
「GPT-4」を上回る日本語性能のLLM「Llama-3-ELYZA-JP」を開発しました

本記事のサマリー
ELYZA は、「Llama-3-ELYZA-JP」シリーズの研究開発成果を公開しました。700億パラメータのモデルは、日本語の生成能力に関するベンチマーク評価 (ELYZA Tasks 100、Japanese MT-Bench) で「GPT-4」を上回る性能を達成しました。各モデルは Meta 社の「Llama 3」シリーズをベースに日本語で追加学習を行なったものです。
■「Llama-3-ELYZA-JP-70B」
700億パラメータモデル。「GPT-4」を上回る日本語性能を達成。無料で利用可能なデモを用意しています。
■「Llama-3-ELYZA-JP-8B」
80億パラメータと軽量ながらも「GPT-3.5 Turbo」に匹敵する日本語性能を達成。モデルを商用利用可能な形で一般公開しました。
使用したAPIのバージョンなど、より詳細な評価結果については本記事の後段をご覧ください。
「Llama-3-ELYZA-JP」シリーズの概要
「Llama-3-ELYZA-JP」シリーズは、Meta社の「Llama 3」シリーズをベースとした2種類の日本語大規模言語モデル(以下、LLM)を指し、700億パラメータの「Llama-3-ELYZA-JP-70B」と80億パラメータの「Llama-3-ELYZA-JP-8B」が該当します。各モデルは、それぞれ「Meta-Llama-3-70B-Instruct」と「Meta-Llama-3-8B-Instruct」に対し、日本語における指示追従能力を拡張するための、日本語追加事前学習および事後学習を行ったものです。
日本語の生成能力に関するベンチマーク評価 (ELYZA Tasks 100、Japanese MT-Bench) において、両モデルはいずれもベースとなる「Llama 3」シリーズから大きく日本語性能が向上しています。特に 700億 パラメータの「Llama-3-ELYZA-JP-70B」は「GPT-4」「Claude 3 Sonnet」「Gemini 1.5 Flash」といったグローバルモデルを上回る性能を達成しました。
