
【統計の勉強】多群検定の手順①Googleスプレッドシートでデータを準備する

こんにちは。論文のデータの質を上げるために、Rの勉強をしている生命科学系研究者のえいこです。
Rは、プログラミング言語であり統計言語でもあるのが特徴。
プログラミングを勉強するのはもちろん、統計の勉強もしなければなりません...
大学時代に「生物統計学」と言う講義は有って、単位もちゃんと取ってはいるのですが。
研究室で実際にデータと対峙すると、どんな統計処理をしたら良いのか分からないことが多々あります。
とりあえず先輩に言われたから、「2群検定はStudentのt検定をする」「多群比較時は有意差が出やすいからTukey-Kramerを使う」と言われてそのままやっていました...
(実はちゃんと統計の勉強をしている研究者ってあまりいないのでは??)
そして、論文投稿するとJournal側から「ちゃんと統計処理したの?」と聞かれて冷や汗をかくのです。
日頃の実験データからきちんと統計に向き合っていれば、論文を投稿してから焦ることはないのでは?R言語の勉強も始めたし、「統計もきちんと勉強しよう!」と言うのが「1からの統計」の趣旨です。
以前の記事で「2群検定」についてはまとめたので、今回は「多群比較検定」について数回にわたってまとめていこうと思います。
今回は、これから多群比較検定をするためのサンプルデータを準備することから始めます。
今回やること
・Googleスプレッドシートでサンプルデータを準備する
・CSVファイルとして出力する
・RStudio Cloudにデータを移す
多群比較用のサンプルデータを準備する
できるだけ、研究室でよく見るデータの形を使って比較検定をしたいと思っています。
なので、サンプルデータについてこんな前提を作ってみました。
(前提1)比較する群は3群
(前提2)3群のうち1つは比較対照群(コントロール)
(前提3)各グループのサンプル数は7
研究室でよくやる実験だとこのくらいのデータ数の人が多いのではないでしょうか?
実際の実験データを使うのではなくて、今回はGoogleスプレッドシートで作ってみようと思います。(もちろんExcelでも作れます)
私は通常iPadを使っていて、Excelを入れていません。
そのかわりGoogleのスプレッドシートを使っています。
まずgoogleのスプレッドシートを開いて、データフレームの準備をします。

“A“列にグループの名前(group)を、”B”列にそれぞれのデータの値(value)を入れていきます。
A列のグループはそれぞれ7つのデータが入るように準備しておきます。
データの値は”RAND()”関数で発生させます。”C”列に値を準備していきます。
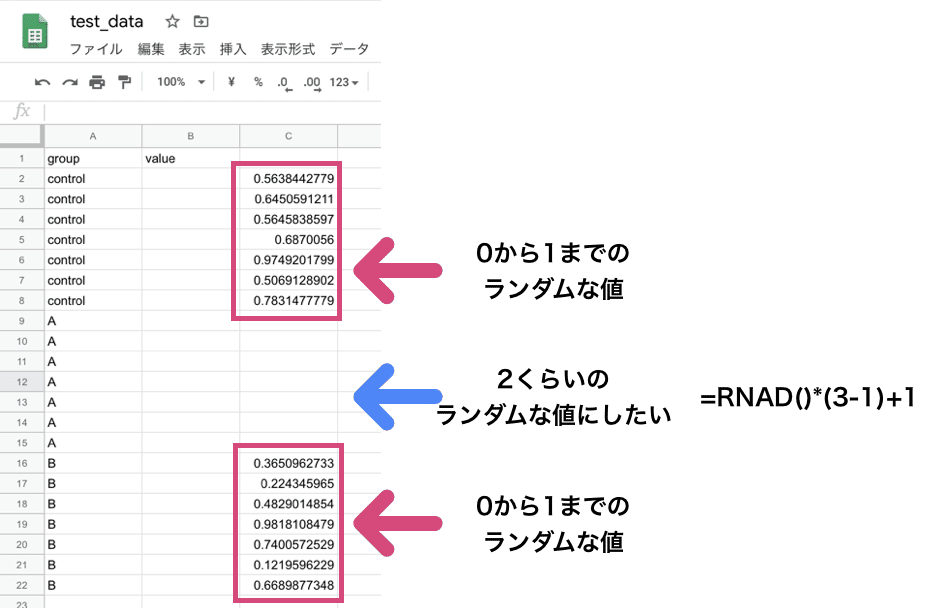
今回は、controlとB群はほとんど同じでA群だけ少し高い値をとるということデータの設定にしておきます。

“C”列にデータが準備できたら、データをコピペして貼り付けます。が、RAND関数は何かするたびに値がコロコロ変わってしまうので「値を貼り付け」にしておきます。

これで、データの準備ができました。
今回準備したデータはあえて、正規分布にしませんでした。(Excelの関数で正規分布になるように値をばらつかせることができます)
実験で出るデータって(特にサンプルサイズが小さいと)正規分布に入る保証はありません。
ここまでランダムかどうかはわかりませんが、結構データの間でばらつきが大きいと言うことを想定した方が多群検定の練習になるのではないかと思って、こんなサンプルデータの作り方をしてみました。
作ったサンプルデータをCSVファイルにして保存する
できればGoogleドライブから直接RStudio Cloudに移行できると良いのですが、その方法は少し難しそう...
