技術界で急速に普及していますが、その定義は時に曖昧かつ日本での情報は現在あまりありません。数少ない日本の記事の中でも、以下がとてもよくまとまっていて勉強になります。
今回のnoteでは、Modern Data Stackとは何か、どのようにして生まれたのか、そして今後どのような方向に進んでいくのかについて、大枠を理解するために以下の記事👇を翻訳したので展開します。
モダンデータスタックとは?
モダンデータスタックとは、一般的にクラウドネイティブなデータプラットフォームを構成するテクノロジーの集合体を指し、一般的には従来のデータプラットフォームの運用における複雑さを軽減するために活用されます。個々のコンポーネントは固定されていませんが、一般的には以下のようなものがあります。
Snowflake, Redshift, BigQuery, Databricks Delta Lakeなどのクラウドデータウェアハウス
ELTデータ変換ツール(ほぼ間違いなくdbt)
目標は、組織内のデータワーカーにとってデータが有用になるまでの時間を短縮することで、データを実用化することである。データを作成してから分析用倉庫に格納されるまで数週間かかる時代は終わりました。今では数時間から数分で届くようになりました。つまり、必ずしもすべてのコンポーネントが必要なわけではなく、オーケストレーション層としてAirflow, Dagster, Prefectなどの他のテクノロジーを選択する場合もあります。以下に、シンプルなアーキテクチャの例を示します。
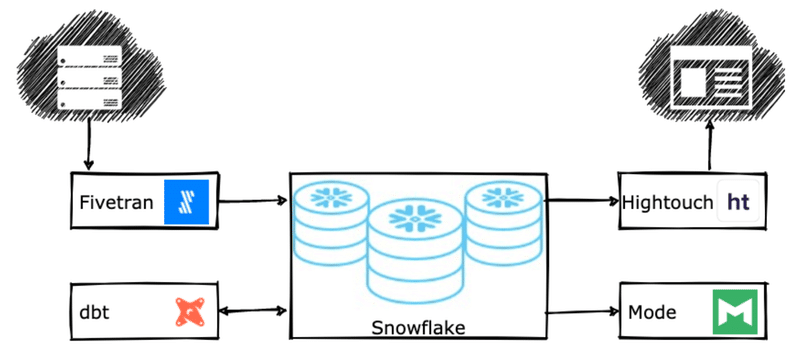
データプラットフォームをクラウドに置くだけでは、"最新のデータスタック "とは言えません。実際、ほとんどのクラウドアーキテクチャは、本当にこの分類に当てはまらないことに賭けてもいいくらいです。リフトアンドシフトプラットフォーム、クラウドデータレイク、特注ソリューションなどは、モダンデータスタックの本質を捉えておらず、オンプレミスと同じように不便に感じることが多いのです。では、何をもってモダン・データ・スタックの一部とするのでしょうか。このエコシステムに含まれるテクノロジーを縦断的に見ると、モダン・データ・スタックの核心に迫るいくつかの共通の性質があることに気づくでしょう。ここでは、モダン・データ・スタックに含まれるテクノロジーの主要な能力として、以下のものを提案します。
マネージドサービスとして提供される: ユーザーによる設定や構成が不要、または最小限で済み、エンジニアリングも全く必要ない。ユーザーは今日から始めることができ、マーケティング上のうわべだけの約束ではありません。
クラウドデータウェアハウス(CDW)を中心とする:一般的なCDWを使用すれば、すべてが既製品で「ちょうどよく」機能します。データがどこにあるかということにこだわることで、面倒な統合を排除し、ツール同士をうまく連携させることができます。
SQL中心のエコシステムでデータを民主化:ツールは、データ/アナリティクスエンジニアやビジネスユーザーのために構築されています。これらのユーザーは、企業のデータについて最もよく知っている場合が多いので、彼らの言語を話すツールを提供することで、彼らのスキルアップを図ることは理にかなっています。
エラスティックなワークロード:使用した分だけ支払う。大規模なワークロードを処理するために、即座にスケールアップすることができます。最新のクラウドでは、お金だけが規模の制限になります。
運用ワークフローにフォーカスする:ポイント&クリックのツールは、ローテクユーザーにとっては便利ですが、本番環境への実行可能なパスがなければ、すべて意味がありません。最新のデータスタックツールは、自動化をコアコンピタンスとして構築されていることが多い。
