
【Kaggle House Prices 】初心者でもできる! AIで住宅価格を予測する

ESTYLEのデータサイエンス事業部の「京ちゃん」こと京黒です。入社時の研修のひとつとしてKaggleの「House Prices」のコンペに挑戦に挑戦しました!
ここでは、その内容について紹介します。
機械学習に挑戦してみたいと思っている方の参考になれば幸いです。
Kaggleとは
一言で表すと、「データ分析・機械学習のコンペティションのプラットフォーム」です。
企業や研究者が課題とデータを投稿し、世界中のデータサイエンティストが課題解決のためのAIモデルを作ります。そして、作成したモデルの精度を競います。
開催中のコンペでは、精度の高いモデルを作成したチームに対して賞金が支払われます。また、精度の高いモデルに限らず、他の多くの参加者のコードや参加者同士の議論なども見ることができたり、自分で議論や質問を投稿することもできます。
つまり、世界中のデータサイエンティストの最先端の知見を得ることができるのです!
House Prices概要
今回挑戦したのは「House Prices - Advanced Regression Techniques」です。これは、アイオワ州エイムズの住宅のほぼすべての特徴を表す79種類のデータを用いて、各住宅の価格を予測するというコンペです。
79種類のデータには、建物データ、土地データ、機能データ、住宅周辺に関するデータなど、様々な情報が含まれています。
これらを教師データとして、住宅価格という「値」を予測することが目的です。データ分析のジャンルとしては「回帰」と呼ばれるものになります。
与えられるデータについて
このコンペでは、下記のデータが与えられます。
・train.csv:学習データ
・test.csv:テストデータ
・data_description.txt:79種類のデータの説明
・sample_submission.csv:提出ファイルのサンプル
この中で、機械学習に使うのは、train.csvとtest.csvです。train.csvにはSalePrice(住宅価格)が含まれますが、test.csvには含まれません。train.csvのデータを使ってモデルを作成し、その作成したモデルでtest.csvの住宅価格を予測します。
data_description.txtは、どのようなデータが与えられているのかを理解する手助けになります。
予測を提出する際には、sample_submission.csvと同じ形式になるようにして提出します。
以下に、79種類のデータの中から一部を紹介します。

この他にも住宅に関する基本的な情報から詳細な情報まで様々なデータがあります。
分析について
ここからは早速分析を始めていきます。
● 全体の流れ
今回は、以下のような流れで分析を行いました。