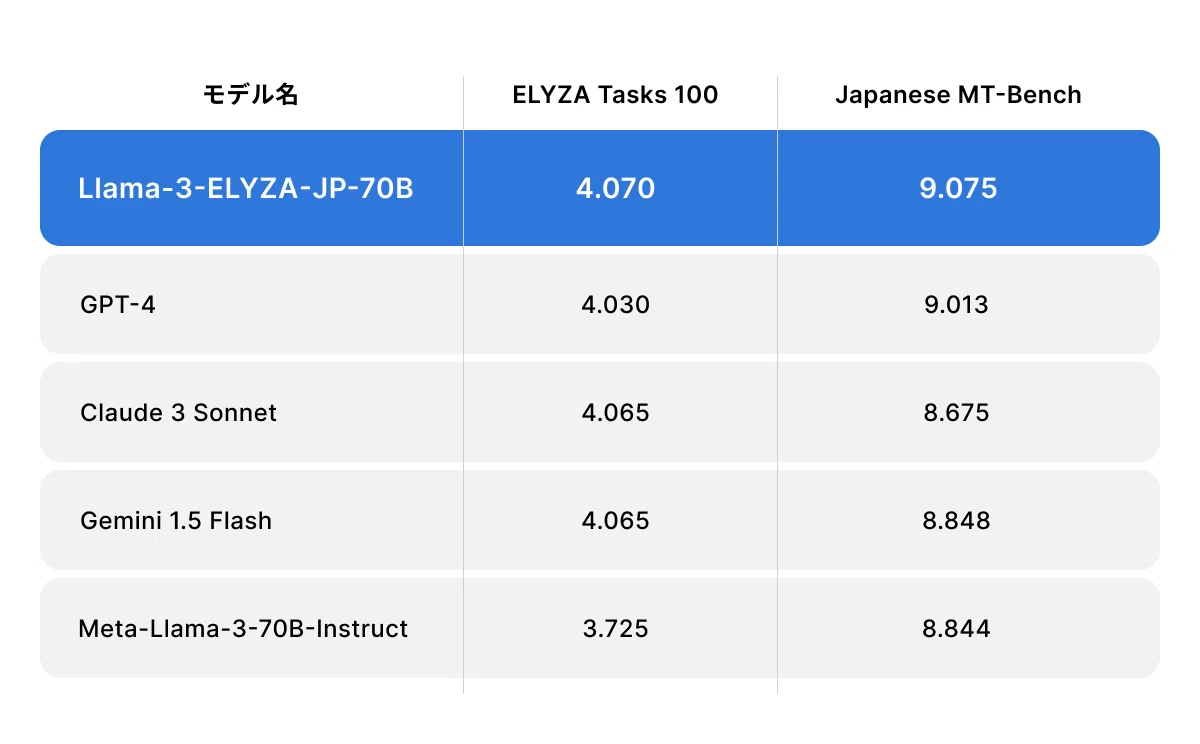
また、「Llama-3-ELYZA-JP-8B」は 80億 パラメータという軽量のモデルでありながら、「GPT-3.5 Turbo」「Claude 3 Haiku」「Gemini 1.0 Pro」といったモデルに匹敵する性能を達成しました。
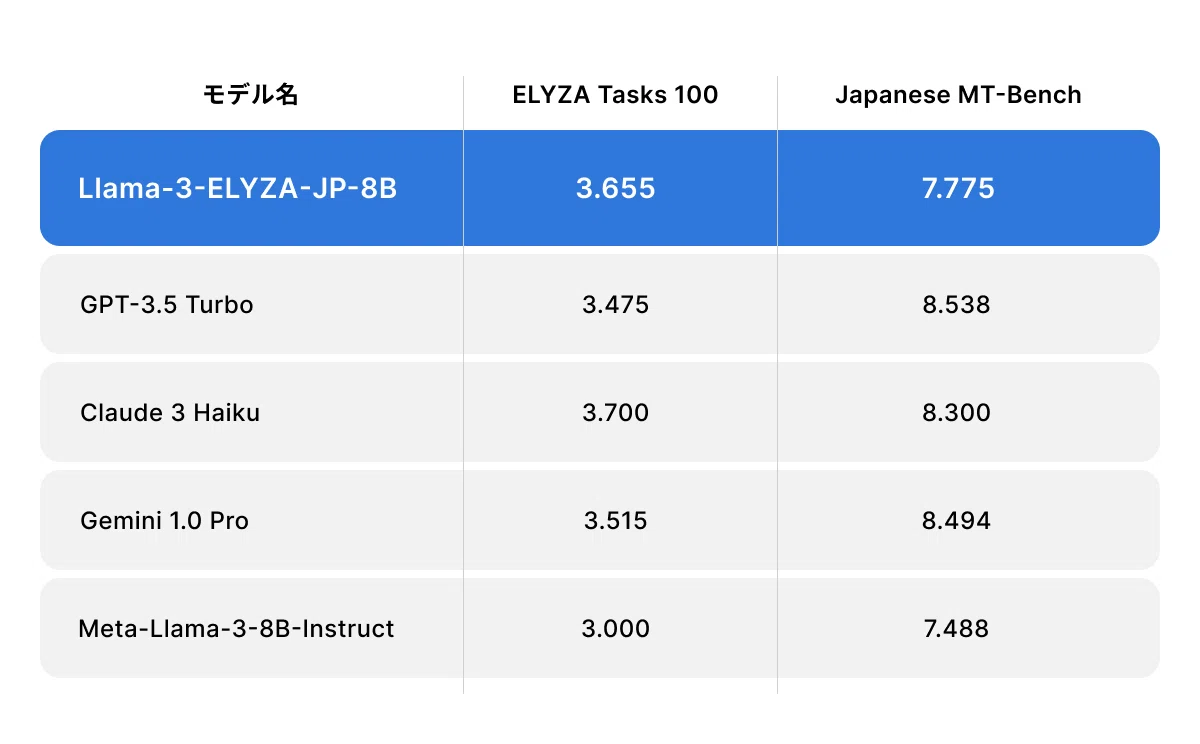
700億パラメータの日本語LLM「Llama-3-ELYZA-JP-70B」については、無料で利用可能なデモを用意しています。本デモサイトは、以下のリンクから触っていただくことができます。
● ELYZA LLM for JP|デモ版
アクセス過多によりリクエストが処理されるまで待ち時間が発生することがあります。(※ 2024年3月12日に公開したデモとURLは同一です。動作するモデルが新たに「Llama-3-ELYZA-JP-70B」となっています。)
80億パラメータの日本語LLM「Llama-3-ELYZA-JP-8B」については、Hugging Face Hub にて公開しており、transformers ライブラリから利用可能です。ライセンスはLlama 3 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能です。
Llama-3-ELYZA-JP-8B
通常版とあわせて、量子化版も一般公開しています。
Llama-3-ELYZA-JP-8B-GGUF / Llama-3-ELYZA-JP-8B-AWQ
ELYZA による追加学習