最新のデータスタックのユーザーは、日常的にその素晴らしさを賞賛しています。最新のデータスタックを採用することで、企業はセットアップが簡単で、使い勝手がよく、本番ワークフローを作成するための専門知識がほとんど必要ない、低コストのプラットフォームを手に入れることができます。多くの企業がこのトレンドに乗り、決して後戻りできない理由は明らかです。
はじまりと歩み
当初は洞窟の壁に絵を描いてデータを保存していました。その後、1970年にエドガー・F・コッドがリレーショナルデータモデルを発明し、「A Relational Model of Data for Large Shared Data Banks」を発表し、RDBMSブームが始まったと言われている。現代の基準からすると、この新しい技術は軌道に乗るのが遅かったが、その後数十年の間に多くの企業がデータベースを顧客に提供するようになった。IBM、Oracle、Microsoft、Teradataなどだ。また、データ統合ツールやレポート作成ツールなど、データベースでの作業を容易にする新しい技術も登場し、SQLという新しい言語が生まれたことで、データベース内のデータを比較的簡単に(つまり、コーディング不要で)扱えるようになりました。そして何十年もの間、企業が保存する少量のデータで解決しようとする大半のユースケースは、オンプレミス型データベースで完全に事足りました。
その後、ムーアの法則、インターネットの誕生、ユーザー生成コンテンツなどにより、一般企業が大量のデータを保存・分析しようとすることは、まったくおかしなことでも、ばかばかしいほど高価なことでもない、と考えられるようになりました。これは企業にとっては喜ばしいことですが、大規模なデータ処理を想定していないRDBMSシステムにとっては、あまり良いことではありませんでした。2000年代には、大量のデータを処理するために作られた新しいタイプのテクノロジー・システムが数多く登場しました。Hadoop、Vertica、MongoDB、Netezzaなどだ。これらのシステムは、一般的に分散型 SQL または NoSQL で、サーバーのクラスタ間でデータ操作を並列化することに重点を置いており、以前のシステムと同様にさまざまなユースケースを処理できるように急速に進化しました。そしてついに、企業は大量のデータを処理するための現実的な選択肢を手に入れたのです。
ビッグデータの支配は10年も続かず、2010年代前半から半ばにかけて、急成長するクラウド技術によって破壊されました。従来のオンプレミス型のビッグデータ技術は、クラウドへの移行に苦労し、これらのプラットフォームの運用・保守に必要な複雑さ、コスト、専門知識は、より軽快で俊敏なクラウドプラットフォームに太刀打ちできなかったのである。クラウドデータウェアハウスは、以前のRDBMSと同じようにシンプルで使いやすく、DBAのチームも不要で、さらにその多くがビッグデータ型のワークロードを処理するために構築されています。この変化は、ビッグデータソリューションに必要な人員が不足している中小企業から始まり、SaaS指向のクラウド環境が参入障壁を劇的に低下させたため、瞬く間に大企業も弾力的なワークロードによる簡素化とコスト削減の動きに乗ってきました。コンピュートとストレージを分離し、コンピュートのみを使用することが再び流行となったのです。 一夜にして、誰もがデータプラットフォームをクラウドに移行するようになったのです。
2010年にGoogleのBigQueryで始まり、その後すぐにRedshiftとSnowflakeが続きました(2012年)。その直後から、クラウドネイティブの隣接技術のエコシステムが出現し始めた。BI (Chartio - 2010, Looker - 2011, Mode - 2012), データ統合 (Fivetran - 2012, Segment - 2013, Stitch - 2015), データ変換 (dbt - 2016, Dataform - 2018), そしてリバースETL (Census - 2018, High Touch - 2018)です。