
【R-18注意】AIイラスト生成手順紹介【呪文あり】

まっしろ(DeepWhite)です!
タイトル通りですが、Twitterに投稿したこのイラストの生成手順を公開いたします。
プロンプト、モデル構成、WEB UIの設定、ControlNet向けのLineartも公開しています。
自己責任の範囲で自由に使ってもらって大丈夫です!
18歳以上向けのイラストが使用されるため注意してください。

用意するもの
Stable diffusion WEB UI が使用可能な環境(Google colab Pro、VRAM12GB程度のGPUを搭載したPCなど)
画像編集ソフト(レイヤー分けできるもの、Photoshopなど)
時間と根気
Stable diffusion WEB UI のインストール
初めての記事なのでインストールから書きます。すでにインストール済みの方はとばしてもらって大丈夫です。
これから説明するインストール手順はWindows 11向けになります。Macやcolabの場合は割愛します。
基本的には上のリンクページに記載されている手順で問題ないですが、アップデートする際にPythonのバージョンなどで不具合が起きることがあるので簡単に切り替えができる仮想環境にインストールする手順を説明します。
Anaconda のインストール
はじめに、上記のリンクからAnacondaのインストーラーをダウンロードし、ダブルクリックしてインストールします。
インストール設定はデフォルトで大丈夫だと思いますが、以下の記事を参考にしてください。
その後、スタートメニューのAnaconda Promptを起動し、以下のコマンドを実行します。
conda init powershellAnaconda Promptを閉じ、スタートメニューを右クリックしてターミナル(管理者)を起動し、以下のコマンドを実行します。
Set-ExecutionPolicy RemoteSignedターミナルを閉じ、再度ターミナルを開いて以下のコマンドを実行します。エラーがなければAnacondaの設定は完了です。
conda --version分からなければ以下の記事を参考にしてください。
仮想環境の構築
エクスプローラーを開き、Stable diffusion WEB UIをインストールしたい場所(ローカルディスク直下がおすすめ)で右クリックし「ターミナルで開く」を選択します。
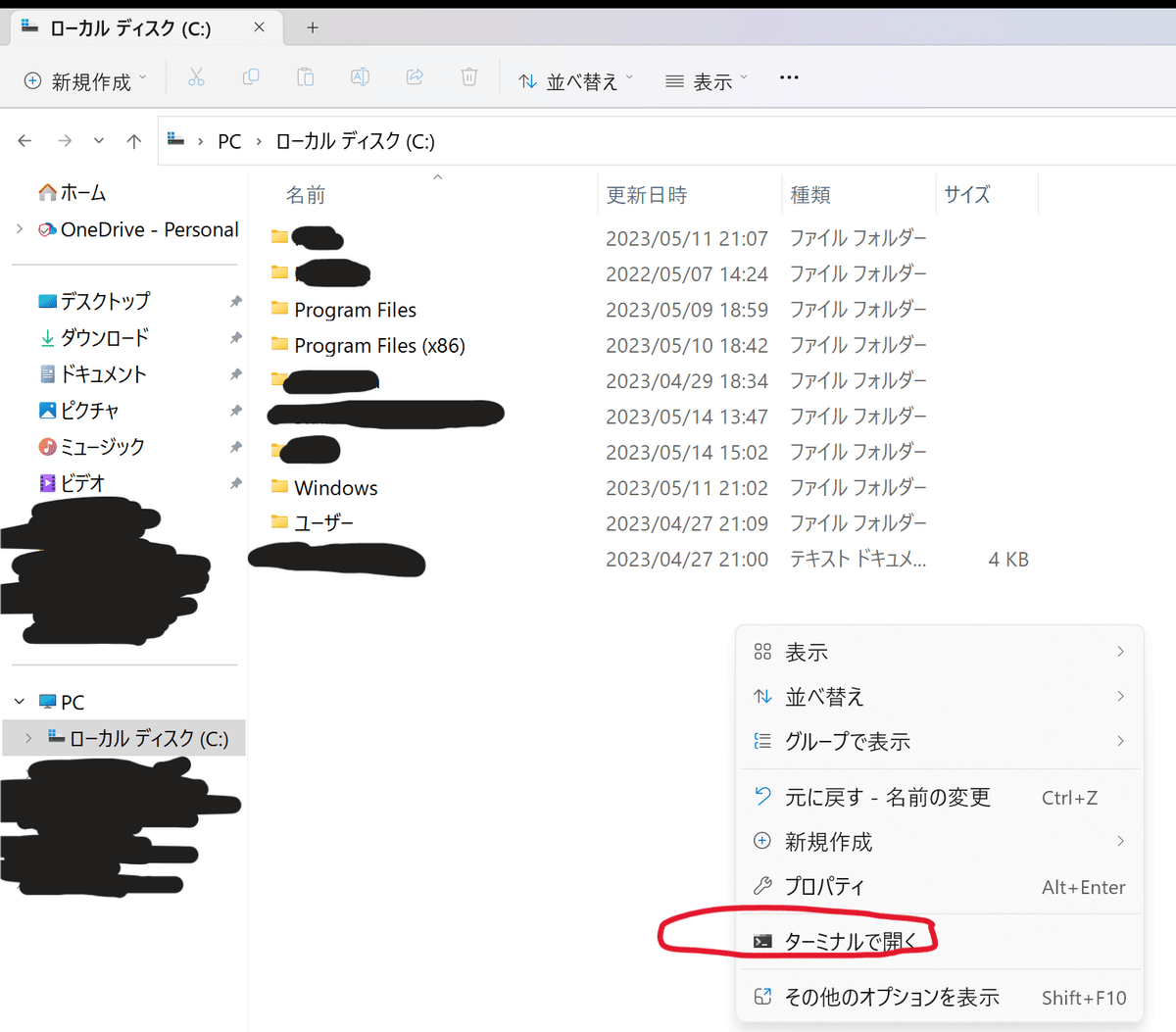
以下のコマンドで環境を構築します。