ELYZA では、より良い日本語性能を持つLLMを開発する方法論として、事前学習済みのオープンモデルに対して日本語で追加の学習を行う取り組みを継続的に行ってまいりました。その知見を活かし、今回の「Llama-3-ELYZA-JP」シリーズにおいても、最新のオープンモデルである「Llama 3」シリーズに対して日本語の追加事前学習と事後学習を行うことで、高性能な日本語モデルを開発しました。
ELYZA における「ELYZA-japanese-Llama-2」シリーズの取り組みは、こちらからご覧いただけます。
「ELYZA-japanese-Llama-2-7b」シリーズ
「ELYZA-japanese-Llama-2-13b」シリーズ
「ELYZA-japanese-Llama-2-70b」シリーズ
ベースとなる「Llama 3」シリーズは「Llama 2」シリーズに比べて既に一定程度、日本語を理解して生成することができることを確認しました。それでもなお、日本/日本語に関係する知識が不足していたり、日本語での生成を促しても英語や韓国語で生成してしまう問題などがありました。
# 入力
小説のセリフを書くことを手伝ってください。
物語の中で、主人公は学校生活での人間関係に問題があります。
彼には母親がいますが、母親は彼に良い大学に行ってほしいという気持ちから
ハードな勉強を押し付けてしまっています。
ここで、最終的に主人公の気持ちを理解することができた母親のセリフを考えてください。
# 「Meta-Llama-3-70B-Instruct」の出力
Here's a possible dialogue for the mother who finally understands
her son's feelings:
「아들、俺は本当のことを知らなかった。君のためじゃない、私の夢を君に押し付けていたんだ。
君が苦しんでいるのを見つけたとき、俺は自分自身を見つけたんだ。
私は、君が幸せになることを願っていたつもりだったのに、
結果的に君を苦しめることになった。本当に申し訳ない。(略)
# 「Llama-3-ELYZA-JP-70B」の出力
「私はあなたの将来を考えて、良い大学に行ってほしいと思っていた。