これらのクラウドネイティブなテクノロジーは、旧来のものと比較して、上記のような多くの利点がありました。組織が新しいデータテクノロジーを採用する際に、家を掃除し、使いやすさと利用ベースの価格を優先している場合、レガシーベンダーがサーバーベースやユーザーベースの価格で説得力のあるストーリーを語り続けることは困難です。特に、新しいベンダーの勢いが著しく、月々数千ドル、あるいはそれ以下のコストで利用を開始できる場合、標準ツールセットをクラウドに移行するために6、7桁の契約書にサインすることを正当化することは困難でしょう。
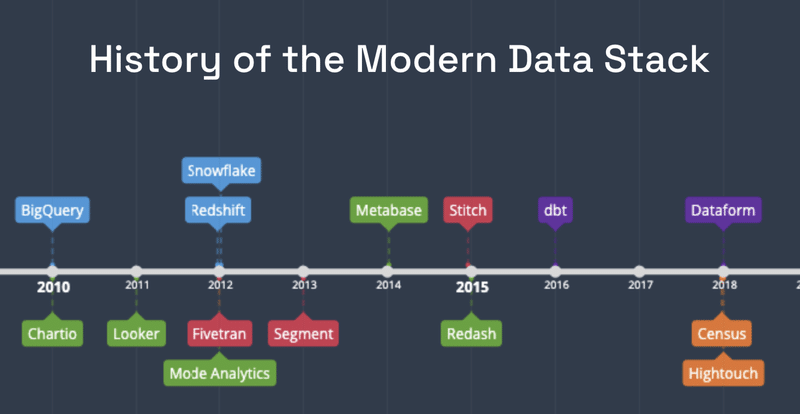
クラウドデータウェアハウスは、それ自体、便利ではありますが、変革にはなりません。これらのプラットフォームの周りに生まれたエコシステムが、最新のデータスタックを実際に作り上げているのです。資金をかけず、アーキテクチャのレビューやパイプラインの統合に何ヶ月もかけず、ゼロから本番稼動まで1週間もかからずに実現できるのです。このような道を歩んできたデータリーダーは、組織がデータイニシアチブを迅速に実行し始めると、モダンデータスタックの追い風を感じています。データウェアハウスの最初のアイデアが生まれてから半世紀が経ち、今やデータウェアハウスは堅牢で活用しやすいプラットフォームとなり、どんな企業でも手に入れることができ、データ分析における最高のハイテク企業と同等の競争力を持つことができるようになりました。
イノベーションの必要性
トリスタン・ハンディが最近、最新のデータスタックの状況についてブログを書いた。彼の素晴らしい投稿は一読の価値があり、大規模なパラダイムシフトにつきものの、イノベーションの周期的な性質を浮き彫りにしています。私たちの場合、現在のモダン・データ・スタックの多くの部分は2010年代前半から半ばにかけて立ち上げられましたが、その後の数年間は少しペースダウンしています。この背景には、企業がテクノロジーの導入とユースケースの実行に忙しかったため、次のイノベーションの波が起こる前に、生産性とROIを十分に評価するための時間が必要だったという理由があります。同様に、イノベーターも、新しいイノベーションに努力とリソースを注ぎ始める前に、ユーザーからのポジティブなシグナルを確認する必要がある。そうでなければ、死んだプラットフォームでイノベーションを起こすリスクを負うことになるのだ。そうでなければ、枯れたプラットフォームでイノベーションを起こすリスクを負うことになる。技術が機能するという肯定的な補強が得られれば、新しいアイデアを探求するための門が開かれる。
Handy氏は、今後5年間は最新のデータスタックにさらなる革新が起こるはずだと結論付け、探求の機が熟したと考える5つの主要分野を挙げています。ガバナンス、リアルタイム、フィードバックループの完成、データアクセスの民主化、そして垂直的な分析体験だ。私は、最新のデータスタックが今後数年間で大きな変化を遂げるというHandy氏の大前提に同意しますが、次のセクションでは、別の5つのホットスポットを提示します。また、現代のデータスタックが長期的に生き残るためには、進化することが不可欠だと考えています。現代のデータスタックの成長は、ユーザーにとって単なる「いいとこ取り」ではなく、「必須」なのです。
イノベーションの必要性は、いくつかの理由から重要です。歴史的に、最新のデータスタックは小規模な企業やクラウドに精通した新興企業に素早く採用されてきました。これらの企業は、データプラットフォームの構築と保守に必要な人員が不足しており、数十年にわたる技術的負債に悩まされることもなく、移行作業にも疲弊していないため、その強みはこれらの企業のリソースに生かされているのです。このようなアプローチを採用する企業が増えるにつれ、これがクラウドでデータを扱う正しい方法であることを示す証拠が増えています。