
ControlNet-V1.1検証 第一話 -僕ら、シャッフルシャッフルボーイズ-

こんにちは。
最近は暖かい日が続いており春の訪れを体感していましたが、ControlNet-v1.1の訪れと同時にまた寒くなってきましたね。
どうやらGW(ゴールデンウィークの意。)も天気が悪いらしいので、BG(ビアガーデンの意。)にいく予定がある私は少しZK(残念な気持ちの意。)になっている今日この頃です。
さて、今回はControlNet-v1.1のshuffle機能を掘り下げていきたいと思います。
とはいえ、さっぱり機能を理解していないので、まずそこから始めようと思います。
雑に以下の画像を投げてみます。
この画像自体はTwitterアイコン用に12月頃つくった768×768pxの没絵です。

確かDefmix-v1.0の前身のモデルで作ったものだったような気がします。
今見ると絵柄がかえって良いなと思ったので、この子を採用したいと思います。
早速、Imageに入れてみると、Preprocessor Previewではこのように。

どうやら投げた画像をぐにゃぐにゃにして、Inputするようです。
…なんで?
モラハラ気質の厚切りジェ〇ソン?
「…何で?漢字でそんなことしろって言ってないじゃん。」
とにかく、どうやら"ぐにゃ絵"を取り込むことで色々できる機能のようです。
それにしても、機能が多いんですよね。
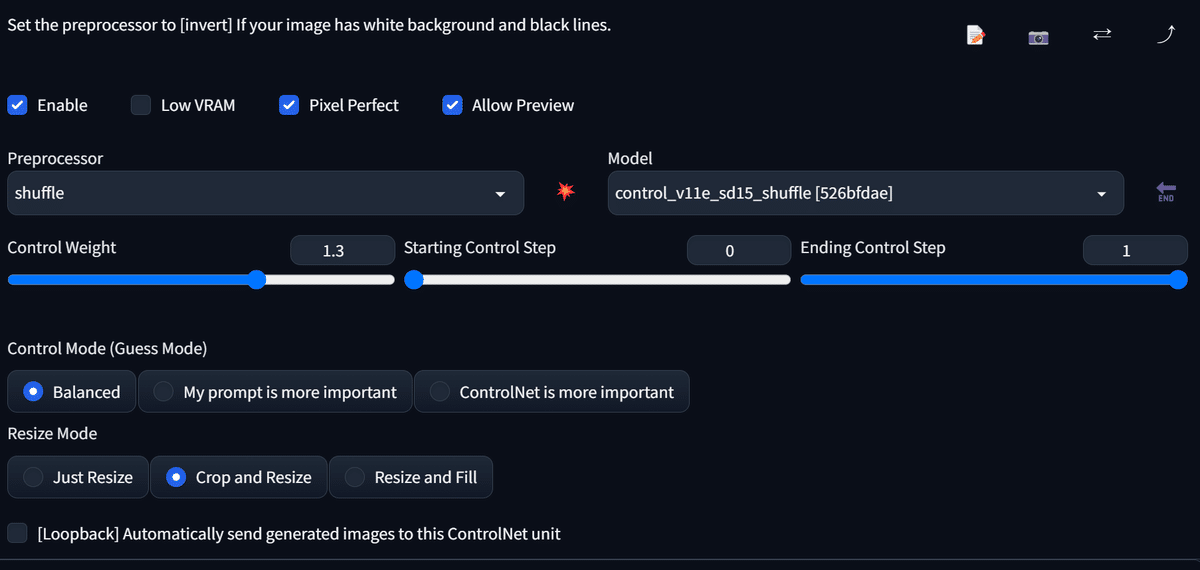
順に追っていきたいと思います。
Control Weightについて
そもそも、v1.0のときからあまりControlNetを使っていなかった私はこの"Control Weight"というパラメータがどの程度出力に影響するかを体感出来ていません。
まずは、デフォルトのControl Weight=1.0からやってみます。
Control ModeはBalancedを使用します。
Preprocessor resolutionはよく分からないので、出力画像と同じ1024pxにしてみます。
また、ModelはDefAnimeMix-v1.0-beta[97a18666fc]を使います。(公表してないやつ…)
Promptは以下の通りです。
PP: (cute girl:1.3)
NP: (EasyNegative:1.3)
Control Weight=1.0だと髪色や服の色など全体の色彩感とコンセプトをある程度引き継ぐことができていると思います。
ただ、絵柄(というよりモデルの特徴)はControlNetに使用している画像ではなく採用しているモデルの影響を受けていると思います。
次は、Control Weightを1.0から下げていこうと思います。