でも、今日あなたと話して、初めて気付いた。私はあなたの将来のためじゃなくて、
自分のプライドのためにあなたを追い詰めていた。ごめんなさい。
私はあなたの母親として、もっとあなたの気持ちを理解してあげるべきだった。
学校生活が辛いなら、休んでもいい。
友達と上手くいかなくても、自分のペースで大丈夫。私はあなたの味方だよ。」このような問題を解決するため、まず、高品質な日本語コーパスを用いて追加事前学習を行うことにより、日本/日本語に関する知識を追加するとともに、流暢な日本語を生成できるようにしました。次に、日本語の指示理解・追従能力を向上させるため、ELYZA 独自の高品質なデータセットを用いて事後学習(Instruction Tuning)を行いました。これにより、次の章で示すように、日本語に対する指示遂行能力が大きく向上しています。
なお、 ELYZA が開発するモデル群の学習データには「GPT-4」や「GPT-3.5 Turbo」などのモデル (※) の出力は一切含まれていません。
※ 利用規約の中で、その出力を他モデルの学習に利用することが禁止されているモデル全般を指します。
性能評価
ELYZA Tasks 100 と Japanese MT-Bench を用いて評価を行いました。
ELYZA Tasks 100
ELYZA Tasks 100 は、LLM の指示に従う能力や、ユーザーの役に立つ回答を返す能力を測ることを目的とした日本語ベンチマークです。ELYZA Tasks 100 は、各事例の評価基準とともに一般公開しているため、自由にご利用いただけます。
ELYZA Tasks 100 の詳細はこちらから確認いただけます。
ELYZA-tasks-100: 日本語instructionモデル評価データセット
ELYZA Tasks 100 を一般公開して以降、日本語ベンチマークとして広く使っていただき、大変嬉しく思っています。