環境名には覚えやすい好きな名前を、バージョンにはhttps://github.com/AUTOMATIC1111/stable-diffusion-webuiで指定されるバージョンを書きます。
conda create -n 環境名 Python=バージョン執筆時点では以下のようにしました。Stable diffusion WEB UIがアップデートされた場合にはPythonのバージョンが変更されている可能性があるのでリンク先を確認してから実行してください。
(アップデートなどで新しく環境を作りたい場合も同じ手順です)
conda create -n sdwebui Python=3.10.6しばらく待ち、完了したら次のコマンドを実行します。環境名はsdwebuiで統一していますが、自分で設定した名前に置き換えて使用してください。
conda activate sdwebui続いてgitをインストールします。
conda install git完了したらStable diffusion WEB UIのリポジトリを取得します。以下のコマンドを順に実行してください。依存関係のあるデータをすべて取得するのである程度時間がかかります。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
cd stable-diffusion-webui
./webui-user.bat以下のような画面になると思うので、Ctrlキーを押しながらhttp://~と書かれている部分をクリックします。

このような画面がブラウザで開けばOKです。お疲れ様でした。
(ブラウザが直接開かない場合、リンクをコピーしてブラウザの検索タブに張り付けても大丈夫です)

ControlNet の導入
続いて拡張機能であるControlNetを導入します。
Stable diffusion WEB UIの画面右上にあるExtensionsをクリックします。
Install from URLをクリックし、画像のようにURLを入力してInstallをクリックします。
https://github.com/Mikubill/sd-webui-controlnet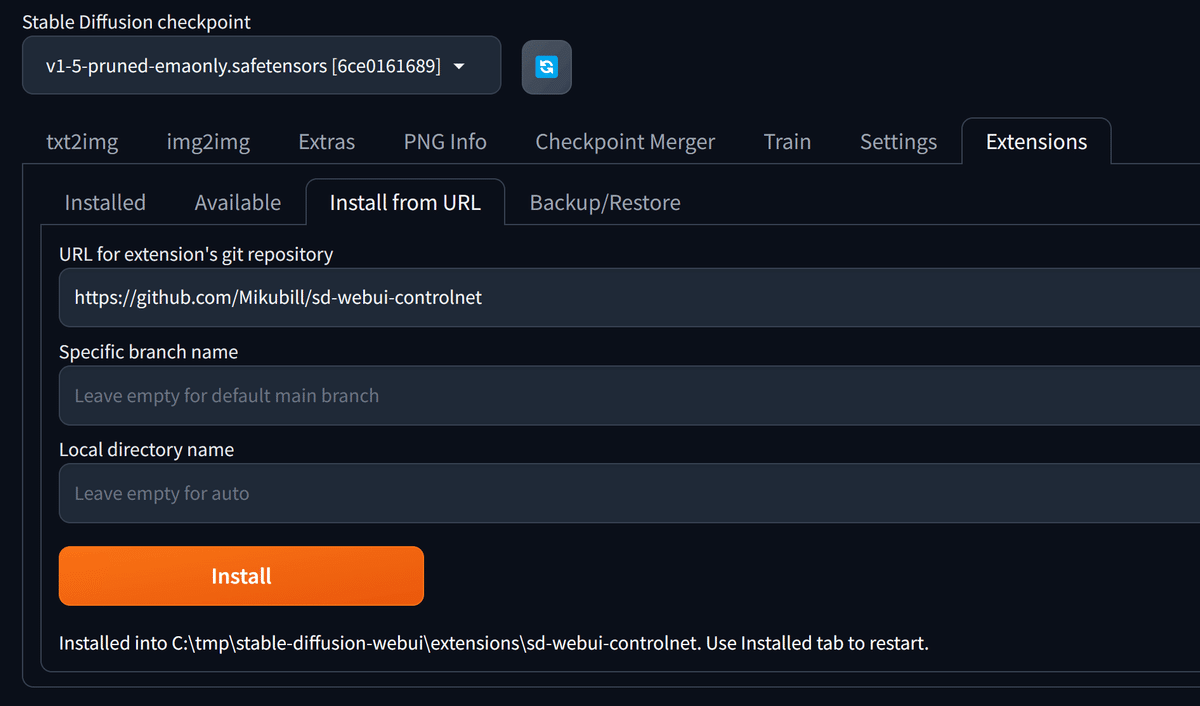
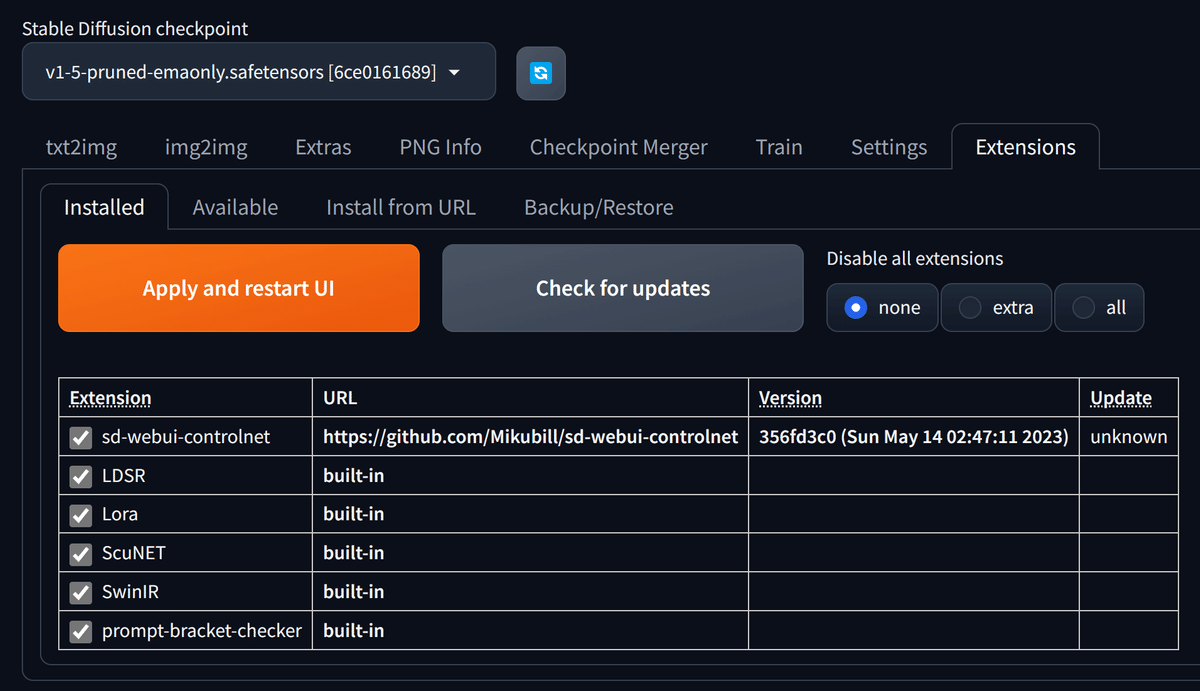
Installedタブに移動し、Apply and restart UIをクリックしてWEB UIを再起動します。
続いて以下のリンクからControlNetで使用するモデルをダウンロードします。
.pth形式のファイルをすべてダウンロードします。
