pandas高速化の新星、FireDucksに迫る

本記事はFireDucksユーザー記事シリーズの第1弾です.本記事はBell様に執筆して頂きました.
データ処理と分析をする際に、多くの方がPythonを使ていると思います。中でも、PandasライブラリはPythonを用いたデータ処理においてなくてはならないものになっています。Pandasには便利な関数が多数あり、複雑なデータセットを効率的に処理・分析することができます。
しかし、Pandasの使用にあたっては、大規模なデータセットを扱う際にパフォーマンスが課題になることがあります。特に、データの読み込みや変換、集約などの処理を行う際、処理時間が問題となることが少なくありません。このような背景から、色々な手段を用いてより高速に処理を行う方法が試みられてきました。
NECが開発した「FireDucks」は、データ処理の世界に新たな風を吹き込んでいます。FireDucksは、PandasのAPIをベースにしつつ、内部処理の最適化を図ることで、大幅なパフォーマンス向上を実現することを目指したライブラリです。特に、大規模なデータセットに対する処理を高速化するために設計されており、多くのデータサイエンティストやエンジニアにとって、Pandasに代わるツールとして期待されています。
FireDucksとは?
FireDucksは、Pandasの高速化を目指して開発された革新的なツールです。データ処理の高速化を実現するために独自の最適化が施されており、大規模なデータセットに対しても高速な処理が可能となり、Pandasの代替としても注目されています。
Pandasの課題とFireDucksの解決策
Pandasは柔軟性に優れていますが、大規模なデータセットに対してはパフォーマンス上の課題が生じることがあります。特に、ループ処理や大量のデータの読み込みにおいて処理速度が低下することがあります。ここでFireDucksが登場し、そのパフォーマンスを向上させる解決策を提供します。
FireDucksの特徴
FireDucksは、Pandasの高速化に向けた新しいアプローチを採用しています。以下は、その特徴です。また、既存のプログラムをほとんど変更することなく利用できる利便性も兼ね備えています。
最適化されたアルゴリズム: FireDucksでは、ユーザーが利用するAPIとその実行は中間言語を境目として完全に独立しています。バックエンドは柔軟に切り替えられ、環境変数を使って変更することができます。これにより、ユーザープログラムの変更を必要としません。
マルチスレッド化されたバックエンド: FireDucksのベータ版には、マルチスレッド化されたCPUバックエンドが搭載されています。Apache Arrowを採用し、並列処理機能を最適化するための独自の最適化を行っています。
実行時コンパイラの最適化: FireDucksでは、Pythonプログラムを中間言語に変換して実行し、データフレーム専用の中間言語を使用します。実行時コンパイラはプログラムの意味を理解し、データフレーム処理に特化した最適化を実行します。
FireDucksの利便性: FireDucksの利用方法は2つあります。インポートフックを使用してpandasを自動的にfireducksに置き換える方法と、fireducks.pandasモジュールを明示的にインポートする方法です。これらの方法を使用することで、既存のプログラムを修正せずにFireDucksを利用できます。
使い方
インストール
FireDucksベータ版はpypi.orgで公開されていて、下記のようにpipでインストールできます。
pip install fireducks利用方法
インポートフック
FireDucksにはfireducks.imhookというユーティリティモジュールが含まれており、Pythonスクリプト内のimport pandasを自動的にimport fireducksに置き換えて実行することができます。
python3 -m fireducks.imhook your_script.pypandasプログラムを全く修正せずにFireDucksで動かすことができるため,多数のPythonスクリプトから構成されるプログラムを動かす場合にはこちらの方が便利でしょう。
明示的なインポート
明示的なインポートを行うことで、pandasの代わりにfireducks.pandasモジュールをインポートして直接使用することができます。
# import pandas as pd
import fireducks.pandas as pd小規模なプログラムやJupyter NotebookなどでFireDucksを使用する際に便利です。
パフォーマンス比較
FireDucksを使用した場合と通常のPandasを使用した場合のパフォーマンスを比較してみましょう。sklearn.datasets.fetch_kddcup99というデータセットを使用し、いくつかの処理(groupby、sort、merge、concat)を行った際の処理時間を計測しました。その結果、FireDucksを使用することで処理時間が大幅に短縮されました。
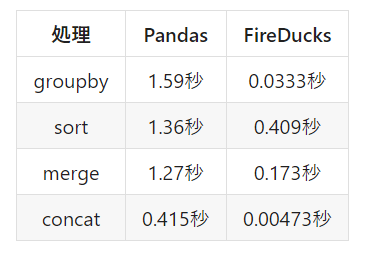
また、公式ページのベンチマークでもPandasのみならず、Polarsなどと比較しても良好な結果となっていることがわかります。
まとめ
FireDucksは、Pandasの高速化を目指してNECによって開発された画期的なツールです。その革新的なアプローチと技術的な進歩により、大規模なデータセットに対する処理速度を大幅に向上させることができます。既存のプログラムへの導入も用意にできます。データ処理のパフォーマンスを向上させたいデータサイエンティストやエンジニアにとって、FireDucksは非常に魅力的な選択肢であり、その開発と普及により、データ分析の効率と可能性がさらに広がることでしょう。試してみる価値のあるツールなのではと思います。
この記事が気に入ったらサポートをしてみませんか?