
コロワク混入DNAの推定量について

「ワクチンにDNAが混入していることは周知の事実」ということはコンセンサスが得られているようですが、何がどの程度入っているのか?については正確な測定方法が確立していなくて各国の多くの研究者がいろいろ試行錯誤している状況です。
その中で、qPCRを使って推定するアプローチがあります。この方法で推定されたものが、全体混入量のごくごく一部であるということをイメージできている人は多くないんじゃないでしょうか?
ということで今回はそれについて説明をしてみようと思います(*´▽`*)
ざっくりPCR説明
PCRの説明をする前にDNAについて。DNAは「G(グアニン)」「T(チミン)」「A(アデニン)」「C(シトシン)」という4種類の塩基でできています。このそれぞれはくっつく相手が決まっています。
A と T
C と G
なので、例えば、DNAの一方の鎖が
AATCGCGATTATCG
だとするとその相手は
TTAGCGCTAATAGC
と決まります。下図のようにA-T , C-Gが組み合わさっていますね。

PCRはDNAを複製してその量を検出するものです。複製の過程は以下です。
①温度を上げます
すると2本鎖DNAが2本の一本鎖DNAに分かれます。

②次に温度を下げます
すると①で別れた2本鎖が元に戻ろうとしますが、プライマーと呼ばれる塩基配列をあらかじめ溶液に入れておくと、元に戻るよりも先に①の一本鎖DNAにくっ付きます。(このプライマーは①の一本鎖DNAのある部分に結合する配列としてあらかじめ決めています。下の図にあるように右からと左から修復していく2対のプライマーが必要です)

③温度をちょっと上げます
するとプライマーがくっ付いた部分を起点にDNAが合成されていきます。
(なので、溶液中には材料となるG,T,A,Cをたくさん溶け込ませています)

これで最初のDNAが2倍になりました。

上記の一連の操作1周がいわゆるCtです。(※厳密にCtとサイクル数は違うみたいだけど素人が把握するのに違いを意識する必要はないと思います)以降、①ー>②ー>③を繰り返せばDNAが倍々になっていきます。
Ct:1ー>DNAが元の2倍
Ct:2ー>DNAが元の4倍
Ct:3ー>DNAが元の8倍
:
Ct:10ー>DNAが元の1,024倍
:
Ct:20ー>DNAが元の1,048,576倍
:
Ct:30ー>DNAが元の1,073,741,824倍
:
Ct:40ー>DNAが元の1,099,511,627,776倍
グラフにすると、下みたいなグラフになります。