しかし、さまざまなデータ、複雑なデータチーム、数十年にわたる古い技術がクローゼットに眠っている大企業にとっては、現状のモダンデータスタックは使用例が狭すぎ、AI、データガバナンス、ストリーミングといった魅力的な機能が欠けていると感じるかもしれません。 モダン・データ・スタックが単なるデータ・プラットフォームの最新トレンドとして生き残るためには、大企業にアピールする必要があります。そのためには、ベンダーは大企業をその翼下に収めるために、主要なエンタープライズ・ギャップに対処しなければなりません。それができれば、クラウドデータプラットフォームの第一人者としての地位は揺るぎないものになるだろう。そうでなければ、大企業は他のアーキテクチャパターンに従ってクラウドを導入することを選択するのではないでしょうか。
第二に、最新のデータスタックは、分析ユースケース以外の、より複雑なユースケースを扱えるように進化しなければなりません。しかし、より複雑なユースケースで異なるプラットフォームの導入が必要になれば、ビジネスリーダーがより複雑なユースケースに対するソリューションを求めるようになり、人々はすぐにモダンデータスタックへの興味を失ってしまうでしょう。単一のプラットフォームでデータのユースケースの大部分を簡単かつ効率的に処理できるという考えは、過去10~20年の間、確かにホットなマーケティングコンセプトでしたが、モダンデータスタックはこの点で提供できる可能性があるようです。
最後に、モダンデータスタックの成長を語る上で、最大手のインフラ独立系ベンダー2社に触れないわけにはいきません。SnowflakeとDatabricksです。Snowflakeはもちろん、モダンデータスタックにうまく適合し、「Data Cloud」製品によって、その周りに生まれた広大なエコシステムにも適合しています。一方、Databricks(とDelta Lake)はビッグデータ技術の領域から生まれたものだが、クラウドネイティブであることで適切に差別化し、その結果、報酬を獲得してきたのだ。両社は、全く異なるアプローチでスタートしました。SnowflakeはSQLテクノロジーを基盤としており、CDWの中で最も簡単に導入・運用できたことで成功を収めた。パートナーは、最小限のセットアップで動作し、顧客が価値を得るまでの時間を短縮する、意見の一致した製品を持ち込んでいます。一方、Databricksは、ユーザーが同社が提供するビルディングブロックを利用し、効率的なデータパイプラインを構築できるような、より一般的なアプローチを信じています。両社の最近の発表では、それぞれが相手の領域に向かって疾走しています。したがって、これらのアプローチが統合され、すべての企業にとって有効なプラットフォームとなることが運命づけられていることが、本質的に理解されています。
モダンデータスタックv2
このようにデータスタックが成長している現在、イノベーションの機が熟した5つの重要な領域があると私は考えています。
人工知能
データ共有
データガバナンス
ストリーミング
アプリケーションサービング
これらは、既存のユースケースから自然に発展した複雑なユースケースを数多く表しており、企業への対応力を強化し、不可避の破壊的要因からプラットフォームを将来的に保護するものです。以下、それぞれについて順番に説明していきます。
人工知能
過去10年間にデータサイエンスに携わってきた人なら、「データサイエンス ニーズの階層構造」という以下のようなものを知っているのではないでしょうか。
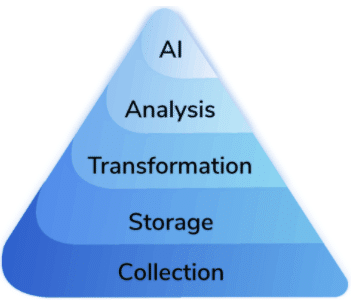
この図は、AIの問題を解決できるようになるために必要な依存関係を示しています。もし企業がデータをどのように収集し、保存し、修正しているかについての確固たるストーリーを持っていなければ、データサイエンス・プロジェクトは開始する前に破滅してしまいます。現代のデータスタックにとって好都合なことに、この図の最初の4つの層は、開始するために必要なツールを完璧に描写しています。