与えられたデータは、そのままの状態で分析に使えるわけではありません。
分析できる形に整えたり、より効果的な分析ができるように不要なデータを取り除いたりといった前処理が必要です。
さらに、パラメータチューニングやアンサンブル学習をした後で、やっと予測ができるようになります。
機械学習に触れたことがない方には、パラメータチューニングやアンサンブル学習などは聞き慣れない単語かもしれませんが、後ほど紹介しますのでご安心ください。
● 前処理
先ほど述べたようにまずはデータの前処理が必要です。今回は、以下の流れで前処理をしていきます。
1. nullの処理
2. LabelEncoding
3. OneHotEncoding
4. 特徴量抽出
5. 特徴量選択
nullの処理
最初はnullの処理です。
nullとは、何もないということを表したもので、データが何も格納されていない / 空であることを表しています。
nullであるということは、その部分を学習に使えないということです。そこで、nullをうまく補完することで、大きく精度が向上する場合があります。
また、そもそもnullが存在すると学習を行えない場合もあります。
● nullが意味を持つ場合
今回与えられたデータでは、nullがただの欠損値ではなく意味を持っているカラムも存在します。GarageQual(ガレージの品質)やBsmtQual(地下室の品質)などは、nullが意味を持つカラムです。
例えば、GarageQualには、以下のようなデータが存在します。
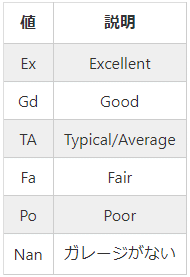
ここで、Nanとは、nullのことを指しています。
GarageQualにはガレージの品質についてのデータが格納されています。
品質は5段階評価で表されており、nullの場合は「ガレージがない」ことを示しています。
そこで、このようなnullが意味を持つカラムについては、nullをNoDataという文字列に変換します。
● 欠損値
これで、残りのnullは値が欠損しているものだけになりました。
欠損値の処理は、欠損値があるカラムを削除するか、他の値で補完する必要があります。今回は、他の値で補完することにします。
まず、正しい値がわかる場合は、手動で正しい値に補完します。
例として、BsmtFinSF1とBsmtFinSF2の補完を挙げます。これらの補完で参考にするのがBsmtFinType1とBsmtFinType2です。BsmtFinSF1とBsmtFinSF2は、完成した地下室の面積のデータであり、BsmtFinType1とBsmtFinType2は、完成した地下室の評価のデータです。それぞれ1と2がありますが、地下室が複数タイプある場合には2の値が存在するということです。
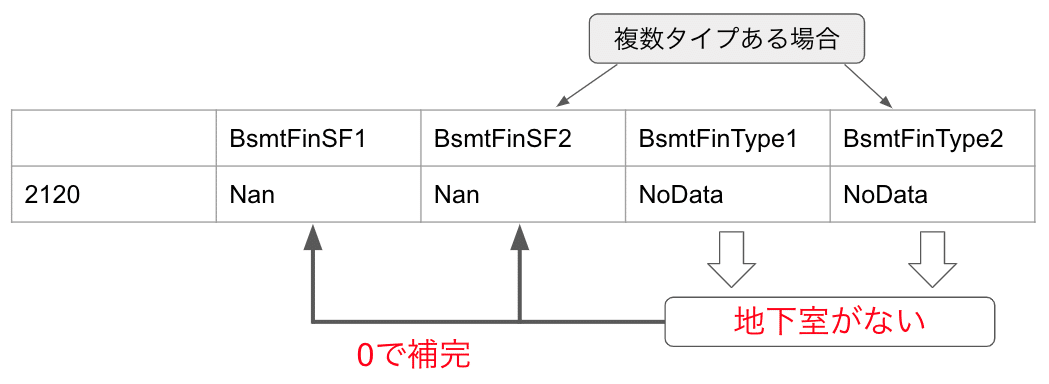
この場合、BsmtFinType1とBsmtFinType2が先ほど補完したNoDataという文字列です。つまり、この住宅には地下室がないということがわかります。そのため、BsmtFinSF1とBsmtFinSF2は地下室の面積を表すので、どちらも0で補完します。
ただし、全てのカラムで欠損値の正しい値がわかるとは限りません。
正しい値がわからない場合も、他の値で補完する必要がありますが、今回は、関連するカラムごとの中央値で補完します。
例として、LotFrontageの補完を挙げます。
その前に「そもそもLotFrontageとは何か?」を理解しなければなりません。
LotFrontageとは、区画と接する道の長さのことです。下図の赤線部分がLotFrontageです。
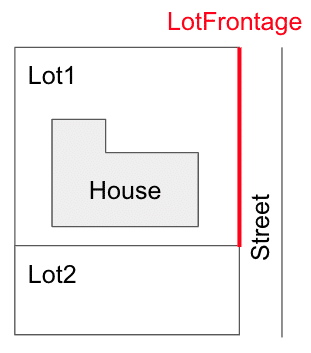
図を見ると、区画サイズによってLotFrontageの値がほぼ決まると考えられます。また、区画サイズは地区ごとに標準のサイズが決まっているので、地区ごとにLotFrontageの値がほぼ決まるのではないかと考えられます。
そこで、地区を表すNeighborhoodごとのLotFrontageを箱ひげ図で見てみます。

この図から、NeighborhoodごとにLotFrontageの値がある程度まとまっており、少しずつ違いがあることがわかります。
今回は、LotFrontageの欠損値をNeighborhoodごとの中央値で補完します。
Label Encoding
文字列データはそのまま学習に使うことができません。
そこで、文字列データに対してLabel Encodingを行います。
Label Encodingとは、文字列等のデータを数値のラベルに変換することを指します。
例えば、GarageQualは以下のように変換します。
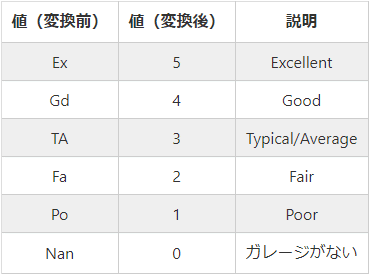
このようにそれぞれの値を0〜5のラベルで表しています。
また、GarageQualは評価を表しており、各値に順序(大小関係)があります。そのため、最も高い評価を5として、評価が低くなるにつれて、4, 3, 2, ... と値が小さくなるようにしています。
今回は、このような順序がある文字列のカラムに対してのみLabel Encodingを行います。順序がない文字列のカラムは、次のOne-Hot Encodingを行います。
One-Hot Encoding
One-Hot Encodingとは、データを0か1で表すことです。
例として、Alleyを挙げます。Alleyには、
・Grvl
・Pave
・NoData
の3種類のデータが存在します。
これらを0か1で表現していきます。
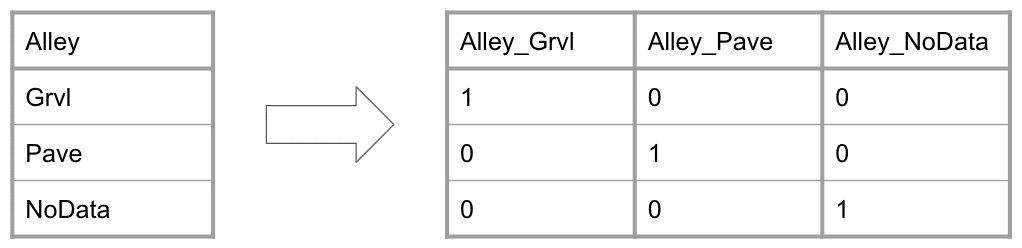
このように、複数のカラムに分割し、当てはまれば1, 当てはまらなければ0で表現します。
ただし、Alley_NoDataは削除します。
なぜなら、Alley_GrvlとAlley_Paveがどちらも0であればNoDataであると解釈できるからです。
その上で、以下のようにOne-Hot Encodingします。