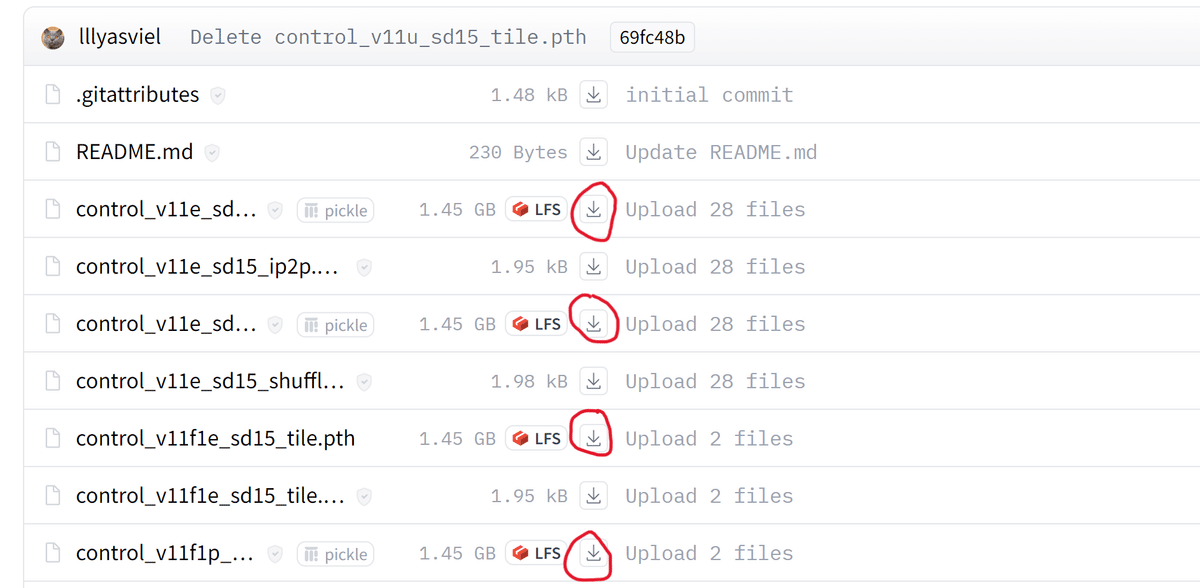
エクスプローラーを開き、ダウンロードしたモデルを以下に配置します。
C:\stable-diffusion-webui\extensions\sd-webui-controlnet\modelsStable diffusion WEB UIを再起動します。一度ブラウザを閉じ、ターミナルも閉じてから、エクスプローラーのC:\stable-diffusion-webuiフォルダで右クリックし「ターミナルで開く」を選択します。
以下のコマンドでStable diffusion WEB UIを起動します。
(以降、起動する場合は同じ手順です)
conda activate sdwebui
./webui-user.bat以下のようにモデルが選択できるようになっていればOKです。お疲れ様でした。

ここから本題
この時点でかなり書いて疲れましたが、ようやくイラスト生成の説明になります。
改めてになりますが、プロンプト、モデル構成、WEB UIの設定、ControlNet向けのLineartを公開しています。
また、生成過程で得られたイラストも一部ダウンロード可能にしてあります。
ぜひ参考にしてみてください。
WEB UI の設定・準備
起動オプション