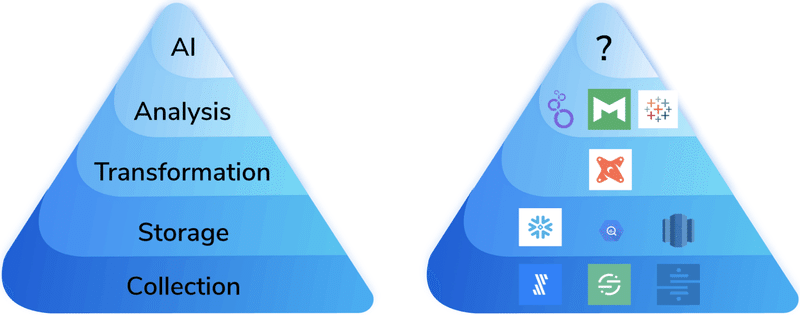
AIは、多くの企業にとって大きな成長機会です。2030年には、事実上あらゆる分野のリーディングカンパニーが、企業全体でAIを実現することを優先していると確信しています。しかし、一般的な企業がデータサイエンスの取り組みを有意義な本番環境に移行できていないことを嘆く記事には事欠きません。Andreesson Horowitzのこの図が明らかにしているように、これは時間が経つにつれて容易ではなくなってきています。
では、なぜ最新のデータスタックは人工知能の理想的なプラットフォームなのでしょうか?詳細については今後の記事で紹介する予定ですが、要点は、最新のデータスタックは、新しいタイプのAIプラットフォーム、つまり運用AIを根本的に簡素化する宣言型データファーストAIプラットフォームにとって格好の着陸地点であるということです。私たちはContinual社でこのようなプラットフォームを構築しており、これが将来、企業がAIユースケースを実行するために選択する主な方法になると考えています。このデータファーストのアプローチは、Apple(Overton)やUber(Ludwig)といった企業によって開拓されており、パイプラインやモデル中心の従来のMLプラットフォームとは異なるAIへのアプローチを提供しています。データファーストのシステムは、AIの自動化と運用化を優先し、新しいユースケースの構築と保守、そして本番環境へのプッシュにかかる時間を大幅に短縮します。
Michael Kaminskyは昨年、最新のデータサイエンス・スタックがどのようなものであるかについて素晴らしいブログを書いていますが、私たちはこれを宣言型システムで最も完全に実現できると考えています。AIは企業にとって大きな成長のベクトルであり、この分野でイノベーションを起こさなければ、最新のデータ・スタックは存在意義を維持するのに苦労することになるでしょう。同時に、レガシーなMLシステムは、モダンなデータスタックの主要な原則とは相容れないものであり、また、すぐに複雑さに溺れてしまうことも実証されています。私たちは、新しいベンダーの波が、運用AIを簡単かつ堅牢にするプラットフォームによって、AIの世界を破壊する準備が整っていると考えています。モダン・データ・スタックにおけるAIのビジョンについて詳しくは、私たちの立ち上げブログをご覧ください。

データ共有(Data-as-a-Service)
CensusやHightouchのような企業は、ユーザーが簡単かつ迅速にデータをクラウドデータウェアハウスから、それを必要とする下流アプリケーションに移動できるようにする、非常に貴重なサービスを顧客に提供しています。多くのユースケースにおいて、これは不可欠であり、専用のツールがなければ、企業はカスタム統合スクリプトを書くか、維持と実装が困難な特注ツールを作るしかないでしょう。
もう一つ、関連するユースケースとして、データの共有があります。例えば、販売業者がアクセスして自社のウェブサイトで使用できる商品説明のデータベースを保持するような単純なものです。現在、データへのアクセスはおそらくAPIとして提供されており、その設定と維持にはエンジニアリング作業が必要で、APIを消費する各企業にも同様に作業が必要です。クラウド時代には、このデータベースを同じプラットフォームで利用できるようにすればよいのではないでしょうか。SnowflakeのData Marketplaceの背後にあるアイデアは確かにそれだ。Databricksも最近Delta Sharingを発表したが、これは同様の目標を達成することを目的としている。データプラットフォームで直接データにアクセスできるようにすることで、これらの企業はデータ統合の要件をゼロにし、ユーザーはデータを自分の組織ですぐに実行可能にすることができます。
