Rを使っての分散分析~1要因分散分析(対応あり)~

今回は、分散分析の話をします。分散分析をざっくり言うと、異なる要因の値に統計的な有意差が認められるかどうか確認する統計検定です。今回は、乱数発生により作成した疑似データを用いて、1要因の分散分析を行っていきます。
1. データセット
サンプルデータの中身はこんな感じになってます。
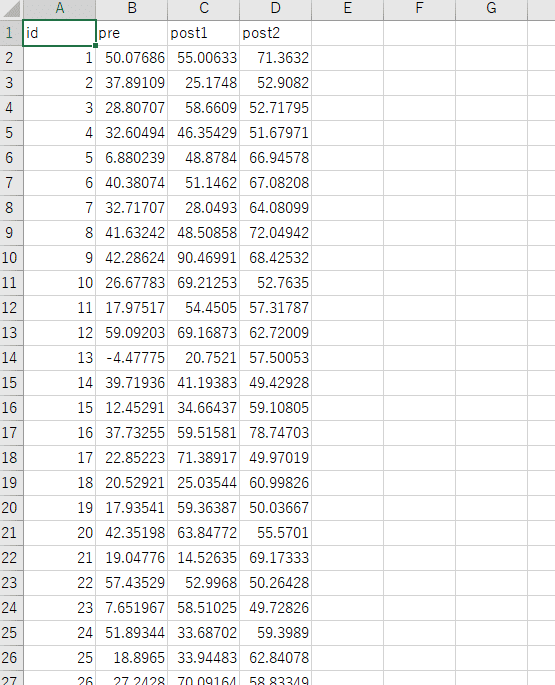
preとpost1とPost2でテストを行ったと仮定して、そのスコアが参加者ごとにデータが入っています。preには平均値30、標準偏差20のデータが50個、post1には平均値50、標準偏差15のデータが50個、post2には平均値60、標準偏差10のデータが50個入っています。データの作成には、pythonを用いました。pythonのコードは↓です。
Col=["pre", "post1", "post2"]
data1=np.random.normal(30, 20, (50,1))#平均値30 標準偏差20 50行1列の乱数
data2=np.random.normal(50, 15, (50,1))#平均値50 標準偏差15 50行1列の乱数
data3=np.random.normal(60, 10, (50,1))#平均値60 標準偏差10 50行1列の乱数
data_all=np.concatenate([data1,data2,data3],axis=1)
df=pd.DataFrame(data_all,columns=Col)データ取得のイメージ―としては↓な感じです。

運動や食事などの介入をしたとして、その前に1回テスト(pre)を行い、介入後にテストを2回(post1とpost2)を行ったとイメージして疑似データを作成しました。
今回は、このpre、post1、post2の水準で統計的有意差が存在するかどうかデータ分析しています。今回のデータでは、1要因で3水準のデータセットです。異なるテスト(pre、post1、post2)を同じ参加者が行っているので、対応ありとなってます。
データは「sample1」というcsvファイルでダウンロードできるようにしておきます。
Rでの解析は、RStudio上で行っていきいます。

↑がRStudioの画面です。カッコいいですね!
2. データの読み込み
まずは、データを読み込みます。
data1<-read.csv('sample1.csv')
RStudioでデータを確認して、正しくデータを読み込まれたかどうか確認します。今回は、しっかりと読み込まれたようです。
どんなデータが入っているか確認します。
summary(data1)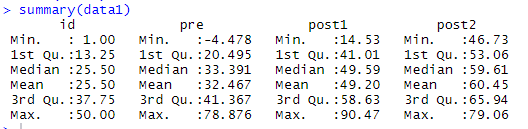
preの平均値は約32.5、post1の平均値は約49.2、post2の平均値は60.45となっており、意図通りのデータであることが確認できました。
3. データの整形
データを読み込んだので、これから分散分析を行っていきます。ですが、このままのデータセットでは、Rのコードで分散分析を行うことができません。分散分析を行うためにデータを整形していきます。
id<-data1$id
pre<-data1$pre
post1<-data1$post1
post2<-data1$post2まずdata1のデータの値を抽出します。この抽出したデータを分散分析が行えるデータフレームに格納していきます。
score1_2<-c(pre,post1,post2)
timing1_2<-factor(c(rep("pre",50),rep("post1",50),rep("post2",50)))
id_1<-factor(rep(id,3))