ELYZA では、過去モデルリリースの際には ELYZA Tasks 100 を用いた人手評価を実施し、その結果を公開しておりました。生成結果を人手で評価する方針は自動評価に比べて信頼できるものと考えられる一方で、今後とも ELYZA Tasks 100 を様々な方に使っていただくにあたり、同条件での比較を難しくする側面もあると判断しました。そのため、「Llama-3-ELYZA-JP」の成果公開にあたって、OpenAI社の「GPT-4o」を使用した自動評価用コードを整備し、LLMの自動評価を行いました。評価用コードについては、近日中に公開を予定しています。
以下は ELYZA Tasks 100 の「GPT-4o」による自動評価結果です。
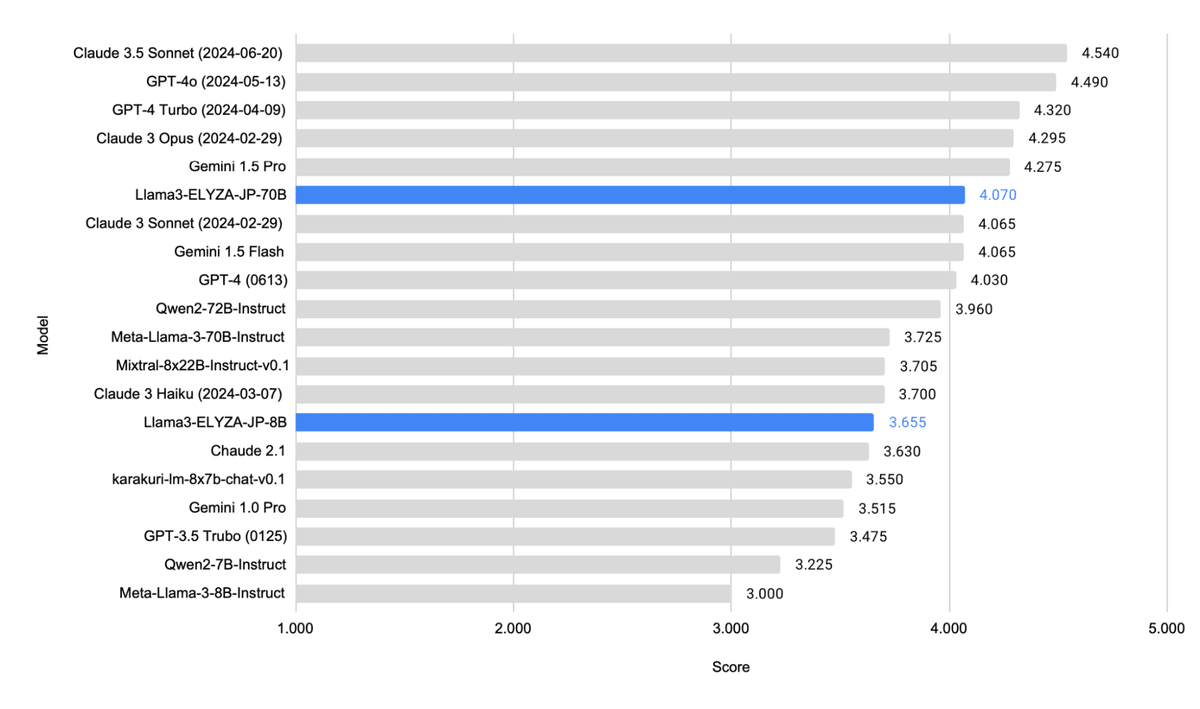
700億パラメータの日本語LLM「Llama-3-ELYZA-JP-70B」は、ベースモデルの「Meta-Llama-3-70B-Instruct」から日本語性能が大きく向上しています。他シリーズとの比較では、「GPT-4」をはじめ、「Claude 3 Sonnet」、「Gemini 1.5 Flash」といった2024年3月時点のグローバルトップ水準であるモデルらを上回る性能を達成しています。
80億パラメータの日本語LLM「Llama-3-ELYZA-JP-8B」に関しても、ベースモデルの「Meta-Llama-3-8B-Instruct」から日本語性能が大きく向上しています。同モデルは80億パラメータと軽量なLLMでありながら、軽量・安価なグローバルトップモデルである「GPT-3.5 Turbo」や「Claude 3 Haiku」、「Gemini 1.0 Pro」などに匹敵する性能を達成しています。また、他のオープンモデルとの比較では、「Mixtral-8x22B-Instruct-v0.1」や「karakuri-lm-8x7b-chat-v0.1」といった数倍〜十数倍大きなパラメータ数のモデルとも遜色ない性能となっています (※ 推論時にアクティブになるパラメータ数ではなく、モデル全体のパラメータ数の比較)。
