
Photo by
dia_gg
株価分析スクリプトをブラウザ上で実行する方法

背景
過去記事で日本の自動車メーカーの株価を分析してみよう1〜6まで記述したがアクセス数がそれほどでもなかった。
理由は、そもそもPythonやらyfinanceのライブラリを自分でインストールできる人間は自分でもっと良いスクリプトを書くことなんでしょう。
ということで一般人でもとっつきやすいWebでのPython実行環境を調査した。
過去記事のまとめ
Google Colab
webでPythonを実行できる環境を調べましたが、yfinanceを実行できる環境は、Colabが良さそうです。Colabの利用には、Googleのアカウントが必要です。Colabo にアクセスしてみましょう。
例えば私のコード
import yfinance as yf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
import random
import statistics
import warnings
warnings.filterwarnings('ignore', category=pd.errors.PerformanceWarning)
#=== ここに自分のポートフォリオに選ぶ銘柄を入力する ===#
# (日経225銘柄のみ対応)
my_pf1 = '7267.T'
my_pf2 = '7011.T'
my_pf3 = '8001.T'
#=======================================Dict
# NK225要素を持つ辞書
# written by Nishiharu. https://note.com/dreamy_stilt3370/n/nb671c48ef39c
my_dict = {
#医薬品
'4151.T': '協和キリン',
'4502.T': '武田',
'4503.T': 'アステラス',
'4506.T': '住友ファーマ',
'4507.T': '塩野義',
'4519.T': '中外薬',
'4523.T': 'エーザイ',
'4568.T': '第一三共',
'4578.T': '大塚HD',
#電気機器
'6479.T': 'ミネベア',
'6501.T': '日立',
'6503.T': '三菱電',
'6504.T': '富士電機',
'6506.T': '安川電',
'6526.T': 'ソシオネクス',
'6594.T': 'ニデック',
'6645.T': 'オムロン',
'6674.T': 'GSユアサ',
'6701.T': 'NEC',
'6702.T': '富士通',
'6723.T': 'ルネサス',
'6724.T': 'エプソン',
'6752.T': 'パナHD',
'6753.T': 'シャープ',
'6758.T': 'ソニーG',
'6762.T': 'TDK',
'6770.T': 'アルプスアル',
'6841.T': '横河電',
'6857.T': 'アドテスト',
'6861.T': 'キーエンス',
'6902.T': 'デンソー',
'6920.T': 'レーザーテク',
'6952.T': 'カシオ',
'6954.T': 'ファナック',
'6971.T': '京セラ',
'6976.T': '太陽誘電',
'6981.T': '村田製',
'7735.T': 'スクリン',
'7751.T': 'キヤノン',
'7752.T': 'リコー',
'8035.T': '東エレク',
#自動車
'7201.T': '日産自',
'7202.T': 'いすゞ',
'7203.T': 'トヨタ',
'7205.T': '日野自',
'7211.T': '三菱自',
'7261.T': 'マツダ',
'7267.T': 'ホンダ',
'7269.T': 'スズキ',
'7270.T': 'SUBARU',
'7272.T': 'ヤマハ発',
#精密機器
'4543.T': 'テルモ',
'4902.T': 'コニカミノル',
'6146.T': 'ディスコ',
'7731.T': 'ニコン',
'7733.T': 'オリンパス',
'7741.T': 'HOYA',
'7762.T': 'シチズン',
#通信
'9432.T': 'NTT',
'9433.T': 'KDDI',
'9434.T': 'SB',
'9613.T': 'NTTデータ',
'9984.T': 'SBG',
#銀行
'5831.T': 'しずおかFG',
'7186.T': 'コンコルディ',
'8304.T': 'あおぞら銀',
'8306.T': '三菱UFJ',
'8308.T': 'りそなHD',
'8309.T': '三井住友トラ',
'8316.T': '三井住友FG',
'8331.T': '千葉銀',
'8354.T': 'ふくおかFG',
'8411.T': 'みずほFG',
#その他金融
'8253.T': 'クレセゾン',
'8591.T': 'オリックス',
'8697.T': '日本取引所',
#証券
'8601.T': '大和',
'8604.T': '野村',
#保険
'8630.T': 'SOMPO',
'8725.T': 'MS&AD',
'8750.T': '第一生命HD',
'8766.T': '東京海上',
'8795.T': 'T&D',
#水産
'1332.T': 'ニッスイ',
#食品
'2002.T': '日清粉G',
'2269.T': '明治HD',
'2282.T': '日ハム',
'2501.T': 'サッポロHD',
'2502.T': 'アサヒ',
'2503.T': 'キリンHD',
'2801.T': 'キッコマン',
'2802.T': '味の素',
'2871.T': 'ニチレイ',
'2914.T': 'JT',