新たにAlley_GrvlとAlley_Paveを作成し、元々のAlleyがGrvlであればAlley_Grvlが1、PaveであればAlley_Paveが1、それ以外は全て0とします。
また、元々のAlleyを削除することで、One-Hot Encodingが完了します。
その他の処理
その他の処理として、YearBuiltとYearRemodAddの値を変換します。
これらは、どちらも年のデータです。これをYrPsdBlt(築年数)とYrPsdRmd(リフォーム後経過した年数)に変換します。

このようにすることで、例えば、上図の1番を0番と比べたとき、どちらも差は35です。しかし、変換前は2003のうちの35ですが、変換後は48のうちの35なので、変換後の方が差が顕著に現れます。
また、変換後は元のYearBuiltとYearRemodAddは削除します。
特徴量抽出
ここまでの処理で、学習ができるところまでは前処理が終わりました。
次は、予測の精度を上げるために、新たな特徴量を作成します。

このように、設備があるかないかを0,1で分類したり、面積等を合計したりして、新たな特徴量を作ります。今回は、10個ほど新たな特徴量を作成しますが、工夫次第で様々な特徴量を作成できます。
特徴量選択
先ほどは、新たに特徴量を作成しましたが、特徴量は多ければ良いというものではありません。ノイズにより予測精度が落ちてしまうことがあるのです。
そこで、今回は以下の2つにより余計な特徴量を排除します。
・相関が高いカラムを片方削除
・重要度が低いカラムを削除
相関が高いカラムは、多重共線性の影響を減らすため、重要度が低いカラムは、ノイズによる影響を減らすために行います。
特徴量の重要度は、LightGBMのfeature_importanceメソッドによって算出された重要度を参考にします。これは、LightGBMでの学習で各特徴量が何回使われたかを重要度としています。
目的変数の対数変換
今回のコンペのスコアは、RMSLE(対数平均二乗誤差)で算出されます。
しかし、今回使うLightGBMでは、このRMSLEは指定できません。
そこで、評価関数はRMSE(平均二乗誤差)を指定し、学習を行う前にlog(目的変数 + 1)で変換します。そして最後に、予測結果をexp(目的変数) - 1で逆変換することで、RMSLEで評価し、予測結果は元に戻すことができます。
※ RMSE / RMSLEについては下にまとめています。
● RMSEとは
RMSEとは、予測の精度を評価するための評価関数のひとつです。回帰で使われることが多い評価関数です。
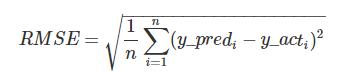
● RMSLEとは
RMSEと似ていますが、「予測値, 正解値ともに +1 してlogをとる」という部分が異なります。それ以外はRMSEと同じです。
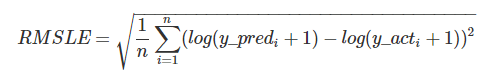
● 目的変数の分布
また、目的変数の分布を見てみると、対数変換前後で以下のようになっています。

対数変換したことで正規分布に近づいているのが分かります。
ただし、目的変数を正規分布にする必要は必ずしもあるわけではありません。回帰分析において、残差が正規分布であることが望ましいのですが、目的変数を正規分布に近づけると残差も正規分布に近づく場合が多くあります。
また、今回のように対数変換することで正規分布に近づく変数は多くあります。今回は、RMSLEで評価するために対数変換したら、たまたま正規分布に近づきました。
● パラメータチューニング
機械学習モデルにおける設定値のようなものをハイパーパラメータと言います。モデルが最適になるように、このハイパーパラメータをデータに合わせて調整し、最適化することがパラメータチューニングです。
パラメータチューニングの手法はいくつかあります。
・手動で調整
・グリッドサーチ
・ランダムサーチ
・ベイズ最適化
etc...
今回は、ベイズ最適化の手法を用いたoptunaというフレームワークを使ってパラメータチューニングをしていきます。
● optuna
optunaとは、ベイズ最適化アルゴリズムを用いてハイパーパラメータの最適化を自動化するためのフレームワークです。
簡単にまとめると、「パラメータチューニングを自動化するフレームワーク」です。
今回は、後述のアンサンブル学習で5つのモデルを使用します。
そのため、それぞれのモデルについてoptunaでパラメータチューニングを行います。
● optuna詳解
optunaでどのような処理が行われているのか見てみます。
簡単のため、以下の1変数関数の最小値をoptunaで求めてみます。
![]()
y = f(x)のグラフは以下のようになります。

