
構造方程式モデリング②~探索的因子分析・確認的因子分析・統計的因果探索~

1. はじめに
今回は、探索的因子分析・確認的因子分析・統計的因果探索について学んだことをnoteにまとめていきます。この3つの統計手法は名前からしてイカついですね。常日頃からイカつい体を目指して筋トレしている自分としては、魅力にあふれた名前です。ただ、イカつすぎて実際に上記の統計手法を実装しようとすると躊躇してしまうのではないかと思います。そう、ジムにいるイカついガタイのマッチョに話しかけたいけど怖いみたいな感覚ですね。ジムにいるマッチョの9割は優しい方だと勝手に考えています。見た目で判断してはいけないですね。統計も同じだと考えています。名前がイカつくても、実際に実装してみると簡単にできることが多々あります。
今回もRという無料の統計ソフトを用いて実際に探索的因子分析・確認的因子分析・統計的因果探索を行っていきます。本記事を通して、これらの統計手法が身近に感じていただけたら嬉しいです。私自身、統計を勉強中の身ですので、ここの説明がおかしいや間違っている等ございましたらご指摘いただけると飛んで喜びます。また、「いいね」を押していただけると、勉強するモチベがあがり引き続き統計の勉強に取り組む意欲が上がります。なので、この記事を読んでいただいたら、「勉強頑張って」くらいの感覚で「いいね」を押していただけると非常にありがたいです。ぜひよろしくお願いします。
それでは早速本題に入っていきましょう!下の図のように、データを取得したのはいいけれど、どうやってデータを分析したら良いかというのは尽きない悩みの種だと思います。リサーチする際には、仮説をもって特定のデータを収集すると思いますが、なかにはとりあえず集めたというデータもあると思います。そのような現状のなかで、探索的因子分析・確認的因子分析・統計的因果探索はデータの解釈に役立ってくれる強い味方になってくれると思います。「探索」と聞くとみなさんどのような印象をもっているでしょうか?田舎に住んでいた私は、山の中を歩いていい感じの場所に簡易的な秘密基地を友達と作っていたころの記憶が蘇ってきます。

話が脱線したのでもとに戻します。今回取り扱う統計的手法は、収集したデータに潜む因子の抽出や、データ同士のつながりを明らかにしていきたいという願いに寄り添ってくれる手法となっています。今回の記事では、探索的因子分析・確認的因子分析・統計的因果探索をRを用いて実行することで、実際にどのようなことができるのか確認することを目的としています。
2. データセットの説明
今回扱うデータセットはRのpsychパッケージが提供しているbfiというデータセットを使っていきます。このbifというデータセットには、パーソナリティーに関する25項目の質問のデータを集計しており、2000名を超えるデータとなっています。この質問データは、
・協調性(A1~A5)
・勤勉性(C1~C5)
・外向性(E1~E5)
・神経症傾向(N1~N5)
・開放性(O1~O5)
という5つの因子によって構成されています。Rなどで因子分析を行う際にチュートリアル的な立ち位置で用いられることが多いようです。実際に因子分析でネット検索してみると、このデータセットを用いて因子分析の解説をしているサイトをいくつも見かけました。今回のnoteでも、このデータセットを用いてデータの因子分析や統計的因果探索を行っていきます。
データセットの詳しい説明については、参考文献・資料の[3]・[6]・[7]に記載があるのでぜひ見てみてください。
3. 探索的因子分析
