
【無料】ChatGPT相当のオープンソースLlama2(始め方)

はじめに
Metaが開発した「Llama2」というオープンソースのLLM(大規模言語モデル)が2023年7月18日にリリースされました。
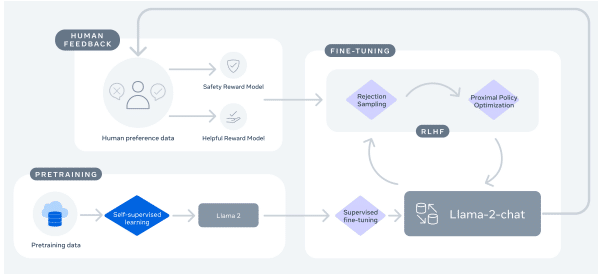
Metaは、AI技術のオープン化を推進していて、その中の1つがLlama2です。
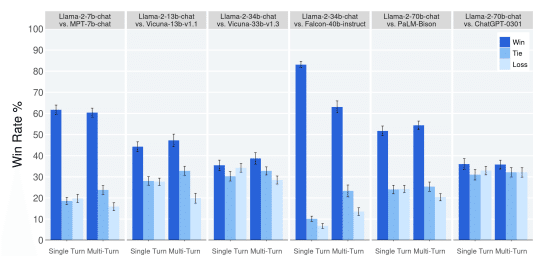
「Llama 2 (70B)」は他のオープンソースLLM(大規模言語モデル)に比べ大きくパフォーマンスで上回っています。
OpenAIのChatGPT-0301と互角の性能 とも言われています。
現在無料で、研究や商業利用に利用できます。
ChatGPTはそれほど価格が高いというわけではないですが、無料で使えるのは魅力的ですね。
Llama2の論文を見ると、ChatGPTより性能は少し上回るようです。
ハイスペックなGPUがないと動かないと思ってしばらく敬遠していましたが、ふと調べてみるとなんとCPUだけでも動くようです。
そんなLlama2ですが遅ればせながらどんなものか試してみました。
Llama2
環境
以下の低スペックなPCを使いました。
CPU: Intel(R) Core(TM) i3-4130T CPU @ 2.90GHz
メモリ: 16GB
この程度のスペックで本当に動くのでしょうか?
ダウンロード
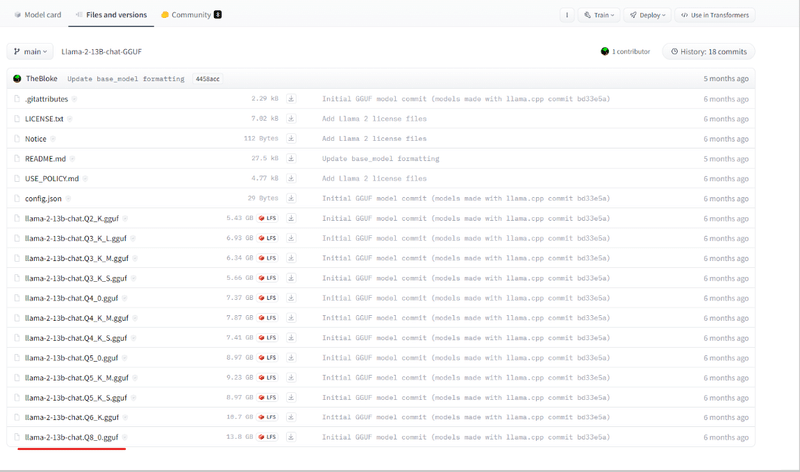
一番したの
llama-2-13b-chat.Q8_0.gguf
をダウンロードします。
Llama.cppのダウンロードとビルド
gitでllama.cppをダウンロードしてビルドします。
$ git clone https://github.com/ggerganov/llama.cpp
$ cd llama.cpp/
$ make ダウンロードしたモデルをmodels配下に移動
場所は任意ですがmodelsディレクトリがあるのでそこに移動します。
$ mv ../llama-2-13b-chat.Q8_0.gguf ./models/実行
mainという実行ファイルがカレントディレクトリにありますのでそれを実行します。
$ ./main -m ./models/llama-2-13b-chat.Q8_0.gguf --temp 0.1 -p "### 依頼: AIの未来のロードマップをMermaidで出力してください\n\n ### 回答: "実行するとずらずらとターミナルに文字が出力されていきます。
Log start
main: build = 2348 (82cb31eb)
main: built with cc (Debian 10.2.1-6) 10.2.1 20210110 for x86_64-linux-gnu
main: seed = 1709732114
llama_model_loader: loaded meta data with 19 key-value pairs and 363 tensors from ./models/llama-2-13b-chat.Q8_0.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096結果
$ ./main -m ./models/llama-2-13b-chat.Q8_0.gguf --temp 0.1 -p "### 依頼: AIの未来のロードマップをMermaidで出力してください\n\n ### 回答: "
Log start
main: build = 2348 (82cb31eb)
main: built with cc (Debian 10.2.1-6) 10.2.1 20210110 for x86_64-linux-gnu
main: seed = 1709824309
llama_model_loader: loaded meta data with 19 key-value pairs and 363 tensors from ./models/llama-2-13b-chat.Q8_0.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 5120
llama_model_loader: - kv 4: llama.block_count u32 = 40
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 13824
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 40
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 40
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: general.file_type u32 = 7
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type q8_0: 282 tensors
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 5120
llm_load_print_meta: n_head = 40
llm_load_print_meta: n_head_kv = 40
llm_load_print_meta: n_layer = 40
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 5120
llm_load_print_meta: n_embd_v_gqa = 5120
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 13824
