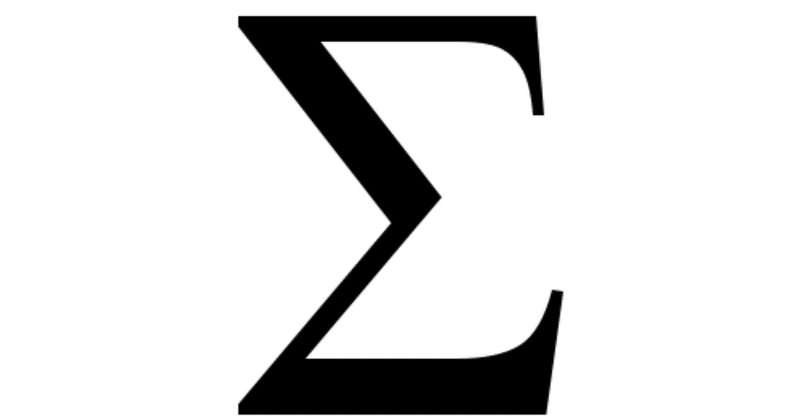Imagine what you can achieve by "dockerizing" your web applications? Isolating and achieving fast deployment are just the two advantages to start with and we barely scratch the surface. Read this weekly release of magazine on Docker to learn more about this big blue wonder.
We've been wanting to ask this for a long time - "So what is Recursion?"According to LeetCode, Recursion is an approach to solving problems using a function that calls itself as a subroutine.
You might wonder how we can implement a function
Array
ArrayArray is a data structure consisting of a collection of elements, each identified by at least one array index or key. The index starts from 0 (0-based numbering). Insertion, removal and search operations in arrays are fast because of r
Factorial with recursion
Ever wonder how recursion works in code? Imagine when you are given 6!, you first multiply the next integer factorial in sequence (6! = 6*5!). You repeat the process until 0 is reached. This works the same way in programming. Just think of
Adding all elements in a vector with C++
Adding the elements of a vector with a for loop looks
#include <vector>int sum(std::vector<int> nums) { // your code here int sum = 0; for (int i = 0; i < nums.size(); i++) { sum += nums[i]; } return sum;}
However, there's a way to do i
To stop or kill the container "busybox" we created, just initiate the docker stop or kill command together with the container id.
#Stopping a containerdocker stop (container id)#Killing a containerdocker kill (container id)
Let's first st
Let's get our hands dirty and kick start a docker container with busybox, an image you can download from docker hub and run a bash command within the container.
#Inputdocker run busybox echo hello world#Outputhello world
If this is yo
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster. (Wikipedia: https://en.wikipedia.org/wiki/MapReduce) Most big data analysts
A stack is an abstract data type that allows operations to store and remove values in a collection of elements. All operations have a runtime complexity of O(1) because you can only delete or add an element in the top of the stack. Elements
What is Hadoop?
Apache Hadoop is a group of open-source software utilities used for distributed storage and processing of big data based on the MapReduce model. Hadoop is seen as a solution to manage, maintain and distribute large chunks