と言うことで、一回iPadのディバイス側に保存してからRStudio Cloudに移行してみます。
まずは、CSVの形でファイルを保存してきます。
ファイル→ダウンロード→カンマ区切りの値でCSVファイルとし保存できます。
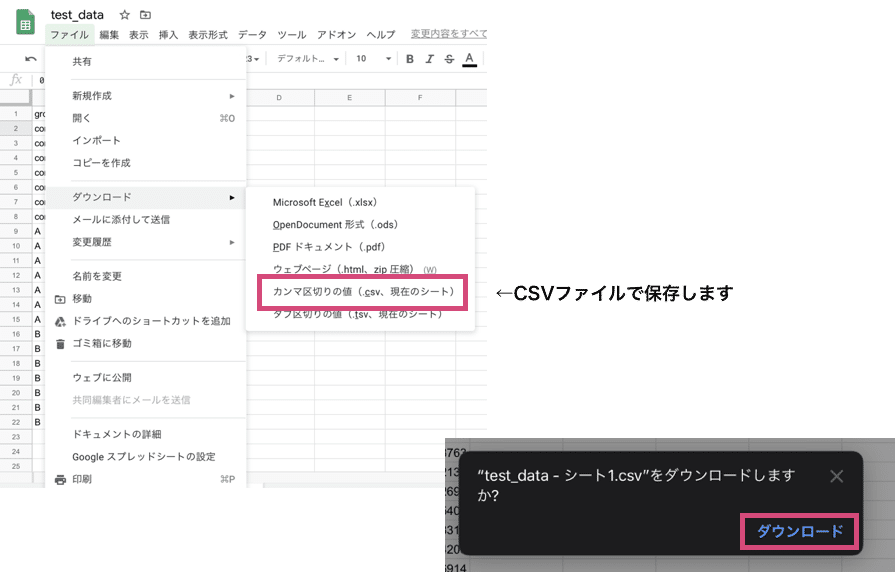
ダウンロードを押すと、フォルダのダウンロードフォルダに保存されています。
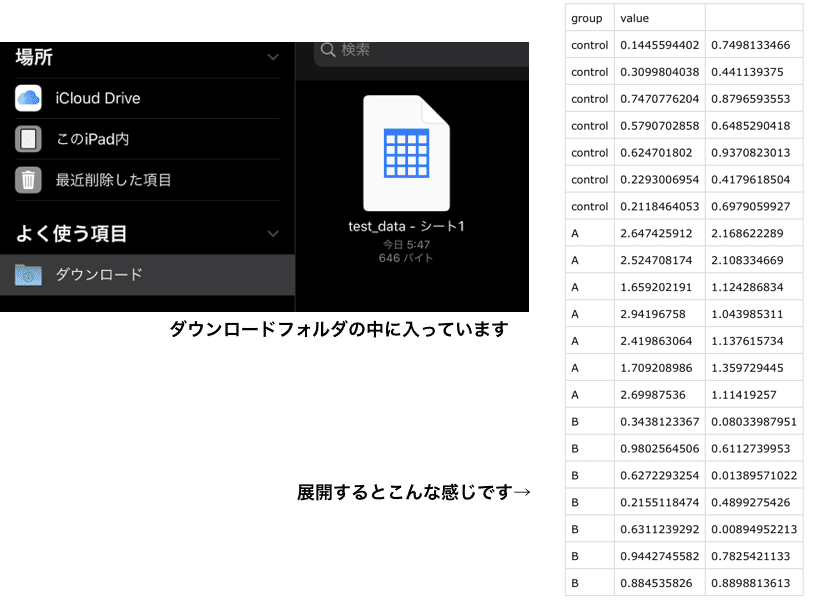
ファイルを展開すると、作ったデータが格納されているのが確認できました。
このファイルをRStudio Cloudに移していきます。
RStudio Cloudにデータを移す
インストール版のRStudioを使っている場合は、ディレクトリを指定してそのまま”read.csv()”で呼び出せます。
RStudio Cloudの場合は、一回RStudio Cloudのディレクトリにファイルをアップロードする必要があります。
アップロードする手順は、
・ RStudio Cloud上にファイルを入れるフォルダを作る
・ ファイルをアップロードする
まずは、RStudio Cloud上にフォルダを作っていきます。
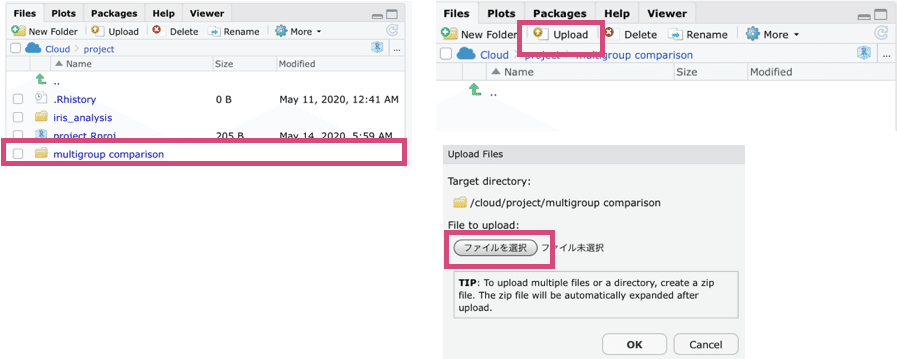
右下のFilesからNew Folderを選択します。
デフォルトのディレクトリの場所は”Cloud/project”になっているんで、今回はprojectの下にフォルダを作っていきます。
New Floderをタップすると右の画面が出てくるのでフォルダ名を入れてOKを押します。
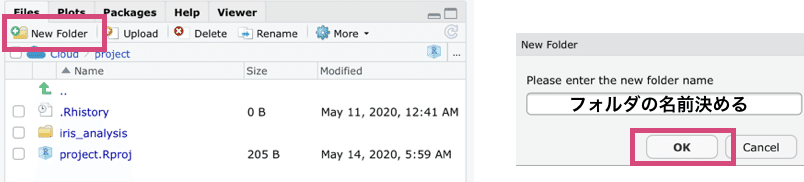
今回はフォルダ名を”multigroup comparison”にしました。
ファイル名をタップするとフォルダが開かれます。
Uploadボタンを押してファイルをアップロードしていきます。ファイルを選択をタップ。