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 13B
llm_load_print_meta: model ftype = Q8_0
llm_load_print_meta: model params = 13.02 B
llm_load_print_meta: model size = 12.88 GiB (8.50 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.14 MiB
llm_load_tensors: CPU buffer size = 13189.86 MiB
### 依頼: AIの未来のロードマップをMermaidで出力してください\n\n ### 回答: AIの未来のロードマップは、以下のような4つのトピックに分かれます。\n\n1. Deep Learning\n2. Natural Language Processing (NLP)\n3. Computer Vision\n4. Robotics and Autonomous Systems\n\n各トピックには、さらに以下のようなサブトピックが含まれています。\n\n1. Deep Learning:\n * Neural Network Architectures (Convolutional, Recurrent, etc.)\n * Training and Optimization Techniques (Gradient Descent, Adam, etc.)\n * Applications in Computer Vision, NLP, and Robotics\n2. Natural Language Processing (NLP):\n * Word Embeddings and Language Models (Word2Vec, GloVe, etc.)\n * Sentiment Analysis, Text Classification, and Named Entity Recognition\n * Machine Translation and Dialogue Systems\n3. Computer Vision:\n * Object Detection and Image Segmentation\n * Convolutional Neural Networks (CNNs) and Transfer Learning\n * Applications in Self-Driving Cars, Surveillance, and Healthcare\n4. Robotics and Autonomous Systems:\n * Robotics Platforms (ROS, TurtleBot, etc.)\n * Motion Planning and Control Algorithms (PID, LQR, etc.)\n * Applications in Manufacturing, Logistics, and Service Robots\n\nMermaid Diagram:\n\n Deep Learning\n-----------------\nNatural Language Processing (NLP)\n-----------------\nComputer Vision\n-----------------\nRobotics and Autonomous Systems\n\nThe above diagram shows the interconnectedness of the four main areas of AI research, with each area building upon the others. The diagram also highlights the progression from one area to another, with arrows indicating the flow of knowledge and techniques. For example, techniques developed in computer vision can be applied to robotics and autonomous systems, while advancements in natural language processing can improve machine translation and dialogue systems. [end of text]
llama_print_timings: load time = 134205.00 ms
llama_print_timings: sample time = 347.72 ms / 551 runs ( 0.63 ms per token, 1584.62 tokens per second)
llama_print_timings: prompt eval time = 20217.75 ms / 47 tokens ( 430.16 ms per token, 2.32 tokens per second)
llama_print_timings: eval time = 397255.40 ms / 550 runs ( 722.28 ms per token, 1.38 tokens per second)
llama_print_timings: total time = 419149.77 ms / 597 tokens
Log end
real 9m14.058s
user 27m33.919s
sys 0m10.813s
#ほんとに動きました!