webui-user.batファイルを編集し、以下のようにします。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --no-half-vae --disable-nan-check
call webui.batExtensions
Install from URLからインストールします。
https://github.com/bbc-mc/sdweb-merge-block-weighted-guiモデルのダウンロード
以下のリンクからモデルとVAEをダウンロードします。
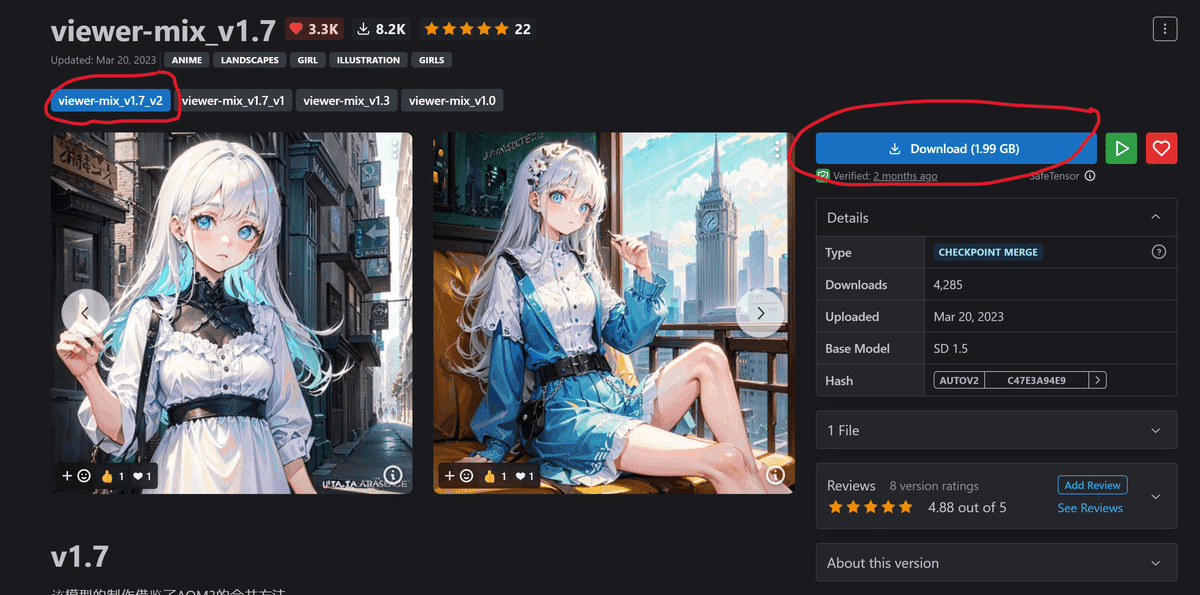
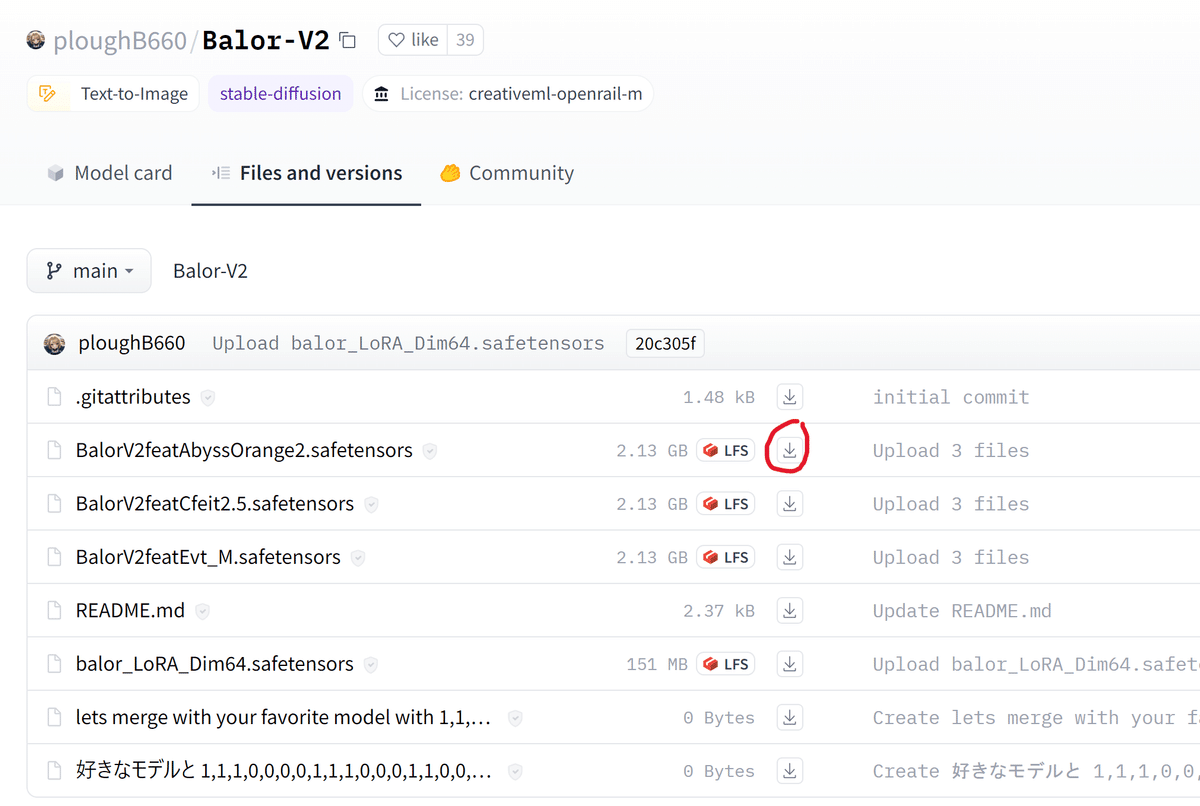

ダウンロードした以下のモデルを下記の場所に配置します。
・BalorV2featAbyssOrange2.safetensors
・viewerMixV17_viewerMixV17V2.safetensors
C:\stable-diffusion-webui\models\Stable-diffusionダウンロードした以下のVAEを下記の場所に配置します。
・vae-ft-mse-840000-ema-pruned.safetensors