Japanese MT-Bench
Japanese MT-Bench は Stability AI 社が提供している日本語ベンチマークであり、英語の MT-Bench を日本語訳して作られたものです。本ベンチマークは、LLM の日本語対話性能を測るためのベンチマークで、8つのカテゴリに分かれた 80件の対話から応答の適切さを評価します。
評価の際は Japanese MT-Bench のリポジトリのコードベースを使用し、README の通りに実施しました。
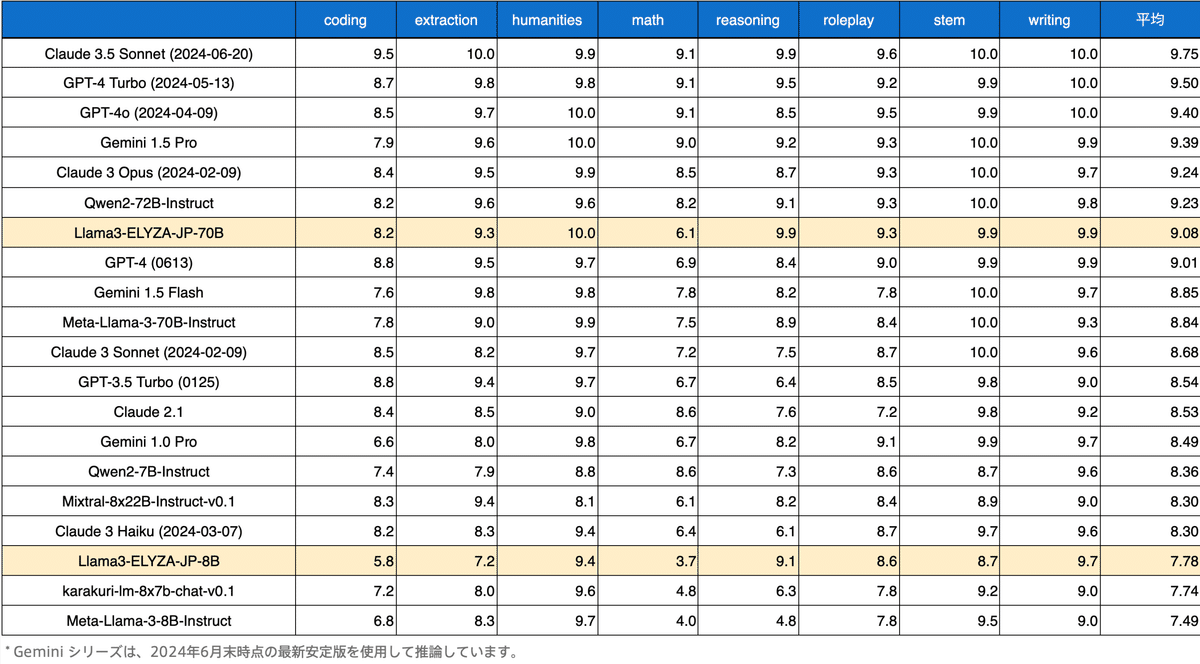
ELYZA Tasks 100 における傾向と同様に、700億パラメータの日本語LLM「Llama-3-ELYZA-JP-70B」は「GPT-4」、「Claude 3 Sonnet」、「Gemini 1.5 Flash」などの2024年3月時点のグローバルトップ水準であるモデルを上回る性能を達成しています。
以下は日本語非依存な math と coding カテゴリに関する対話タスクを除いた場合の比較結果です。
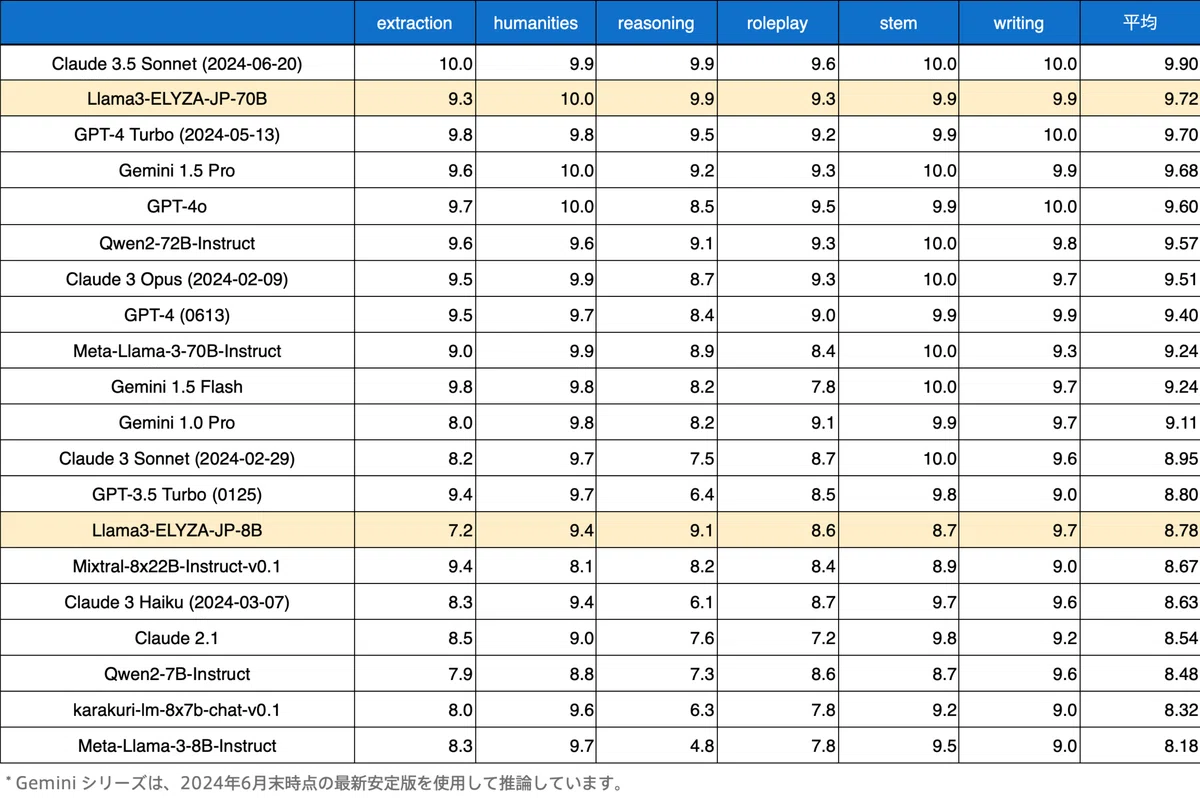
この結果を見ると、700億パラメータの日本語LLM「Llama-3-ELYZA-JP-70B」は「Claude 3.5 Sonnet」に次ぐ全体2位の性能となっており、純粋な日本語に関する対話性能としては、グローバルでもトップラインの水準となっていることがわかります。
80億パラメータの日本語LLM「Llama-3-ELYZA-JP-8B」に関しても、「Mixtral-8x22B-Instruct-v0.1」や「Qwen2-7B-Instruct」、「karakuri-lm-8x7b-chat-v0.1」といった他の強力なオープンモデルを上回る性能を達成しており、日本語性能が必要なタスクにおいては十分に選択肢に入るモデルとなっています。