探索的因子分析を行うことで、データに潜む背景因子を抽出することにつながります。例えば、英語・数学・国語・理科・社会というテストをしたときに、これらのテストから得られるデータには理系と文系という隠れた因子が存在することが考えられます。この理系・文系というのは実際にデータを取得したわけではありません。5科目のテストのデータから考えられる概念の因子(または潜在的な因子)となっています。因子分析においては、英語・数学・国語・理科・社会のテストという観測されたデータを観測変数と言い、理系や文系といった因子を構成概念とい言います。構造方程式モデリングにおいては、理系や文系といった因子は潜在変数と言います。理系や文系というのは分かりやすい例ですが、実際のデータからはどのような構成概念があるのかは分析者が決めなければなりません。また、その構成概念がいくつ存在するのかについては分からないことがあります。そこで、統計的手法で構成概念の枠組みを抽出してくれる探索的因子分析の出番となります。
3.1 データセットの取り込み
実際にRにて、bfiのデータセットを用いて探索的因子分析を行ってみます。まずはデータセットを取り込んでいきす。bfiの5つの因子のなかで、今回は協調性・勤勉性・神経症傾向の3つの因子を用いて探索的因子分析を行っていきます。また、データ数が2800名とかなり多いで、今回は300名程度のデータで行っていきます。コードの説明に関しては#で記載しています。
#探索的因子分析に必要なパッケージをインポート
library( psych )
library( GPArotation )
library(dplyr)
#bfiデータセットのインポート
data(bfi)
#bfiのデータセットから必要な質問項目を抽出
data_1 <- bfi[1:10] #協調性と勤勉性を抽出
data_2 <- bfi[16:20] #神経症傾向を抽出
data_3<- cbind(data_1, data_2) #data_1とdata_2を列方向に結合
data_4 <- data_3[c(1:300),] #上から300名のデータを抽出
data_5 <- na.omit(data_4) #欠損値があるデータを削除
nrow(data_5) #データ数の確認 これでデータセットの準備は終了です。欠損値を含むデータを削除すると、データ数は281となりました。
3.2 因子数の探索
得られたデータセットから構成概念の因子がいくつ存在するのか確認していきます。今回の探索的因子分析を行う前提条件として、協調性・勤勉性・神経症傾向という因子が入っていることを知らないと仮定します。つまり、データあるけどその背景にある構成概念については良く分かっていないから、そこを明らかにしたいという目的で探索的因子分析を行っていきます。
#構成概念因子数の確認
fa.parallel( data_5, fa = "fa")上記のコードを実行すると結果は、「Parallel analysis suggests that the number of factors = 4 」となり、4つの因子があることが示されています。結果として表示されるスクリープロットを確認してみます。

スクリープロットをみると横軸4のところで折れ曲がりが発生しています。この折れ曲がった箇所での±1が因子数の目安となるそうです。今回の例でいえば、3~5が因子数の目安ですね。もともと、協調性・勤勉性・神経症傾向という3つの因子が入っているデータなので、だいたいデータセットに適合している因子数を示してくれていますね。また、カイザー・ガットマン基準(青色△が1以上もしくは0以上)というのに従うと、因子数は2~4であることが分かります。これらの示された因子数を参考にして、最終的にはデータの特徴から因子数がいくつかるのか判断しなければなりません。
スクリープロットの見方については、参考文献・資料の[2]・[3]・[7]に詳しいい説明が記載されています。
3.3 探索的因子分析の実装
スクリープロットで因子数が4つと示されたので、今回は4つの因子数で探索的因子分析を行っていきます。探索的因子分析を行う場合には、psychパッケージのfa()を用いることでサクッと行うことができます。