df<-data.frame(id=id_1,timing=timing1_2,score=score1_2)dfというデータフレームに数値を格納できました。このデータフレームの構造を見てみます。最初の5行を見てみます。
head(df, 5)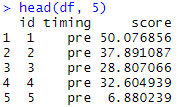
idには参加者の番号が一列に入ってます。timimigにはpre、post1、post2の3つが1列に入ってます。scoreにはテストのスコアが1列に入ってます。これで、分析が可能な形になりました。
4. 1要因分散分析
目的変数をscoreとし、説明変数をtimingとして1要因分散分析(対応あり)を行います。今回は対応ありですが、対応なしの場合は、コードが異なるので、対応が「あり」と「なし」は確実に判断できないといけません。判断できなければ、適切な統計分析ができません。
summary(aov(df$score~df$timing+df$id))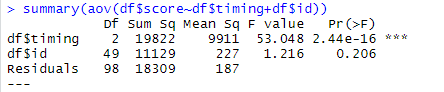
F値が53.048でp値が2.44×10の-6乗でp<0.05なので、統計的有意差が認められました。
これで、preとpost1とpost2のテストのスコアには統計的に差異があることが認められました。ただ、このままでは、どこに差異が生じているのか分からないので下位検定をしていきます。
5. 下位検定
今回はボンフェローニの補正により下位検定を行っていきます。補正を行わないと、統計的有意差がないのに「有意差がある」という第一種の過誤を引き起こしてしまう可能性があります。今回はt検定ですが、同一参加者なので、対応ありのt検定を行います。
pairwise.t.test(df$score,df$timing,p.adjust.method="bonferroni",paired=TRUE)
検定の結果、すべての比較においてp<0.001が認められました。
6. 結果
今回、1要因の分散分析を行った結果、timing(pre、post1、post2)にて有意差が認められました。また、下位検定でも有意差が認められました。これらの結果をグラフで表していきます。
まずは、グラフを描きます。グラフのx軸をpre、post1、post2の順番に描くためdfを少し変換します。
order <- transform(df, timing2= factor(timing, levels = c("pre", "post1", "post2")))今回は、ggplot2でグラフを描き、ggsignifで有意差のバーを描いていきます。
library(ggplot2)
library(ggsignif)
g<-ggplot(order, aes(x = timing2, y = score))
g<-g+stat_summary(fun=mean,geom="bar",alpha=0.5)
g<-g+stat_summary(fun.data=mean_se,geom="errorbar",alpha=10,size=0.5,width=0.3)
g<-g + theme_classic(base_size = 20)
g<-g+ylim(0,85)
g<-g+geom_signif(y_position=60, xmin=1.0, xmax=2.0, annotation= "*",tip_length=0.05, ,textsize=7)
g<-g+geom_signif(y_position=70, xmin=2.0, xmax=3.0, annotation= "*",tip_length=0.05, ,textsize=7)