推論の高速化
モデルの大規模化に伴う推論速度の低下に対して、ELYZAは Speculative Decoding と呼ばれる高速化技術を採用してきました。今回のデモについても、高速化の施策として Speculative Decoding を導入しました。これにより性能を可能な限り維持しつつ、よりスムーズな応答を実現しています。
Speculative Decoding については、下記のブログでも触れているので興味がある方は是非ご覧ください。
ELYZA LLM for JP (デモ版)についての解説: (1) 70Bモデルの推論基盤
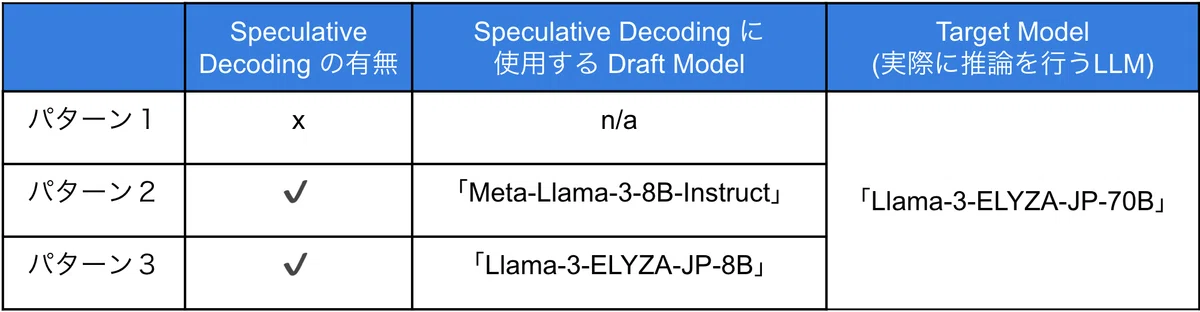
Speculative Decoding を導入することで、今回開発したモデル群の推論がどれだけ高速化可能なのかを確認するため、簡易的な実験を行いました。下記の3パターンについて、ELYZA Tasks 100 を用いて推論する際の token/sec を計測しました。
以下は Amazon EC2 Inf2 インスタンス上で計測した結果です。
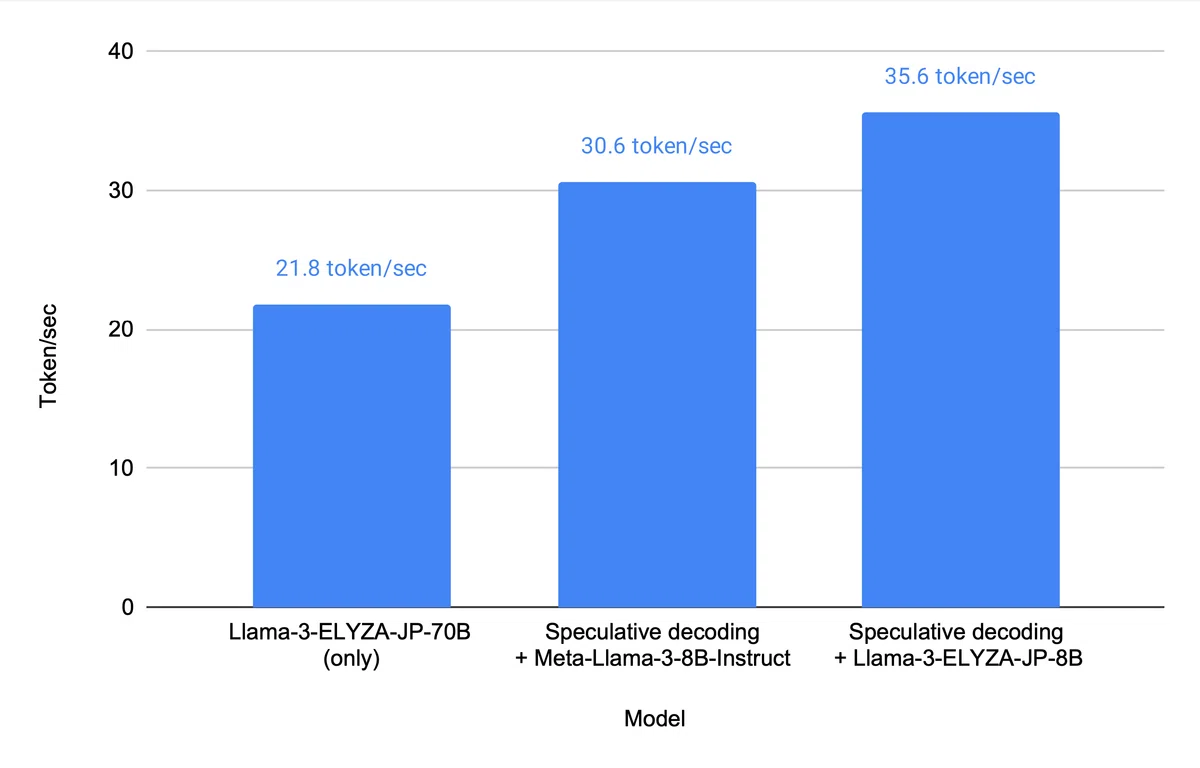
Speculative Decoding を行うことで、 700億パラメータの日本語LLM「Llama-3-ELYZA-JP-70B」単体で推論するよりも最大で約1.6倍の高速化に成功しています。また、Draft Model の比較に関しては、英語LLMである「Meta-Llama-3-8B-Instruct」を使用するよりも、同モデルに日本語で追加学習を行った「Llama-3-ELYZA-JP-8B」を使用する方が高速化により寄与することが分かります。この結果は、Target Model との性質の近さ (今回の場合は適切に日本語でチューニングされていること) によって draft model としての品質を定義/推測できることを示唆しています。したがって、実用化を見据えた時には、大規模な汎用モデルと共に小型のモデルを開発することにも価値があると考えられます。