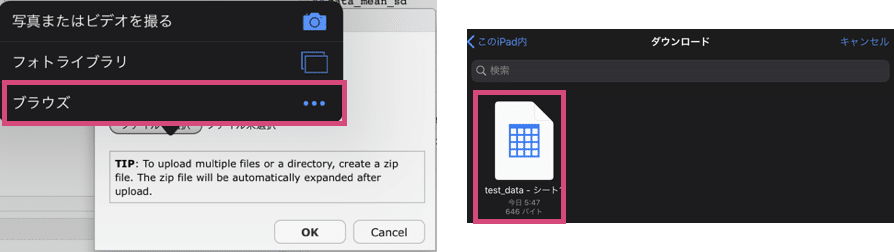
ファイルを引っ張ってくる場所を聞かれるので、「ブラウズ」を選択します。
(今回アップロードしようとしているファイルは、ダウンロードフォルダに入っているので...)
アップロードするファイルをタップすれば、アップロードされます。
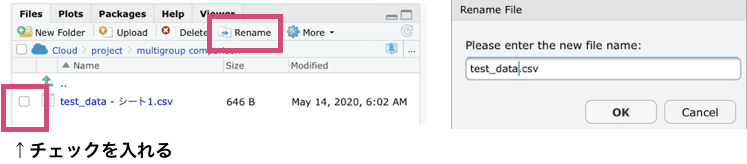
アップロードされたファイルの名前を見てみると、「test_data- シート1.csv」となっています。
後ろの「-シート1」の部分は必要がないので、ファイル名を変更していきます。
RStudio Cloudは日本語対応があまりできていなそうなので、できるだけ日本語を使わないようにしていきます。
ファイルの横のチェックボックスにチェックを入れて、右上のRenameを押してファイル名を変更します。
アップロードしたファイルの確認をしていきましょう。
念のためスクリプト画面の上のSessionからカレントディレクトリを指定しておきます。(Filesで開いているところがカレントディレクトリっぽいのですが)
data<- read.csv(“test_data.csv”, header=“T”, sep=“,”)で、dataという変数に格納します。
右上のEnvrionment画面でdataをクリック、もしくは、view(data)でデータを確認できます。
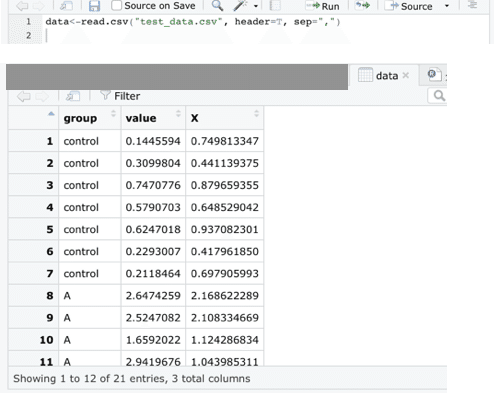
これでデータの準備はOKです。
っていうか、統計の勉強って銘打っておきながら統計の勉強は一切していないという...
次回からちゃんと多群検定をしていきたいと思います。
それでは、また!
最後までお読みいただきありがとうございます。よろしければ「スキ」していただけると嬉しいです。 いただいたサポートはNGS解析をするための個人用Macを買うのに使いたいと思います。これからもRの勉強過程やワーママ研究者目線のリアルな現実を発信していきます。