動きはとても遅いですが自分のPCでLLMが動いています。
しかもGPU積んでない普通のPCで動きます。
回答文章抜粋
### 依頼: AIの未来のロードマップをMermaidで出力してください\n\n ### 回答: AIの未来のロードマップは、以下のような4つのトピックに分かれます。\n\n1. Deep Learning\n2. Natural Language Processing (NLP)\n3. Computer Vision\n4. Robotics and Autonomous Systems\n\n各トピックには、さらに以下のようなサブトピックが含まれています。\n\n1. Deep Learning:\n * Neural Network Architectures (Convolutional, Recurrent, etc.)\n * Training and Optimization Techniques (Gradient Descent, Adam, etc.)\n * Applications in Computer Vision, NLP, and Robotics\n2. Natural Language Processing (NLP):\n * Word Embeddings and Language Models (Word2Vec, GloVe, etc.)\n * Sentiment Analysis, Text Classification, and Named Entity Recognition\n * Machine Translation and Dialogue Systems\n3. Computer Vision:\n * Object Detection and Image Segmentation\n * Convolutional Neural Networks (CNNs) and Transfer Learning\n * Applications in Self-Driving Cars, Surveillance, and Healthcare\n4. Robotics and Autonomous Systems:\n * Robotics Platforms (ROS, TurtleBot, etc.)\n * Motion Planning and Control Algorithms (PID, LQR, etc.)\n * Applications in Manufacturing, Logistics, and Service Robots\n\nMermaid Diagram:\n\n Deep Learning\n-----------------\nNatural Language Processing (NLP)\n-----------------\nComputer Vision\n-----------------\nRobotics and Autonomous Systems\n\nThe above diagram shows the interconnectedness of the four main areas of AI research, with each area building upon the others. The diagram also highlights the progression from one area to another, with arrows indicating the flow of knowledge and techniques. For example, techniques developed in computer vision can be applied to robotics and autonomous systems, while advancements in natural language processing can improve machine translation and dialogue systems. [end of text]
残念ながらMermaidでは出力してくれませんでしたが、ちゃんと回答してくれました。
途中なぜか英語になってしまいましたが、回答内容としてはおかしくは無さそうです。
負荷状況
top - 22:58:25 up 1:28, 3 users, load average: 3.09, 1.38, 1.38
Tasks: 236 total, 2 running, 234 sleeping, 0 stopped, 0 zombie
%Cpu0 : 99.7 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu1 : 99.0 us, 0.7 sy, 0.0 ni, 0.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 97.0 us, 2.3 sy, 0.0 ni, 0.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 99.0 us, 0.7 sy, 0.0 ni, 0.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16154844 total, 177312 free, 2036832 used, 13940700 buff/cache
KiB Swap: 8191996 total, 8111612 free, 80384 used. 13794300 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8680 root 20 0 13.5g 13.3g 12.9g R 393.7 86.0 5:38.47 mainメモリはそこそこ使ってましたが、なんとか16GBメモリ内におさまっていて、スワップも発生しませんでした。
プロンプトを少し修正
ChatGPTよりは文章長めに回答してくる感じがします。
### 依頼: AIの未来のロードマップを日本語で教えてください\n\n ### 回答: AIの未来のロードマップは 、技術的な進捗や社会的な要求に応じて変化していくものです。以下は、現在のところ予想されるAIの未来のロードマップの一部です。
1. Deep Learning: Deep learning technologies such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) will continue to advance, enabling AI systems to perform more complex tasks with greater accuracy.