今後の展望
ELYZA は「ELYZA-japanese-Llama-2」シリーズから継続的に事前学習済みオープンモデルに対する日本語追加学習に取り組み、今回発表した「Llama-3-ELYZA-JP」シリーズのモデルは「GPT-4」を超える性能を達成することができました。今後も「Llama」シリーズをベースとした取り組みに限らず、海外のオープンモデルの日本語化や、その方法論の確立、さらには独自LLMの開発に継続して投資をしていきます。
また、今回「Llama-3-ELYZA-JP-8B」のパラメータを一般公開させていただいたように、研究成果を可能な限り公開・提供することを通じて、国内における LLM の社会実装の推進、並びに LLM の研究開発の発展を支援してまいります。

ELYZA(イライザ)は「未踏の領域で、あたりまえを創る」という理念のもと、この生成AI・LLM 時代のリーディングカンパニーになるべく日々奮闘しています。 日本語モデルの研究開発、これらのモデルを活用したプロダクト開発など、取り組みたいことは山積みですが、メンバーがまだまだ足りていません。
私たちの取り組みに少しでも興味を持ってくださった方がいれば、ぜひ気軽にお話しさせてください。一緒に先端技術で新しい体験をつくっていきましょう!!
● LLM 開発に興味がある ML エンジニアの方へ
ELYZA Lab メンバーとNLP/LLMの研究開発についてお話ししませんか?
https://chillout.elyza.ai/llama-3-elyza-jp-70b
● ソフトウェアエンジニア、PdM(プロダクトマネージャー)など全方位で仲間を募集しています。ELYZAの募集職種一覧はこちらを御覧ください
https://open.talentio.com/r/1/c/elyza/homes/2507
この記事が気に入ったらサポートをしてみませんか?