#探索的因子分析の実行
result = fa( data_5, nfactors = 4, fm = "ml", rotate = "promax")因子分析を行う際には、因子負荷行列の解釈を容易にするために解の回転を行う必要があります。様々な回転法がありますが、今回はプロマックス回転を行いました。結果は↓のようになりました。

この行列は因子負荷行列を示しています。ただ、このままだと分かりづらいので結果を図示してみます。
#探索的因子分析の結果の図示
fa.diagram(result)
こうしてみると、協調性(A1~A5)と勤勉性(C1~C5)についてはそれぞれ一つずつの因子になっていますが、神経症傾向(N1~N5)には2つの因子となっていますね。
ここでもともと因子数が3つと分かっていたので、因子数3つの探索的因子分析の結果を↓に載せておきます。

因子数を3つにすると、協調性・勤勉性・神経症傾向がそれぞれ分かれる形となりました。加えて、協調性と勤勉性には何らかの関連があることが伺えます。
3.3 探索的因子分析のまとめ
ここでは探索的因子分析の一連の流れとその結果の図示についてRを用いて行いました。因数を決定する際のプロセスや基準にはさまざまな観点があるので、スクリープロットだけの指標だけでなくBICといった客観的な指標などを考慮する必要がありそうです。また統計的に示された因子数だけで判断するだけでなく、得られたデータの特徴を踏まえたうえで因子数を決定することで、得られたデータから検証したいことの本質に近づくと考えられます。
今回の探索的因子分析のRのコードは主に参考資料[3]を参考にさせていただきました。本記事を読んで探索的因子分析に興味を抱いた方がいらっしゃいましたらぜひ参考資料[3]をみてみてください。さらに詳細な説明とコードが記されていますので、理解が深まります。
4. 確認的因子分析
次は確認的因子分析の説明を行っていきます。確認的因子分析は別名で検証的因子分析や確証的因子分析と呼ばれるそうです。この分析の特徴としては、理論が先に来るということがあります。3章で説明した探索的因子分析はデータから因子数を決めるというプロセスだったのに対して、確認的因子分析は仮説によって因子数が決まっているなかでの因子分析という立ち位置になります。先行研究での知見やデータの特徴からあらかじめ因子数が決まており、その因子を構成する観測データも決まっているなかでモデルを作成します。そのモデルの適合度(モデルに対して得られた観測データとその潜在因子がどれだけフィットしているか)を確かめることで、因子分析を用いた解釈を行っていきます。また、確認的因子分析を行うことで、因子間におけるつながりが見えてきます。これは、後の構造方程式モデリングを行う際に重要な知見となります。確認的因子分析を行う前のイメージとして↓図を作成しました。

4.1 モデルの作成
3章で使用したデータセットを利用してモデルを作成していきます。今回の確認的因子分析ではRのlavaanというパッケージを用いて行っていきます。
#必要なパッケージのインポート
library(lavaan)
library(semTools)
library(semPlot)
library(GPArotation)
#モデルの作成
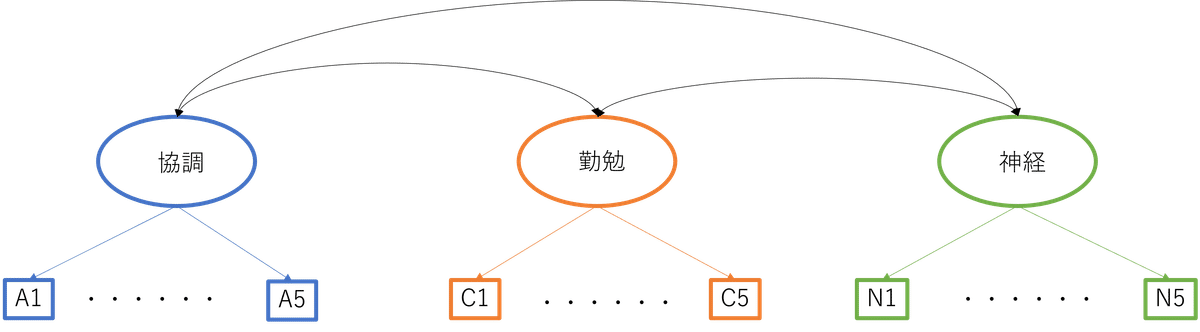
model1 <- '協調 =~ A1 + A2 + A3 + A4 + A5
勤勉 =~ C1 + C2 + C3 + C4 +C5
神経 =~ N1 + N2 + N3 + N4 +N5'
これでモデルの完成です。イメージとしては↓の図のようなモデルを作成しています。
4.2 確認的因子分析の実装