グラフは最終的には傾きが小さくなって横這い近くになり、これをプラトーといいます。プラトーに達する理由はいくつかありますが、PCR産生物が多くなってくるとプライマー濃度が低くなりプライマーとくっつくよりも、2本に分かれたDNAの再結合のほうが打ち勝つためです。
ちなみに、コロナウイルスなどは一本鎖のRNAなのでわざわざDNAにしてPCRにかけて検出をしています。というわけで、PCRによってプライマーで挟まれたDNA領域を増幅させることがわかりました。
ワクチン中のDNA量の推定
ワクチンの中のDNA量推定の話に入ります。mRNAをつくるのに使用された環状プラスミドのベクターは公開されており、鋳型となるスパイクのDNA配列がわかっていいるので、そこからプライマーを決めてPCRすれば、該当する部分のDNAを増幅できるわけです。どこをプライマーとするか?区間は?などは実験者のセンスによると思うのですが、今回のように断片化したDNAを測定しようとすれば、おのずとプライマーとなる区間は短いほうがいいということになります。(区間内の範囲内で切断されたDNA断片を増幅できないので、そのような断片をなるべく排除するため)
さて、プライマーを決めてPCRしたら何やらグラフが立ち上がってきました。しかし、PCRのグラフはCtと産物量しかわかりません。ではどうするかというと、既知の濃度の別の溶液をPCRして、増幅させた時のグラフと重ね合わせることで、推定するのです。この既知の溶液のPCR結果がいわゆるリファレンスといわれるもので、ぴったり重なっていなくても、それに近いグラフになれば近い濃度だろうと推定できるというわけです。荒川先生のNoteからグラフを引用します。下のリファレンスは1ng、100pg、10pg、1pg、100fg、10fg、1fgとなっていて、ng:ナノグラム、pg:ピコグラムなど馴染みのない単位ですが10倍幅で実験されています。そのためほぼ均等の幅で曲線が現れています。これと実験で得たワクチンのスパイク蛋白PCRのグラフを重ねれば、おおよその濃度が推定できるというわけです。たとえば、100pgと10pgの間にグラフが重なれば、濃度はおおよそ50pgだなという感じです。このリファレンスグラフはとても重要です。何せ、これが間違っていたら知りたい濃度推定もまちがえてしまうので・・・。
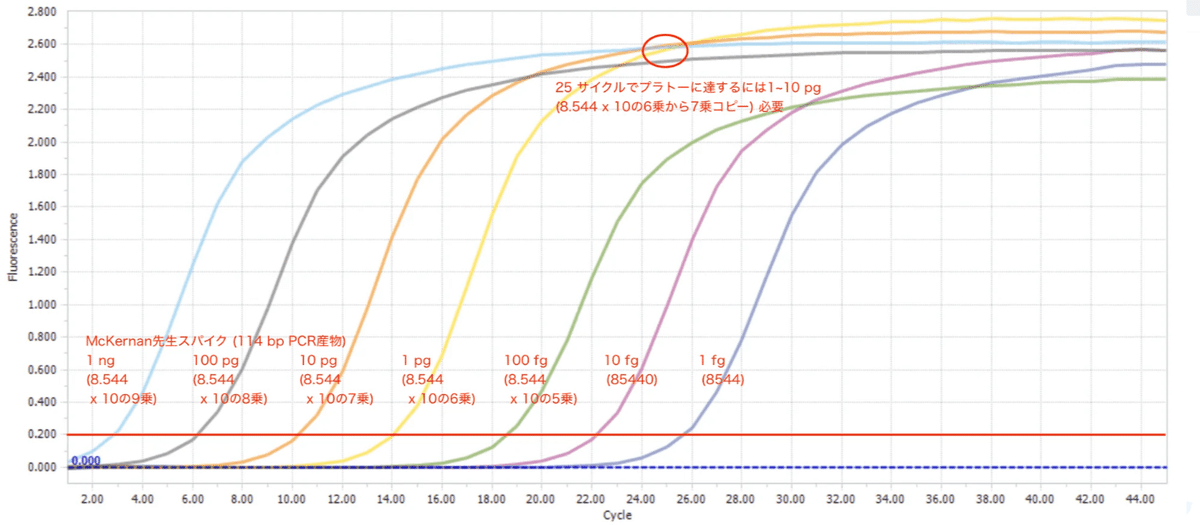
はい。というわけで、PCRによる未知の溶液内のDNA量の推定ができました。ただ、これはどんな意味をもっているでしょうか?
「このワクチンには●● ピコグラムのDNAが入っていた!!!」ではないんです。なぜって?思い出してください。PCRは溶液中の既知のDNAを増幅させただけです。他の断片の濃度がまったく測定されていません。プラスミドベクターは公開されているので、残りの部分のDNAについてもプライマーを用意してPCR増幅ー>リファレンスと比較など網羅的にやらないと全体のDNA混入量はわからないはずです。ただそれって現実的ではないですよね。いったい何パターンやればいいのかという話もありますし。
ってことで、qPCRでの推定量は、mRNAスパイク蛋白のほんの一部のみを推定しただけにすぎません。推定したスパイク蛋白DNAの一部に対して他のDNA断片がどれほど存在するのかまったく考慮がされていません。

ふつうに考えても、環状プラスミドは数千~数万、もしかしたらそれ以上に切断されていることを考えられます。このようにqPCRをつかった推定では、全体量からするとほんの一部であるということをきちんと認識すべきです。断片化したDNAが多いほどゲノム統合のリスクを増加させるのは感覚的にも理解できると思います。

Kevinさんが最近インタビューの中で、DNA推定方法はqPCRに落ち着いたとおっしゃられていました。インタビューの中でその理由としてファイザーがDNA量を測定するのに使っていたからとおっしゃっていました。これまでの説明のように、この推定は超過小評価ではあるものの、PCR検査が世界中のどこでも安価にできること、標準化することによって比較が簡単になることなどのメリットはありますね。全体DNAの一部とはいえ、DNAがどれくらい混入しているのかを異なるサンプル、異なる研究機関が行うことの意味はとても大きいとおもいます。どんどんやってほしいと思います。
2023.9.18追記
Phillip Buckhaults博士が上院でDNA汚染について証言をしました。
Tonakaiさんによる字幕動画がこちら
Phillip Buckhaults博士が、mRNA COVIDワクチンに検出されたDNA汚染について上院で証言
— tonakai (@tonakai79780674) September 18, 2023
翻訳レビューは最小限です。 https://t.co/NTjAqWSJCw pic.twitter.com/8WFfISpEBo
とても重要な証言がされています。
「DNAの断片がヒトゲノムに統合する確率はサイズとは関係がなく、存在する粒子の数によって決まる。」
これはとても分かりやすい例を出していました。
板に散弾銃を打った方が、通常の銃で撃つよりも当たる確率が高いというものです。
製造過程で粉砕して取り除こうとしたDNAは結局のこり、粉砕した分DNAの数が増えて、ゲノム取り込みの確率が上がってしまったようです。しかも裸のDNAではなくLNPにくるまれて細胞内に届く状態です。
Phillip Buckhaults博士は証言の最後に、このmRNA技術についてはがん治療など将来的に期待していると述べましたが、そのためにはDNA汚染を取り除くよう政府からも製薬会社に命令すべきとも述べています。(ワタシは20年も解決できていないこの技術自体に反対です)そのようなmRNA推進の先生が警鐘を鳴らしているのです。DNA汚染はもっと広く問題にしないといけないと思います。
この記事が気に入ったらサポートをしてみませんか?