C:\stable-diffusion-webui\models\VAEVAEの設定
conda activate sdwebui
./webui-user.bat上記すべてを行った状態でWEB UIを起動します。
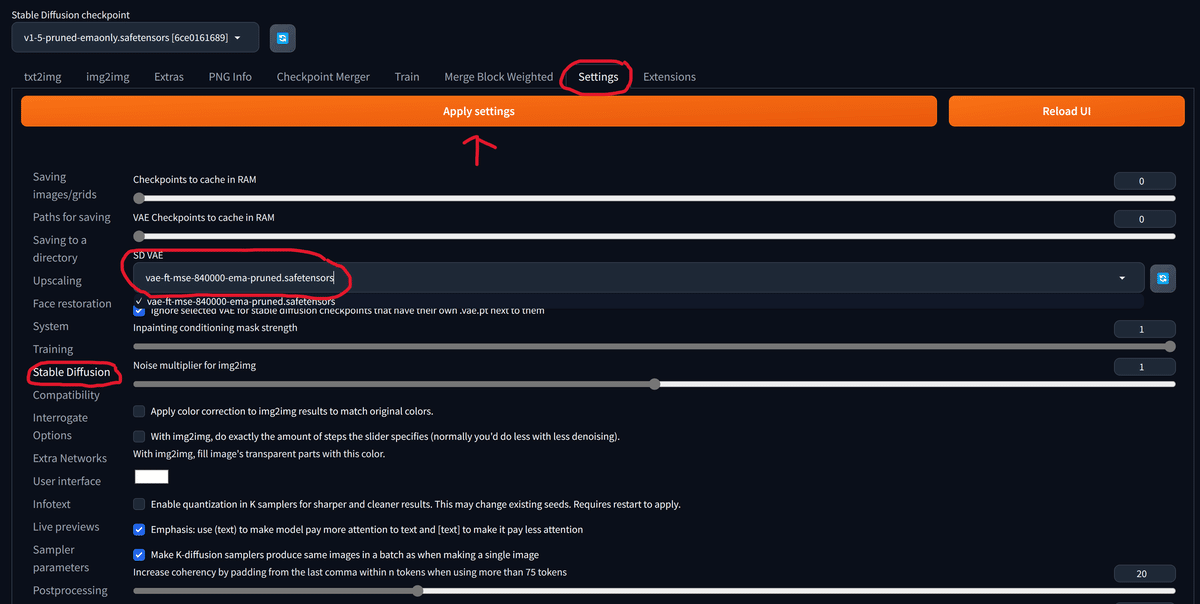
Settingsタブを開き、左の一覧からStable Diffusionを選択します。
画像のようにSD VAEをvae-ft-mse-840000-ema-pruned.safetensorsに変更し、Apply Settingsをクリックします。
モデルのマージ
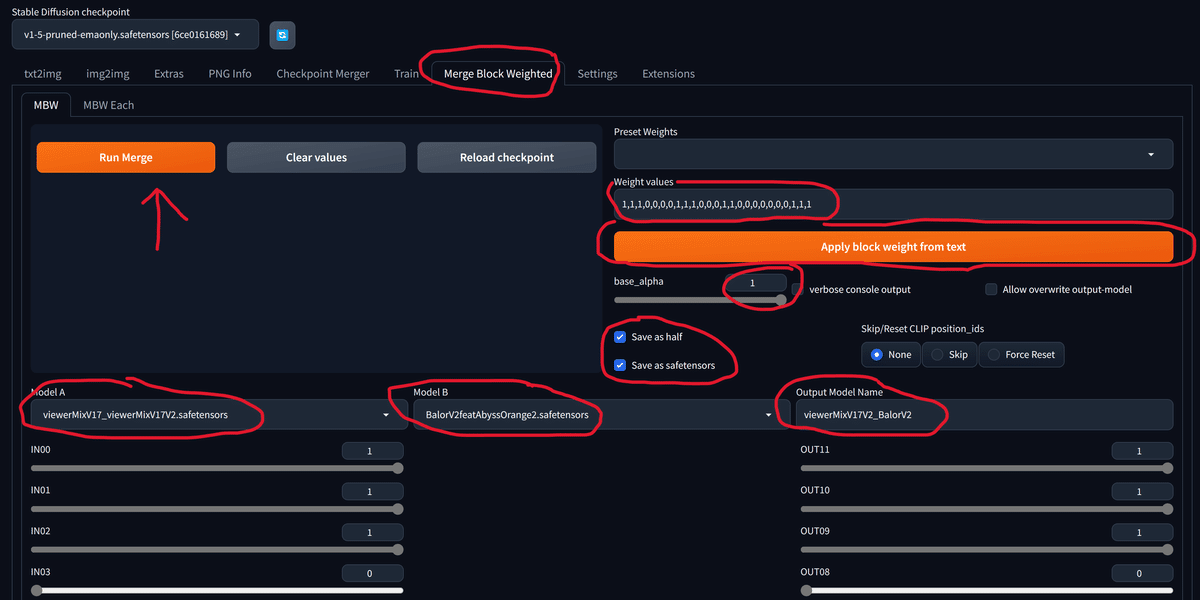
Merge Block Weightedタブをクリックし、画像のような画面にします。
Weight valuesに以下を入力し、Apply block weight from textをクリックします。
1,1,1,0,0,0,0,1,1,1,0,0,0,1,1,0,0,0,0,0,0,0,1,1,1beta_alphaを1に設定し、Save as halfとSave as safetensorsにチェックします。