感じるのは、「あるラインを超えると大きく構図も変化するが、そのラインまでは少しの差異しかない。」みたいなことです。
例えば、今回のControl Weight=0.6と0.3の差で大きなものは右下の画像の髪色くらいかなと感じます。
一方で、Control Weight=1.0と0.6ではかなり大きく変化していると思います。
なんで?
本格インドカレー屋に行き慣れてる友人?
「ナンで」
ともかく、当たり前のことですが「元の画像から何を引き継ぎたいか」によってWeightは調整するべきで、引き継ぎたい部分をある程度制御することができるというわけですね。
我々は内部処理を理解する前に、「どうすればどうなるか」を実験的に知ることの方が優先度は高いので、ここは宿題ということにしましょう。
次はControl Weight=1.0以上の値にしてみましょう。



やはり、Control Weight=1.3~1.6の間に大きな変換点がある気がします。
実際にどのあたりで大きな変化が起こるかを探ってみたところ、Control Weight=1.4くらいにあるような気がします。

まとめると、Control Weightで出力結果をおおまかに3パターンくらいのブロックに分けることができるようです。
ただ、時間の都合上サンプルサイズが1なので、もしかすると他の条件ではもっと多様な変化を見せてくれる可能性はあります。
この記事では、髪色などは引き継ぎつつも、構図は安定しているControl Weight=1.3で検証を進めたいと思います。
Preprocessor Resolutionについて
これなんぞ?
とりあえず512×512 pxにしてみてNoiseの様子を見てみます。

出力画像の解像度は1024×1024 pxなので、Noiseが4分割されてそうなところをみると文字通り「Shuffleする画像の解像度」という意味っぽいです。(間違っているかも。)
しかし、読み込むたびにNoiseが変わる仕様のようで、どの解像度にするのがよいのか悩んでいたところ…
あるではないですか。"Pixel Perfect"の文字が。
パーフェクト。パーフェクトな文字が。
どうやら自動で解像度を合わせてくれるらしいです。
難しいことを考えなくて済みました!!やったね!!気づく前の俺の30分返してね!!
ちなみにSeed値ごとにNoise mapが変わるわけではなさそうなので、だいぶ処理の最初の方に差し込んでいるのでしょうか?
Github読めという話ですが、宿題にしましょう。宿題。宿題。
Control Mode (Guess Mode)について
雰囲気は分かりますが、どの程度変わるのか見てみましょう。
ついでに画像のSeed値も気分転換に変えちゃいましょう。
べ、別にSeed値ひかえる前にF5押しちゃったとかじゃないんだから!!(1敗)
ちなみに元の画像はこちら。

そして、Control Modeを"Balanced"と"ControlNet is more important"の2つを同Seedで比較してみたいと思います。


やはり後者の方がより、元の画像のような特徴を引き継いでいますね。
今回の画像からこのShuffleが得意なことと不得意なことも分かってきた気がします。
髪色や服装はかなりの精度で再現可能。(っぽい)
目の色は全体の色味を引き継いでそう。
背景の特徴も高Weightだと再現できそう。(一方で上げすぎると、全体の色味が背景にも影響することで再現度が落ちてそう。)
構図は再現不可。(canny, depthやopenposeに任せよう。)
絵柄はWeight次第かも。
こんなところでしょうか。初めの足掛かりとしては十分な気がします。
実用的な使い方の検討
やはり、一番に思ったのは「絵柄の再現性」と「服装の再現性」に強みがあるなと感じました。
前者に関しては、ある程度特徴が固定化した画像を用意し、苦手な部分だけプロンプトで補ってやれば「疑似LoRA」のようなことが可能です。
ストレージの圧縮と考えればかなり価値があるでしょう。
後者については、プロンプトで表現しにくかった服装を再現しやすくなったのが大きいです。
こちらは「LoRAほどの厳密さは求めないけれど、こういう服装を量産したい!」みたいな需要に応えられそうです。
例えば、以下のような画像があります。

「白衣」と指定してもある程度再現できそうですが、早速試しにshuffle機能で何枚か画像を生成してみました。



結構雑に服装の再現もできそうで満足です。
最後に
まだまだ気づいていないことがたくさんあると思うので、今後も新たな発見が楽しみですが、次回は別のPreprocessorについて記事にしたいと思います。
どうしてあのような"ぐにゃ絵"から特徴を抽出できるのかはちっとも分かりませんが、「分からなくても良いことはある」ということでしょう。
ちなみに「分かる人だけ分かればいいと思っている監督が作っている理解困難なむずかしー--い映像作品のサムネ」みたいなものも作れます。

他にも、ノイズをわざと走らせて「電脳空間」たるものを髣髴とさせてみたり。

少なくともアスペクト比は出力したい画像と合わせた方が良さそうだと思います。
それでは、この記事はこのあたりで終わりにします。
DM(では、またの意。)
この記事が気に入ったらサポートをしてみませんか?