2. Natural Language Processing (NLP): NLP will become increasingly important as AI systems are used to analyze and generate human language. Expect significant advances in machine translation, sentiment analysis, and text summarization.
3. Computer Vision: Computer vision will continue to improve, enabling AI systems to interpret and understand visual data from images and videos. Applications include self-driving cars, surveillance, and medical imaging.
4. Robotics: Robotics will become more prevalent as AI systems are integrated with physical devices to perform tasks such as assembly, maintenance, and transportation.
5. Edge AI: With the proliferation of IoT devices, edge AI will become increasingly important as AI processing is performed at the edge of the network, reducing latency and improving real-time performance.
6. Explainability and Transparency: As AI systems become more ubiquitous, there will be a growing need for explainability and transparency in AI decision-making. Expect significant advances in techniques such as feature attribution and model interpretability.
7. Ethics and Fairness: With the increasing use of AI in critical applications, there will be a growing focus on ethics and fairness in AI development. Expect significant advances in techniques such as debiasing and fairness metrics.
8. Human-AI Collaboration: As AI systems become more advanced, they will be used to augment human capabilities, rather than replace them. Expect significant advances in human-AI collaboration, particularly in areas such as healthcare and education.
9. AI for Social Good: There will be a growing focus on using AI for social good, such as improving healthcare outcomes, reducing poverty, and mitigating the effects of climate change.
10. Quantum AI: With the emergence of quantum computing, there will be a growing focus on developing quantum AI algorithms that can take advantage of quantum computing's unique capabilities.
These are just a few of the many trends and developments we can expect to see in the field of AI in the coming years. As always, it is an exciting time for AI researchers and practitioners, and we can look forward to many new advances and innovations in the years ahead. [end of text]
電卓アプリのコード生成
プログラムのコードを生成してくれるか試してみました。
### 依頼: 電卓アプリをpythonのコードで生成してください。\n\n ### 回答: はい、以下はPythonのコードで電卓アプリを生成する方法です。
import tkinter as tk
from tkinter import ttk
# ウィンドウの作成
window = tk.Tk()
window.title("電卓アプリ")
# フレームの作成
frame = tk.Frame(window)
frame.pack()
# 数字入力エリアの作成
num_input = ttk.Entry(frame, width=10)
num_input.pack()
# 計算ボタンの作成
calculate_button = tk.Button(frame, text="計算", command=calculate)
calculate_button.pack()
def calculate():
# 数字入力エリアから数値を取得
num1 = int(num_input.get())
# 計算する
result = num1 + num1
# 結果を表示する
tk.messagebox.showinfo("Result", "計算結果:" + str(result))
# ウィンドウの表示
window.mainloop()
このコードでは、電卓アプリを作成しています。ウィンドウには、数字入力エリアと計算ボタンがあります。計算ボタンを押すと、数値を入力した結果を表示することができます。
このコードでは、tkinterライブラリを使用しています。tkinterはPythonでグラフィカルユーザインタフェースを作成するためのライブラリです。特に、ttkモジュールはtkinterライブラリの中で、より高度なグラフィカルユーザインタフェースを作成するためのものです。
このコードを実行すると、電卓アプリが表示されます。ウィンドウには、数字入力エリアと計算ボタンがあります。計算ボタンを押すと、数値を入力した結果を表示することができます。 [end of text]
実際動かしてないですが、Pythonのコードも生成してくれます。
まるでChatGPTみたいですね。
これほど賢い生成AIが普通のスペックのPCで動くのは少し感動です。
まとめ
ChatGPT相当のパフォーマンスと言われている無料のオープンソースLlama2を試してみました。
ChatGPTと変わり映えはないですが、大きな違いは自分のPCで動いてくれるという点が大きな違いです。
機密性のある情報など、どうしても外部にデータを出せずにChatGPTが使えない場合など、オンプレでLLMを動かすことができるので、外部に情報が出ていかないのが大きなメリットかなと思います。
あとファインチューニングでデータ拡張もできるようなので今後試してみたいと思います。
この記事が気に入ったらサポートをしてみませんか?