
国会会議録 マトリックス表示用の変数選定

この画像のように、ある変数を2つ選ぶか作成し、主に国会議員をマトリックス表示したい。
マトリックス描画で大事なこと
1.二つの変数が独立している(マトリックスにしたい)
2.良い感じに分布している
3.変数の意味がわかる(直感的に理解したい)

以下が変数の候補。
1.依存関係タグ(dep)
2.品詞タグ(pos)
3.Entity Type(ent_type)
4.依存関係の長さ、深さ(token_index, head_index)
5.情報量(エントロピー)、TTR(語彙)、CLI(読みやすさ)などの、品詞や依存関係ではない別のアプローチ
四分位数や標準偏差、変動係数、正規分布しているかを個別に確認してみたが、らちが明かないのでやめた。
使用するデータについて
2024年の取得済みのものすべて使う。発言者数は約950人。
合計発言文字数、平均発言文字数の少ない人のデータを除外する。
grouped_data_above = grouped_data.loc[(grouped_data['charPerCnt'] > 100)
& (grouped_data['total'] > 200)].reset_index(drop = True)]PCAと散布図の観察
良い感じに散らばっている変数群を採用する。今回は、エンティティタイプ、品詞タグ、依存関係タグの3種だけ試した。品詞タグと依存関係タグを組み合わせるともっといい変数を作れる気がする。



採用
負荷量から主成分を疑似的に作成する
主成分分析の散布図、負荷量を観察して行う。正の負荷量の変数を足し、負の負荷量の変数を引いて疑似的に主成分を作成してみる。

正 : 'NOUN', 'NUM', 'ADP', 'SYM'
負 : 'ADV', 'PART', 'PRON', 'SCONJ', 'PUNCT', 'AUX', 'INTJ', 'DET'
grouped_['pc1_'] = grouped_[['NOUN', 'NUM', 'ADP', 'SYM']].sum(axis = 1) - grouped_[['ADV', 'PART', 'PRON', 'SCONJ', 'PUNCT', 'AUX', 'INTJ', 'DET']].sum(axis = 1)散布図描画

縮尺を調整済み
良く散らばっていると思う
委員会別散布図
一度に描画すると顔写真が渋滞するので、委員会別、政党別で表示する。
横軸は情報量で、値が大きいほど、発言の情報量が多いとされる。縦軸は疑似的に生成した主成分で、何を意味しているかは不明。


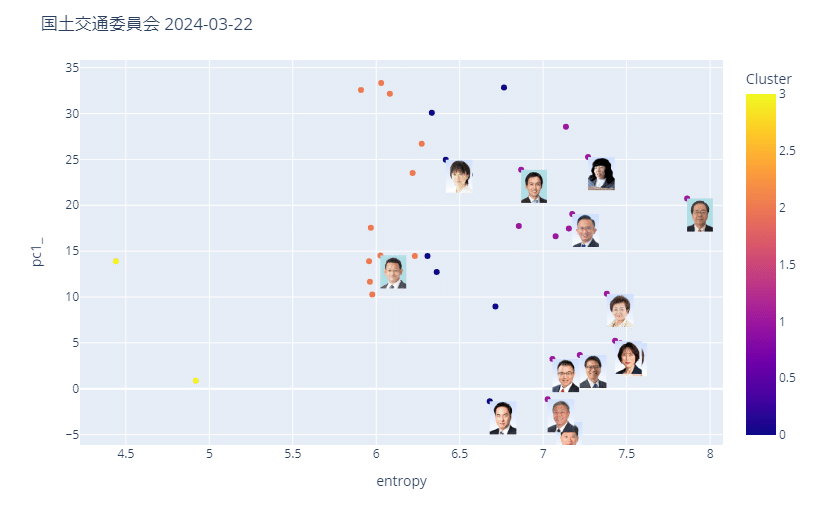



おわり
1.一部の悪さをしている変数を除外すれば依存関係タグも良い分布になる気がする。品詞タグとの組み合わせも試したい。
2.pc1の意味が説明可能なものかどうか。形態素解析の専門的な知識や研究の参照が必要だと思うので、ぼちぼちやっていきたい。
3.顔写真重なるのどうにかする
4.エントロピーはテキスト長に比例しないらしいが、以前試した時比例していたようにみえた。トークン数と比較して確認する
この記事が気に入ったらサポートをしてみませんか?