これらのソリューションは、たまたま同じデータプラットフォームを利用している顧客にとっては素晴らしいものですが、現実には様々なプラットフォームベンダーにまたがって活動している企業とやり取りをすることが多いでしょう。このような場合、参加するプラットフォーム間でデータへのアクセスを仲介し、データセットのアップロードと管理を容易にするツールがあれば、非常に便利です。歴史的に見ると、こうしたデータ・アズ・ア・サービス企業は、外部で使用するAPIの構築を自動化することに力を注いできました。しかし、最新のデータスタックの台頭により、それぞれのプラットフォームのネイティブな共有メカニズムの中で仕事をしている企業にとって、こうしたプラットフォーム内のオプションを活用する新しいニーズがあることが想定されます。
データガバナンス
大企業が最新のデータスタックを利用できるようにするためのトピックに戻りますが、データガバナンスの重要性はいくら強調してもし過ぎることはありません。企業によっては、非常に多くの異なるデータセットを抱えており、ガバナンスツールなしにデータを追跡し、意味を理解することは事実上不可能でしょう。しかし、優れたデータリーダーは、発見、観測、カタログ化、リネージ、監査など、あらゆる面で優れたデータガバナンスツールの重要性を一貫して強調しています。
優れたガバナンスツールがなければ、現代のデータスタックは、大企業やその巨大なデータ量にとって、あまりにも混沌として扱いにくいものとなってしまう可能性があります。ガバナンスは、組織のデータに秩序を与え、発見とコラボレーションを可能にする自然な障壁を取り除くことができます。
また、大企業はクラウドベンダーに対してマルチベンダーアプローチを選択し続ける可能性が高く、データプラットフォームを横断的にサポートするメタデータツールは大きなROIをもたらし、プラットフォームベンダー自身が開発したどんな自社製ツールに対しても抵抗力があることを意味しています。
最新のデータスタックの文脈の中でこの問題を解決しようとする企業は後を絶ちません。この競争はまだ終わっていないが、大きな可能性を見せているベンダーがいくつかある。Monte Carlo Data, Stemma, Metaplane.などです。
ストリーミング
ストリーミングデータは、まさにクラウドデータウェアハウスの聖杯と言えるでしょう。最近のデータスタックのユーザーと話をしていて、リアルタイムのユースケースについて尋ねると、最もよく返ってくる答えがあります。「リアルタイムで物事を行うなんて想像もつかない」というものです。しかし、一般企業でも簡単に使えるようになれば、この機能は素晴らしいものになるという認識があるのは確かです。もしCDWベンダーがデータへのリアルタイムアクセスを説得力を持って提供できれば、多くの企業にとって大きなゲームチェンジャーとなる可能性がある。
しかし、企業がデータのユースケースを進めていくうちに、必然的にストリーミングデータを実行する必要性に行き着くことになる。今日や明日ではないかもしれませんが、いずれはストリーミングデータを扱えない企業が扱える企業に負ける時代が来るでしょう。つまり、現代のデータスタックは、他のテクノロジーとうまく調和するエレガントなソリューションを提供できるか、あるいは顧客にリプラットフォームを強いるかという分かれ道にいるのです。後者の場合、プラットフォーム全体に対する信頼が損なわれるため、前進するための方法を見つける必要があります。
AIと同様、ストリーミングのユースケースも非常に複雑になる傾向があり、これはベンダーにとってCDWを中心としたユースケースを簡素化する大きなチャンスとなります。現在のストリーミング技術は、ソフトウェア開発者か時間の魔術師のどちらかを想定しているようで、データウェアハウスと同じように、ストリーミングの世界ではまだ革命が起きていません。インフラについて考える必要がなく、データを新しいプラットフォームに移動させ、標準的なSQLクエリでシンプルかつ確実にライブデータを取得できるソリューションを提供できる人は、大いに祝福されるでしょう。
