
【ComfyUI】Stable Diffusion3 Mediumをローカル環境で動かす方法

👋こんにちは!AI-Bridge Labのこばです!
Stability AIからリリースされた最新の画像生成AI『Stable Diffusion3』のオープンソース版 Stable Diffusion3 Medium。早速試してみました!
こんな高性能な画像生成AIを無料で使えるなんて…ありがたい限りです🙏
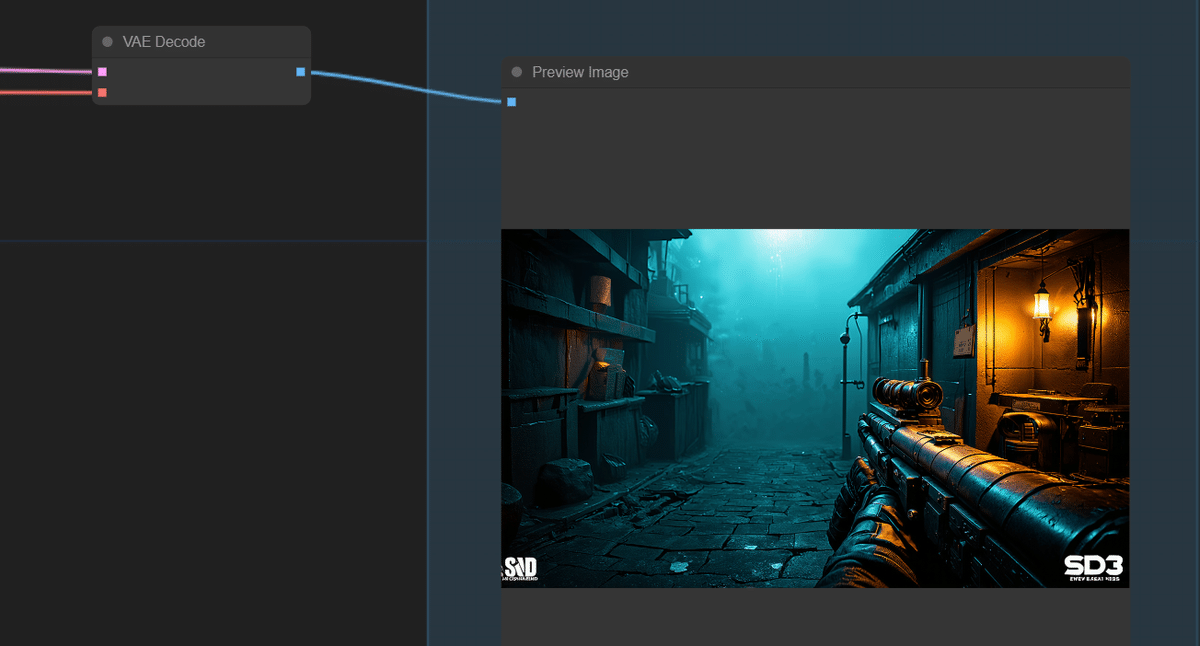
今回はWindows版のローカル環境(ComfyUI)で実装してみましたので、本記事ではSD3で画像生成するまでの手順をできるだけシンプルにご紹介します!
最新の画像生成AIの網羅的な情報はこちら
Stable Diffusion3 Mediumに関する公式の発表はこちら
1.SD3 Mediumで生成した画像例
ゲーム風、実写風、アニメ風…幅広く対応できます。また、プロンプトの効きもかなり強いので色々と試行錯誤の甲斐がありそうです。
ベースモデルでこれだけ高い性能があれば、ファインチューニングモデルはクオリティ面でもMidjourneyに並ぶかそれ以上のモデルになりそうですね。



その他、過去記事でSD3のAPIを使って作成した画像はこちらからご覧いただけます。
2.SD3 Mediumのモデル一式をダウンロード
以下のHugging Faceのページにアクセスし、ログインおよび必要事項に署名するとファイルがダウンロードができるようになります。
ここから必要なアセットをダウンロードしておきます。
・stable-diffusion-3-mediumからモデルをDL
以下からいずれかをダウンロードしておきます。
sd3_medium.safetensors
MMDiT および VAEモデルが含まれますが、テキスト エンコーダーは含まれません。sd3_medium_incl_clips_t5xxlfp16.safetensors
T5XXL テキスト エンコーダーの fp16 バージョンを含む、必要なすべての重みが含まれています。動作環境に余裕があればこちらを利用します。sd3_medium_incl_clips_t5xxlfp8.safetensorsT5XXL
テキスト エンコーダーの fp8 バージョンを含む、必要なすべての重みが含まれており、品質とリソース要件のバランスが取れています。fp16よりも軽量です。
・stable-diffusion-3-medium/comfy_example_workflowsからワークフローのサンプルjsonをDL
sd3_medium_example_workflow_basic.json
・stable-diffusion-3-medium/text_encodersからテキストエンコーダーをDL
t5xxl_fp8_e4m3fn.safetensors
clip_g.safetensors
clip_l.safetensors
3.ComfyUIの実装
3-1.Gitのダウンロードおよびインストール
もしGitが入っていなければ準備として、以下のページからGitをダウンロードして、インストールを行ってください。
3-2.ComfyUIのダウンロード
以下のリリース ページには、Nvidia GPU で実行したり、CPU でのみ実行したりできる Windows 用のポータブル スタンドアロン ビルドがあります。
ダウンロードリンクからComfyUIのパッケージをダウンロードしてください