確認的因子分析の実行には、lavaanのcfa()を用います。モデルを実行して結果を見ていきます。
fit1<- cfa(model1, data = data_5) #確認的因子分析の実行
summary(fit1,fit.measure=TRUE) #結果の確認モデルの適合度を見ていきます。適合度はそれぞれCFI: 0.824、TLI: 0.787、RMSEA: 0.094、SRMR: 0.082となりました。CFIとTLIは1に近づくほどよく、RMSEAは0.05が望ましいと言われています(参考文献・資料[2])。今回のモデルではあまり良い適合度とは言えないですね。もとあった5つの因子からとりあえず3つの因子を選んでいることが原因かもしれません。5つの因子すべてで行えば適合度は良くなるかもしれません。今回はこのままま「えいや!」の勢いで進んでいくことにします。

次に潜在因子(構成概念)のつながりをみていきます。
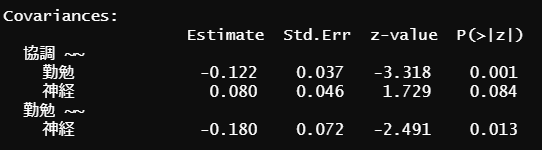
結果(p値)をみると、協調と勤勉、勤勉と神経になんかしらの関係性が潜んでいそうです。数値だと分かりづらいので図として示してみます。
#結果の図示
semPaths(fit1, style="lisrel", whatLabels="est",
layout="tree", rotation=4, edge.label.cex=0.8)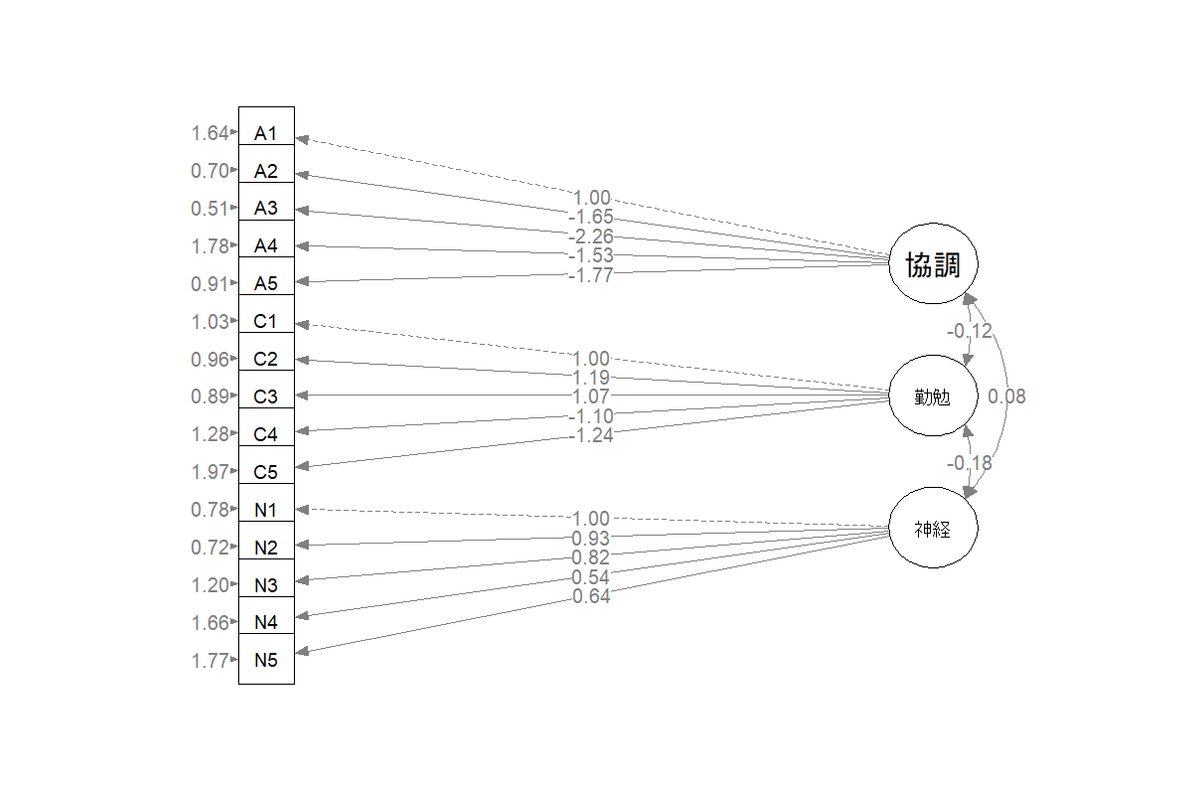
こうしてみると、協調性が高いと勤勉性が下がり、神経症傾向が高いと勤勉性が下がるというような関係性が見えてきそうです。この確認因子分析によって、協調性と神経症傾向が高まると勤勉性が低下するというような因果関係が見えてきました。ここでは、そのような因果が存在すると仮定してみます。その因果を構造方程式モデリングによって表現してみます。
4.3 構造方程式モデリングの実装
確認的因子分析によって見えてきた因果の流れを構造方程式モデリングに当てはめて検証してみます。この記事では確認的因子分析がメインとなるため、構造方程式モデリングについてはコードの実行とその結果の図示までとしておきます。
#構造方程式
#モデルの作成
model2 <- '協調 =~ A1 + A2 + A3 + A4 + A5
勤勉 =~ C1 + C2 + C3 + C4 +C5
神経 =~ N1 + N2 + N3 + N4 +N5
勤勉 ~ 協調 + 神経'
#モデルの実行
fit2<- sem(model2, data = data_5)
#結果の確認
summary(fit2,fit.measure=TRUE)
#結果の図示
semPaths(fit2, style="lisrel", whatLabels="est",
layout="tree", rotation=3, edge.label.cex=0.8)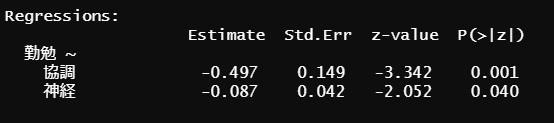

構造方程式モデリングを通して、因果の流れを図示することができました。仮定した仮説通り、協調性と神経症傾向が高いことは、勤勉性の低下につながるという関係性が存在することを認めることとなりました。
4.4 確認的因子分析のまとめ
ここでは確認的因子分析の説明とRでの実行を行い、得られた結果から構造方程式モデリングを行う一連のプロセスを説明しました。探索的因子分析とは異なり、確認的因子分析ではデータにおける背景知識が重要になってくると考えられます。データの関係性を明らかする上で確認的因子分析は重要な役割を担うことになりそうですね。
5. 統計的因果探索(LiNGAM)