g<-g+geom_signif(y_position=80, xmin=1.0, xmax=3.0, annotation= "*",tip_length=0.05, ,textsize=7)
g<-g+ annotate("text",x=3.3,y=80,fontface="italic",label="*: p<.001",size=4)
g<-g+ labs(x="Timimig")
plot(g)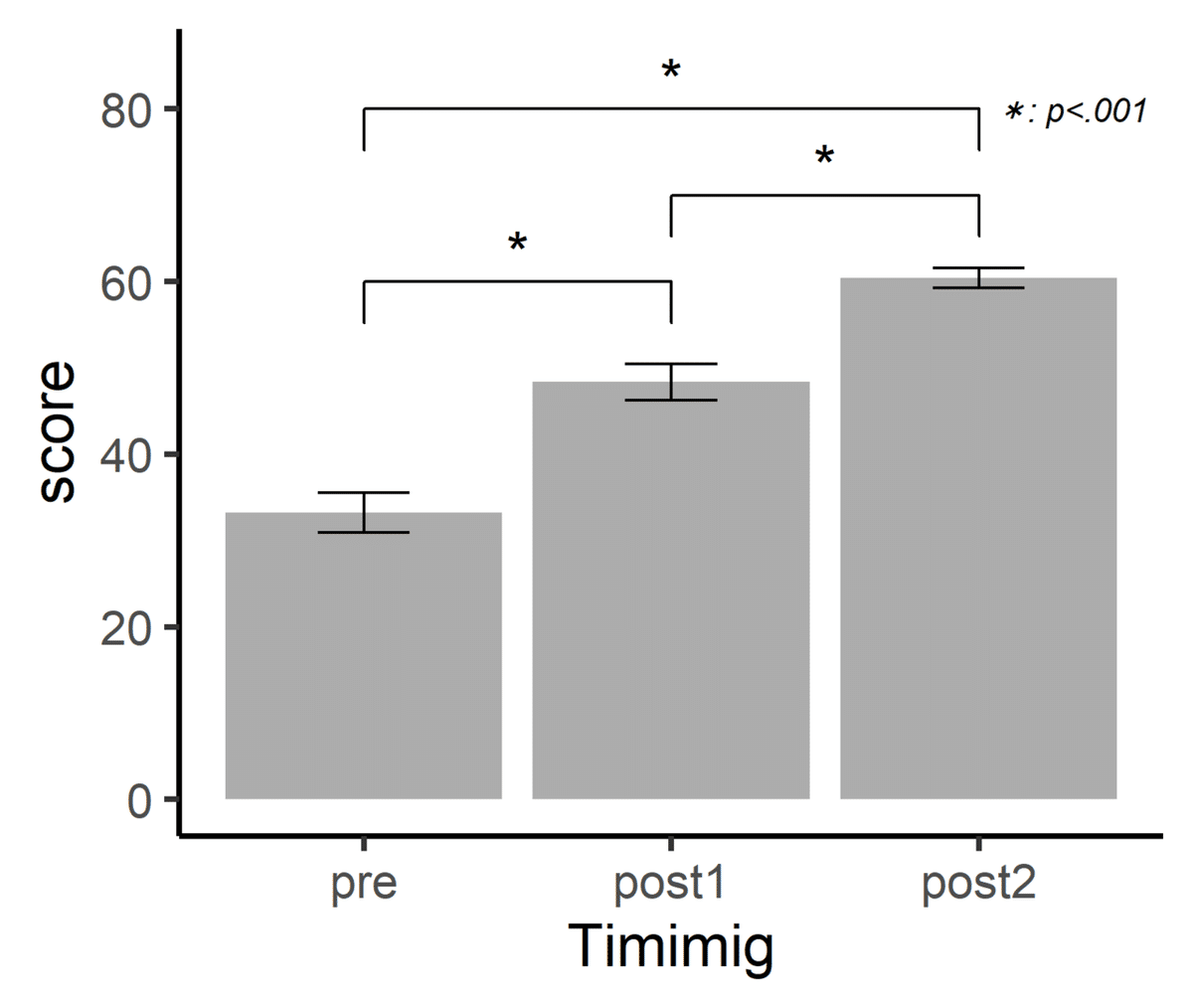
結果を上手く表すことができました。
Rを使って分散分析を行い、一気にグラフまで描けることできました。Rでの統計分析は非常に楽しいです。
今回はここまで。
参考文献・資料
・Rによる多変量解析入門 川端一光ほか著 オーム社
・Rで一元配置分散分析(対応あり)
http://www.takuro-fujita.com/?p=747
・論文用の棒グラフと折れ線グラフをggplot2で描く
https://mrunadon.github.io/ThesisPlot/
・ggplot2 初めの一歩
https://oku.edu.mie-u.ac.jp/~okumura/stat/ggplot2.html
・グラフ描画ggplot2の辞書的まとめ20のコード
https://mrunadon.github.io/ggplot2/
・Rと分散分析
https://www1.doshisha.ac.jp/~mjin/R/Chap_13/13.html
・Rによるスチューデントのt検定
https://data-science.gr.jp/implementation/ist_r_student_t_test.html
・Rによるボンフェローニ補正
https://data-science.gr.jp/implementation/ist_r_multiple_comparison_correction.html
・学会発表のためのggplot2の設定めも
https://qiita.com/uri/items/615653e83642d7e475de
・x軸を並べ替えたい
https://qiita.com/kazutan/items/7840f743d642122d1219
・【GGPLOTメモ6】折れ線グラフを描く
http://nsyk.sakura.ne.jp/homepage/2018/04/13/%E3%80%90ggplot%E3%83%A1%E3%83%A26%E3%80%91%E6%8A%98%E3%82%8C%E7%B7%9A%E3%82%B0%E3%83%A9%E3%83%95%E3%82%92%E6%8F%8F%E3%81%8F/
・【R言語】ggplot2|棒グラフに有意差を示すスターをつけてみる
https://note.com/eiko_dokusho/n/nbc9f39e8d31e
・Rで解析:ggplot2のプロットに有意差バーを追加!「ggsignifr」パッケージ
https://www.karada-good.net/analyticsr/r-585
・軸の範囲を指定するには(xlim, ylim)
http://www.proton.jp/main/apps/r/ggplot-xlim.html
・lot2を使って、注釈を入れる-1
http://mukkujohn.hatenablog.com/entry/2016/09/28/223957
・44. データの加工と抽出
http://cse.naro.affrc.go.jp/takezawa/r-tips/r/44.html
・ggplotでの軸ラベル, タイトルの扱い方
http://motw.mods.jp/R/ggplot_labs.html