#小売業
'3086.T': 'Jフロント',
'3092.T': 'ZOZO',
'3099.T': '三越伊勢丹',
'3382.T': 'セブン&アイ',
'8233.T': '高島屋',
'8252.T': '丸井G',
'8267.T': 'イオン',
'9843.T': 'ニトリHD',
'9983.T': 'ファストリ',
#サービス
'2413.T': 'エムスリー',
'2432.T': 'ディーエヌエ',
'3659.T': 'ネクソン',
'4324.T': '電通グループ',
'4385.T': 'メルカリ',
'4661.T': 'OLC',
'4689.T': 'ラインヤフー',
'4704.T': 'トレンド',
'4751.T': 'サイバー',
'4755.T': '楽天グループ',
'6098.T': 'リクルート',
'6178.T': '日本郵政',
'7974.T': '任天堂',
'9602.T': '東宝',
'9735.T': 'セコム',
'9766.T': 'コナミG',
#鉱業
'1605.T': 'INPEX',
#繊維
'3401.T': '帝人',
'3402.T': '東レ',
#パルプ・紙
'3861.T': '王子HD',
'3863.T': '日本紙',
#化学
'3405.T': 'クラレ',
'3407.T': '旭化成',
'4004.T': 'レゾナック',
'4005.T': '住友化',
'4021.T': '日産化',
'4042.T': '東ソー',
'4043.T': 'トクヤマ',
'4061.T': 'デンカ',
'4063.T': '信越化',
'4183.T': '三井化学',
'4188.T': '三菱ケミG',
'4208.T': 'UBE',
'4452.T': '花王',
'4631.T': 'DIC',
'4901.T': '富士フイルム',
'4911.T': '資生堂',
'6988.T': '日東電',
#石油
'5019.T': '出光興産',
'5020.T': 'ENEOS',
#ゴム
'5101.T': '浜ゴム',
'5108.T': 'ブリヂストン',
#窯業
'5201.T': 'AGC',
'5214.T': '日電硝',
'5233.T': '太平洋セメ',
'5301.T': '東海カーボン',
'5332.T': 'TOTO',
'5333.T': 'ガイシ',
#鉄鋼
'5401.T': '日本製鉄',
'5406.T': '神戸鋼',
'5411.T': 'JFE',
#非鉄・金属
'3436.T': 'SUMCO',
'5706.T': '三井金',
'5711.T': '三菱マ',
'5713.T': '住友鉱',
'5714.T': 'DOWA',
'5801.T': '古河電',
'5802.T': '住友電',
'5803.T': 'フジクラ',
#商社
'2768.T': '双日',
'8001.T': '伊藤忠',
'8002.T': '丸紅',
'8015.T': '豊田通商',
'8031.T': '三井物',
'8053.T': '住友商',
'8058.T': '三菱商',
#建設
'1721.T': 'コムシスHD',
'1801.T': '大成建',
'1802.T': '大林組',
'1803.T': '清水建',
'1808.T': '長谷工',
'1812.T': '鹿島',
'1925.T': 'ハウス',
'1928.T': '積ハウス',
'1963.T': '日揮HD',
#機械
'5631.T': '日製鋼',
'6103.T': 'オークマ',
'6113.T': 'アマダ',
'6273.T': 'SMC',
'6301.T': 'コマツ',
'6302.T': '住友重',
'6305.T': '日立建機',
'6326.T': 'クボタ',
'6361.T': '荏原',
'6367.T': 'ダイキン',
'6471.T': '日精工',
'6472.T': 'NTN',
'6473.T': 'ジェイテクト',
'7004.T': '日立造',
'7011.T': '三菱重',
'7013.T': 'IHI',
#造船
'7012.T': '川重',
#その他製造
'7832.T': 'バンナムHD',
'7911.T': 'TOPPAN',
'7912.T': '大日印',
'7951.T': 'ヤマハ',
#不動産
'3289.T': '東急不HD',
'8801.T': '三井不',
'8802.T': '菱地所',
'8804.T': '東建物',
'8830.T': '住友不',
#鉄道・バス
'9001.T': '東武',
'9005.T': '東急',
'9007.T': '小田急',
'9008.T': '京王',
'9009.T': '京成',
'9020.T': 'JR東日本',
'9021.T': 'JR西日本',
'9022.T': 'JR東海',
#陸運
'9064.T': 'ヤマトHD',
'9147.T': 'NXHD',
#海運
'9101.T': '郵船',
'9104.T': '商船三井',
'9107.T': '川崎汽',
#空運
'9201.T': 'JAL',
'9202.T': 'ANAHD',
#倉庫
'9301.T': '三菱倉',
#電力
'9501.T': '東電HD',
'9502.T': '中部電',
'9503.T': '関西電',
#ガス
'9531.T': '東ガス',
'9532.T': '大ガス'
}
#=======================================yfinanceのダウンロード部
# ダウンロードしたい株式のティッカーシンボル
keys = my_dict.keys()
ticker = list(keys)