本記事の最後の章となりました。データの探索において因果関係を調べようと考えた時には、統計的因果探索が心強い味方となってくれます。統計的因果探索の理論については、参考文献・資料[12]をご参照ください。統計的因果探索では、独立成分分析と線形回帰の合わせ技によって観測変数間の因果を探索していきます(参考文献・資料[13])。私の理解不足のため、これらの統計手法を合わせて統計的因果探索を行うことは非常に難しいです。また理論を合わせてとなるともう頭のなかが「?」でいっぱいになります。そんな状況でも心強い仲間がいます。そうです無料統計ソフトRのパッケージを利用することです。ここでは、Rのパッケージであるpcalgを用いてLiNGAM(Linear Non-Gaussian Acyclic Model)という統計的因果探索を行うことをメインとします。
5.1 探索する対象となるデータ
ここでは、第3章と第4章で使用してきたbfiのデータセットの勤勉性のデータを用いて因果探索を行っていきます。イメージとしては↓図を想定しています。

というこで、第2章で作成したデータセットから勤勉性のデータを取り出していきます。
library(dplyr) #必要なパッケージのインポート
KC <- select(.data = data_5, c("C1", "C2", "C3","C4","C5")) #勤勉性のデータの抽出 5.2 LiNGAMの実装
pcalgというパッケージを利用してLiNGAMを実装していきます。Rのコードに関しては、参考文献・資料[14]・[15]・[16]に詳しい記載があるので、ぜひ見てみてください。
#必要なパッケージのインポート
library(tidyverse)
library(pcalg)
model_KC <- lingam(KC) #LiNGAMの実装
as(model_KC, "amat") #結果の表示pcalgによるLiNGAMを実装するためには以下のパッケージのインストールが必要になるそうです。
install.packages("tidyverse")
install.packages("ggExtra")
install.packages("BiocManager")
BiocManager::install(c("graph", "RBGL"))
install.packages("pcalg")
詳しくは、参考文献・資料[14]をご参照ください
結果を見てみると、C1→C2、C1→C3、C1→C4、C1→C5、C3→C2、C4→C5という因果が存在することが認められました。結果は↓に示しています。

この結果では、因果のつながりが分かりづらいので図示してみます。図示に関するRのードは、参考文献・資料[15]を模倣させていただきました。貴重な情報を共有していただいた参考文献・資料[15]の製作者の方にはこの場をお借りして感謝申し上げます。詳しいRのコードに関しては、上記に示しているリンクから飛んでいただき、ぜひ製作者のサイトを訪れてください。
library(igraph) #必要なパッケージの読み込み
KC_L <- lingam(KC)$Bpruned # LiNGAM
rownames(KC_L) <- colnames(KC) # 行名を追記
colnames(KC_L) <- colnames(KC) # 列名を追記
GM2 <- t(abs(KC_L)) # 絶対値にして転置する
GM3 <- GM2*5/max(GM2) # 値を適度な大きさにする
GM4 <- graph.adjacency(GM3,weighted=T, mode = "directed") # グラフ用のデータを作成
plot(GM4, edge.width=E(GM4)$weight) # グラフを作成
図示をすることで因果の流れが把握しやすですね。もしかしたら、C1はC2とC3の交絡因子で、C4とC5の媒介因子になっているのかもしれません。ここから先は、構造方程式モデリングによる媒介分析等を行う必要がありそうです。構造方程式モデリングによる媒介分析に関しては以前に記事としてまとめたので、こちらを見ていただけると嬉しいです。