3-3.モデル等の格納
ダウンロードしたファイルを7-Zipで解凍します。
解凍後に「new_ComfyUI_windows_portable_nvidia_cu121_or_cpu」フォルダを開きます。
モデルファイルをアップ
\ComfyUI_windows_portable\ComfyUI\models\checkpoints
に先ほどSD3 MediumのリポジトリからダウンロードしたSD3のモデルファイルを投入します。

※sd3_medium.safetensorsなどテキストエンコーダーが必要なモデルの場合
\ComfyUI_windows_portable\ComfyUI\models\clip
先ほどSD3 Mediumのリポジトリからダウンロードしたテキストエンコーダーを投入します。
clip_g.safetensors
clip_l.safetensors
t5xxl_fp16.safetensors または t5xxl_fp8_e4m3fn.safetensors
3-4.ComfyUI Managerを導入
Stable Diffusion3用のノードを適用するため、ComfyUI Managerを実装しておきます。以下の場所からコマンドプロンプトを開き、git cloneでComfy-UI-Managerを格納します。
▼コマンドを実行するディレクトリ
\ComfyUI_windows_portable\ComfyUI\custom_nodes
▼コマンド
git clone https://github.com/ltdrdata/ComfyUI-Manager.git3-5.ComfyUIの起動
\ComfyUI_windows_portableにある、「run_nvidia_gpu」のバッチファイルをダブルクリックして実行するとコマンドプロンプトが立ち上がります。しばらく待つとComfyUIが起動します。

起動すると、自動的にブラウザが立ち上がりますが、遷移しない場合はこちらのURLからアクセスしてください。
http://127.0.0.1:8188

3-6.SD3用のワークフローをロード
この項目からLoadを選択し、SD3のリポジトリからダウンロードしたsd3_medium_example_workflow_basic.jsonを読み込みます。
この手順を行うことで、SD3用の基本的なワークフローが自動的に組まれます。
すると、「ワークフローに足りないノードがあります」というメッセージが出ると思いますので、右下のManagerをクリックします。(手順3-4.でComfyUI Managerを入れておけばこの表示がでてきます)
ComfyUI Managerのメニューが開いたら、Update Allをクリックします。

すると、SD3用のワークフローが正常な状態で立ち上がるはずです。
ここまでで準備が完了です。

4.画像の生成
左上のLoad Checkpointから、SD3のリポジトリからダウンロードしてきたモデルファイルを選択します。
テキストエンコーダーが不要なモデルの場合はTripleCLIPLoaderのノードを削除します。

Queue Promptボタンを押して画像を生成。
初回はモデル読み込みなどが入り時間がかかると思いますが、正常にプロセスが実行されれば、画像が生成されるはずです。


5.まとめ
以上が、Windows版のComfyUIへStable Diffusion3 Mediumを実装する方法でした。このタイミングでComfyUIに乗り換える方も多いと思いますので、参考になれば幸いです。
もし手順でご不明な点があればコメントなどでお知らせください。
Stable Diffusion3 Mediumはまだリリースされたばかりですので、今後ファインチューニングモデルや専用の拡張機能などの登場が楽しみですね!
6.AIBridge Labについて
私たちAIBridge Labでは、企業や個人のAI活用を支援し、企業のDX実現をサポートしています。AIを活用したソリューションにご興味があればお気軽にメールやXのDMでご連絡ください!
ai_business@doerstokyo.jp
最後まで読んで頂きありがとうございました!
気に入って頂けましたら「スキ」や「フォロー」をしていただけると幸いです! 😄
Xアカウントのフォローもぜひお願いします!
Stable Diffusion3 ComfyUIで早速動かしてみました!
— こば@AIBridge Lab (@doerstokyo342) June 12, 2024
とにかく表現の幅が広いので、いろいろ試してみる価値がありそうです!
プロンプトは、長めにできるだけ詳細に書いた方がうまくいくケースが多かったです#AIart #Stablediffusion3 pic.twitter.com/Hc5BU7nZE5
皆さまの温かいサポートのおかげで、活動を続けることができています。もしよろしければ、引き続き支援をお願いできますと幸いです。より質の高い記事投稿に励みます!