# データをダウンロード
def download_fdata():
yfdata = yf.download(ticker, start='2016-01-01', end='2023-01-01', interval = "1wk")['Adj Close']
print('2016-01-01','to', '2023-01-01')
return(yfdata)
# 関数呼び出し
yfdata = download_fdata()
# 株価データのClose列を辞書で置換
yfdata.rename(columns=my_dict, inplace=True)
data = pd.DataFrame(yfdata)
#=======================================Func, Class
class N225_dataclass():
class_data = 0
class_nomdata = 0
ticker_name = ''
def __init__(self):
self.ticker = ['']
self.fst_price = []
self.end_price = []
self.growth = []
self.var_n = []
self.growth_var = []
def set(self, data):
self.class_data = data
def ticker(self):
self.ticker_name = self.class_data.columns
return(self.ticker_name)
def fist_value(self, n):
return (self.class_data.iat[0, n])
def end_value(self, n):
return (self.class_data.iat[-1, n])
def growth_all(self):
for i in range(len(self.class_data.columns)):
self.ticker.append(1)
self.fst_price.append(1)
self.end_price.append(1)
self.growth.append(1)
self.var_n.append(1)
self.growth_var.append(1)
self.ticker[i] = self.class_data.columns[i]
self.fst_price[i] = self.class_data.iat[0, i]
self.end_price[i] = self.class_data.iat[-1, i]
self.growth[i] = self.end_price[i] / self.fst_price[i]
self.class_nomdata = self.class_data / self.fst_price
for i in range(len(self.class_nomdata.columns)):
self.var_n[i] = self.class_nomdata.iloc[:, i].var()
self.growth_var = [self.growth, self.var_n]
tiker_growth_dict = dict(zip(self.ticker, self.growth))
tiker_var_dict = dict(zip(self.ticker, self.var_n))
return (tiker_growth_dict, tiker_var_dict)
def PF3_vale(self, pf1, pf2, pf3):
pf_value = (self.growth[pf1] + self.growth[pf2] + self.growth[pf3]) / 3.0
return (pf_value)
def add_PF(self, pf1, pf2, pf3):
# 列を追加
PF_name = '[' + self.class_data.columns[pf1] + ':' + self.class_data.columns[pf2] + ':' + self.class_data.columns[pf3] + ']'
self.class_data[PF_name] = (self.class_data[self.class_data.columns[pf1]] + \
self.class_data[self.class_data.columns[pf2]] + \
self.class_data[self.class_data.columns[pf3]] ) / 3.0
def del_PF(self):
# 列を削除
rightmost_column = self.class_data.columns[-1]
self.class_data = self.class_data.drop(rightmost_column, axis=1)
def PF3s_meanvar(self, pf1, pf2, pf3):
self.add_PF(pf1, pf2, pf3)
# 分散とGrowthを計算
self.fst_price = self.class_data.iat[0, -1]
self.end_price = self.class_data.iat[-1, -1]
last_column = self.class_data.iloc[:, -1]
last_column = last_column / self.end_price
growth_add_pf = self.end_price / self.fst_price
var_n_add_pf = last_column.var()