pcalgのパッケージにてLiNGAMを実装してみましたが、同じデータセットを用いても結果が異なるということがありました。パッケージ利用の利点としては簡易にモデルの実装ができるのですが、どのような計算が背後で行われているかについてはブラックボックスとなっています。再現性の高い解析をするのであれば、計算式の構築といった理論的な知識を有することが必要ですね。コードが間違えているなどの欠点があるかもしれませんので、もし間違いがありましたらぜひ教えていただきたいです。Rのコードに関する詳しい説明については参考文献・資料[14]・[15]・[16]をご参照ください。
5.3 統計的因果探索のまとめ
統計的因果探索についてはまだまだ理解不足なところが多いため、勉強の必要性を感じています。今回の記事ではRによるプログラミングを通して、統計的因果探索を行うとどのような結果が得られるのかについて確認することができました。今後の勉強を通して知識が増えることで、さらに複雑なモデルについても因果探索ができるようになりたいです。
6. おわりに
最後まで読んでいただき誠にありがとうございました。noteの記事については、自分が学習したことのアウトプットとして活用しています。自分の学びを通して、読んでいただいた方に少しでもお役に立てる記事になっていればこれほど嬉しいことはありません。まだまだ知識不足や理解不足のため、ところどころ説明が分かりづらい点があったと思います。その際にはぜひ遠慮せずにご質問していただければと思います。また、説明やコードの改善点・間違いがありましたらご指摘していただけると非常にありがたいです。引き続き統計の勉強に邁進していきます。この記事を読んで、「勉強頑張れ!」と思った方がいましたら、今後のモチベーションにつながりますので、ぜひ「いいね」を押していただけると非常にありがたいです。勉強する中でまた新しい学びがありましたら、今後もnoteに記事としてまとめていきたいと考えています。
参考文献・資料
1. 豊田秀樹 (1998) 共分散構造分析 入門編―構造方程式モデリング (統計ライブラリー) 朝倉書店
2. 豊田秀樹 (2014) 共分散構造分析[R編]―構造方程式モデリング 東京書籍
3. 津田裕之 Rによる統計入門 因子分析
4. 清水裕士 Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
5. TOMOKOBA BLOG 探索的因子分析
6. 井出草平の研究ノート Rで因子分析 基礎
7. 土屋政雄 researchmap 検証的(確証的/確認的)因子分析: confirmatory factor analysis(CFA)
8. ねこすたっと データ構造を要約・説明する(1):探索的因子分析(psychパッケージ)[R]
9. 土屋政雄 resarchmap lavaanで確認的(確証的/検証的)因子分析:confirmatory factor analysis(CFA)
10. 荒木孝治 lavaanチュートリアル
11. 確認的因子分析とは何か | ビジネスリサーチラボ
12. 清水昌平 (2017) 統計的因果探索 (機械学習プロフェッショナルシリーズ) 講談社
13. 小川雄太郎 (2020) つくりながら学ぶ! Pythonによる因果分析 ~因果推論・因果探索の実践入門 (Compass Data Science) マイナビ出版
14. NHN TECHORUS Tech Blog 「統計的因果探索」の一部を動かしてみた
15. Rによるデータ分析 RによるLiNGAM
16. mikutaifukuの雑記帳 Fitbitデータで因果を探索してみる 〜独立成分分析によるLiNGAMモデルの推定〜