これをoptunaを使って最小値の探索を行うと、探索の様子は以下のようになります。

今回は100回探索を行なっています。
毎回の探索で、そこまでの探索の履歴に基づき、有望そうな領域を推定し、その領域の値を試すということを100回繰り返しているのです。
図を見ると、色の薄いプロット(浅い探索の結果)は様々な場所にあります。このように全体を的確に探ることで極小値にひっかからずに探索できます。また、プロットの色が濃くなる(探索が深くなる)につれて最小値付近に収束していることがわかります。
探索の結果としては、
x = 4.659238・・・の時に最小値66.909307・・・となりました。
x = 4.658312・・・の時に最小値66.909254・・・が正解なので、高い精度で探索ができています。
これを機械学習のパラメータチューニングに置き換えると、
・ x → ハイパーパラメータ
・ f(x) → 評価関数
となります。
つまり、今回のコンペでは、評価関数(RMSLE)の値が最小となるハイパーパラメータの値を試行を繰り返して探索するのです。
● アンサンブル学習
複数のモデルを個々に学習させ、それらを掛け合わせることにより予測精度の向上を図る手法です。
それぞれのモデルには、向き不向きがあります。
そのため、複数のモデルを掛け合わせることによって、単一のモデルでの予測よりも精度が上がる場合が多くあります。
今回は、以下の5つのモデルを使用します。
・ ElasticNet(線形回帰)
・ KernelRidge(非線形回帰)
・ GradientBoostingRegressor(回帰木)
・ XGBRegressor(回帰木)
・ LGBMRegressor(回帰木)
これらのモデルを掛け合わせる方法として、今回は、
・ 各モデルの平均
・ スタッキング
の2通りの方法を試してみます。ちなみに、LightGBMRegressorのみで提出した時のスコアは、「0.13135」でした。
各モデルの平均
まずは、単純に各モデルの予測値の平均値を最終的な予測値としてみます。

各モデルの平均で、提出スコアは「0.12121」を得られました。LightGBMRegressorのみの場合が「0.13135」だったので、今回の場合は、単純に平均値をとるだけでも予測精度が向上しました。
スタッキング
次にスタッキングを実装します。
複数のモデルを個々に学習させ、その後、各モデルの予測値を特徴量として再度学習を行います。これを繰り返し、最終的な予測値を得る手法がスタッキングです。
今回は、2層のスタッキングを行います。

今回のスタッキングを、より詳細に説明します。1層目では、5つのモデルを個々に学習させます。ここまでは先ほどと同じです。
2層目では、1層目のtrainデータの予測値を特徴量として、XGBRegressorで学習を行います。学習後のXGBを用いて、1層目の予測値から最終的な予測値を出します。
2層目のモデルは5つのモデルを全て試した結果、XGBRegressorが一番高い予測精度を得られたので、この記事では、XGBRegressorのみ記載しています。
スタッキングでの提出スコアは「0.11996」を得られ、今までで一番高い予測精度となりました。
まとめ
LightGBMのみのスコアは0.13135でした。「ElasticNet」「KernelRidge」「GradientBoostingRegressor」「XGBRegressor」「LGBMRegressor」の5つのモデルを用い、各モデルの平均値でのスコアは0.12121、スタッキングでのスコアは0.11996でした。
スタッキングで予測を行った場合に最も高い予測精度を得ることができました。
また、改善点として
・ null値の数など他の新たな特徴量を作成する
・ 重要度の高い特徴量同士を掛け合わせて次元削減を行う
・ スタッキングの層を増やす
などが考えられます。これらを試してみると精度がさらに上がるかもしれません。
採用情報
ESTYLEは「コウキシンが世界をカクシンする」という理念のもと、企業のDXを推進中です。経験・知識を問わず、さまざまな強みを持ったエンジニアが活躍しています。
弊社では、スキルや経験よりも「データを使ってクライアントに貢献したい」「データ分析から社会を良くしていきたい」という、ご自身がお持ちのビジョンを重視しています。
ご応募・問い合わせはこちら。