今日、様々なベンダーがすでに機能を提供しています。SnowflakeにはSnowpipeがあり、新しい機能を示唆しています。BigQuery、Redshift、Snowflakeには(重大な制限があるとはいえ)マテリアライズド・ビューがあり、Databricksは構造化ストリーミングをサポートしています。標準的なCDWベンダー以外では、ConfluentがksqlDBを提供し、 Decodableがストリーミングデータエンジニアリングの再構築に取り組んでおり、Materializeは新しい会社だが、よりモダンなデータスタックにネイティブに近い位置付けだ(dbtプラグインもある!)。ストリーミングのための独立したプラットフォームが、より大きなモダンデータスタックのストーリーにどのようにうまく適合していくのか、私はどうしても理解できないのだが、可能性はある。
アプリケーション サービング
最新のデータスタックへの要望リストの最後の項目は、アプリケーションの提供です。そうです、最終的には、あなたのデータプラットフォームがあまりに素晴らしいので、人々は、彼らが書いてきたキラーアプリケーションに必要なすべてのデータがそこに含まれていることに気づき、それにフックアップしたいと思うようになるのです。このような場合、一般的に私たちが乗っている車は止まってしまうのです。クラウドデータウェアハウスはOLAPのカテゴリーに属します。一方、ライブアプリケーションは、高い同時実行性と低いレイテンシーを必要とし、これはOLTPのカテゴリーに属します。これは計算にはなりません。
特に読み取り専用のワークロードには、回避策があります。今日、賢明な方法は、アプリケーションに適したシステムにデータをコピーすることです。Redis、Cassandra、Memcached、SingleStore、...また、新しい問題に対して新しいプラットフォームを導入することになり、システムの複雑さと負担が増しています。既存のデータから直接アプリケーションを提供できるようにするために、最新のデータスタック内のイノベーションが歓迎されることは容易に想像がつきます。
Netflixは最近、このジレンマに対してBulldozerと呼ばれるツールでユニークな見解を示しましたが、これは実際に現代のデータスタックに非常にうまく適合するものでした。このツールをお気に入りのCDWに適用して、ユーザが1〜2回クリックするだけで、低遅延のアプリケーション配信のためにデータを「ステージング」できるようにする方法は、容易に想像がつくだろう。
Snowflakeは最近、Snowflake Data Cloudをデータ・アプリケーションに使用することに大きな関心を寄せており、これは彼らが注目しているユースケースであるように思われます。 詳細は未定です。
次はどうなる?

最新のデータスタックを採用した場合、今後数年間はエキサイティングなイノベーションが待ち受けていることでしょう。 重要なのは、開発・保守コストを削減しながら、ビジネスインパクトをもたらす最善のコンポーネントのセットを組み立てることです。Continualでは、AI/MLが最新のデータスタックに導入すべき次の明白なワークロードであると確信しています。マーケティングをパーソナライズするための顧客解約予測や、利益率を向上させるための需要予測のメンテナンスであっても、パイプラインジャングルや複雑なインフラストラクチャを提供する必要はないはずです。 もしそれが魅力的に思えるなら、Continualへの早期アクセスをリクエストして、AI/MLがモダンなデータスタック上でどのように見えるかをご覧ください。
最後まで読んで頂きありがとうございました。これまでのAI/BIの知識に加えて、この領域も少しずつ勉強していこうと思います。
この記事が気に入ったらサポートをしてみませんか?