self.growth.append(growth_add_pf)
self.var_n.append(var_n_add_pf)
PF_name = '[' + self.class_data.columns[pf1] + ':' + self.class_data.columns[pf2] + ':' + self.class_data.columns[pf3] + ']'
# 列を削除
self.del_PF()
return [self.growth[-1], self.var_n[-1]]
def var_all(self):
var_n = self.class_nomdata.var()
return (var_n)
def dataout(self):
return(self.class_data)
#=======================================Main
# クラス生成
class1 = N225_dataclass()
# dataロード
class1.set(data)
# Growth, var
growth, var = class1.growth_all()
# 3PF銘柄の場合
# pf_samplenum数の組み合わせの分散-Growthを計算
pf_samplenum = 3000
print('pf_samplenum=',pf_samplenum)
pf_return = []
varnum = []
tiker_num = data.shape[1]
for i in range(pf_samplenum):
numbers = random.sample(range(0, tiker_num), 3)
m1 = numbers[0]
m2 = numbers[1]
m3 = numbers[2]
col_name1 = data.columns[m1]
col_name2 = data.columns[m2]
col_name3 = data.columns[m3]
pfreturn, pfvar = class1.PF3s_meanvar(m1, m2, m3)
pf_return.append(pfreturn)
varnum.append(pfvar)
# 自分が選択したPFの場合
# 特定のキーのインデックスを取得
keys_list = list(my_dict.keys())
index1 = keys_list.index(my_pf1)
index2 = keys_list.index(my_pf2)
index3 = keys_list.index(my_pf3)
my_pfreturn, my_pfvar = class1.PF3s_meanvar(index1,index2,index3)
key1_text = list(my_dict.keys())[index1]
key2_text = list(my_dict.keys())[index2]
key3_text = list(my_dict.keys())[index3]
key_value = my_dict[key1_text] + my_dict[key2_text] + my_dict[key3_text]
print(f'My Portfolio: {key_value}')
#=======================================Plot
# XXXX通りのポートフォリオの分散とリターンのプロット
# XYプロットを作成
x = np.array(varnum)
y = np.array(pf_return)
plt.title('Var-Growth')
plt.xlabel('Var')
plt.ylabel('Growth')
plt.grid(True)
plt.xlim(-0.05, 0.20)
plt.ylim(0, 5)
plt.scatter(x,y,s=5)
# 別データの単一の赤点を追加
x_red = my_pfvar # x座標
y_red = my_pfreturn # y座標
plt.scatter(x_red, y_red, color='red', s=25, label='My Portfolio')
# 赤点の隣にGrowth値を表示
plt.text(x_red + 0.01, y_red, f'Growth={y_red:.2f}', color='red', fontsize=12)
plt.show()
最初の
#=== ここに自分のポートフォリオに選ぶ銘柄を入力する ===#
# (日経225銘柄のみ対応)
my_pf1 = '7267.T'
my_pf2 = '7011.T'
my_pf3 = '8001.T'ここで選択する銘柄を指定してください。
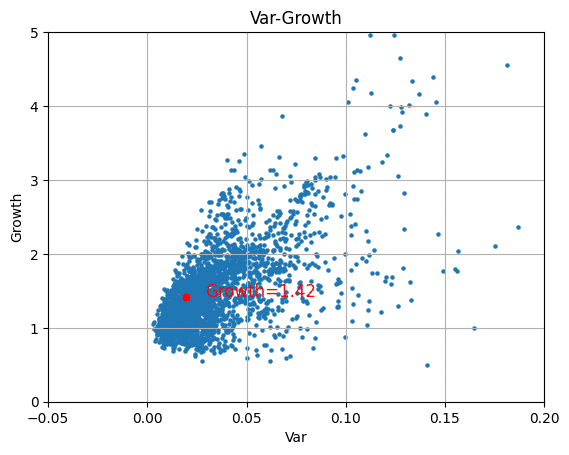
出力結果は3銘柄 33%ずつ購入した時のリターンと分散です。
左上に位置すれば好ましいポートフォリです。
結果は
縦軸がGrowth(収益)、横軸が分散
グラフのみは
青点が日経225銘柄をランダムに組み合わせた3000組み合わせのリターンと分散で
赤点が自分が選択したポートフォリオのそれです。
比較してください。
上に行くほどリターンが高く、下に行くほどリターンは小さい。右に行くほど分散が大きく、危険なポートフォリオという事です。左に行くほど分散が小さくなる。
「左上が好ましい位置です。」
[*********************100%%**********************] 225 of 225 completed
2016-01-01 to 2023-01-01 My Portfolio: ホンダ三菱重伊藤忠
ふむふむ
所感
Google Colabはほぼすべてのライブラリがインストール作業なしに使えるので便利ですよね。