Model AにviewerMixV17_viewerMixV17V2.safetensors、Model BにBalorV2featAbyssOrange2.safetensorsを選択し、Output Model Namesには好きな名前を入力します。ここでは以下のようにしました。
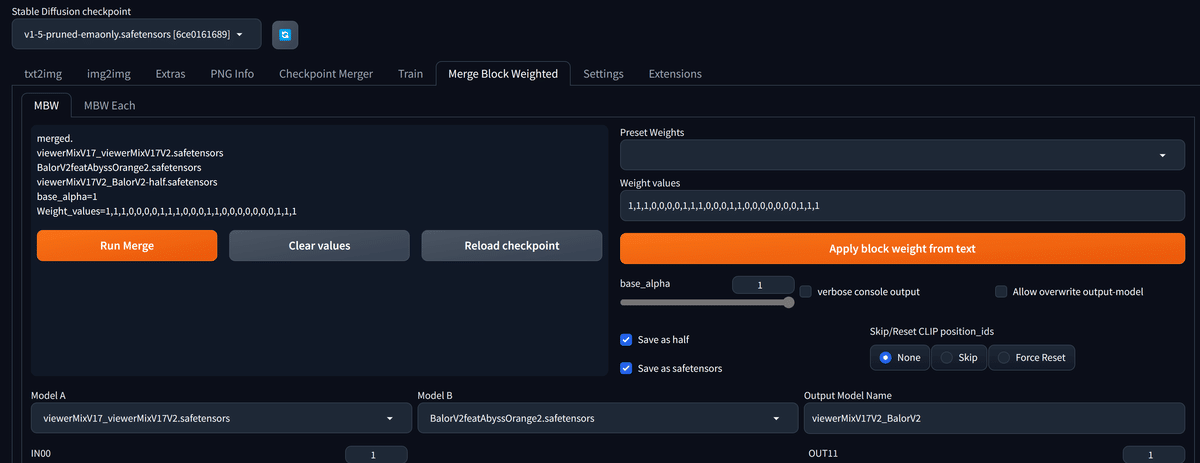
viewerMixV17V2_BalorV2最後にRun Mergeをクリックしてしばらく待ちます。
以下のような画面になればOKです。お疲れ様でした。
イラスト生成手順
イラストを生成する方法としてはプロンプト(いわゆる呪文)のみから生成するtext to imageと、プロンプトと画像から生成するimage to imageの2種類があります。
今回のイラストはこれらの両方を使っていきます。
構図を決める
まず最初に大まかな構図を決めます。
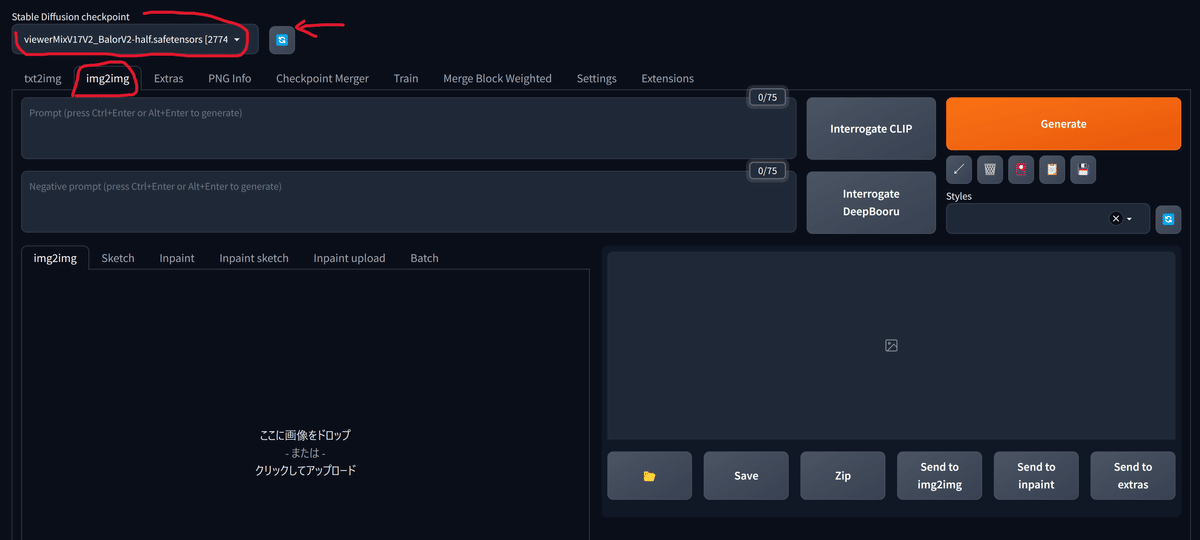
img2imgタブをクリックしてください。
その後、左上のStable Diffusion checkpointに先ほど作成したviewerMixV17V2_BalorV2-half.safetensorsを選択します。
候補に現れない場合は右にある青いマークをクリックして再読み込みします。
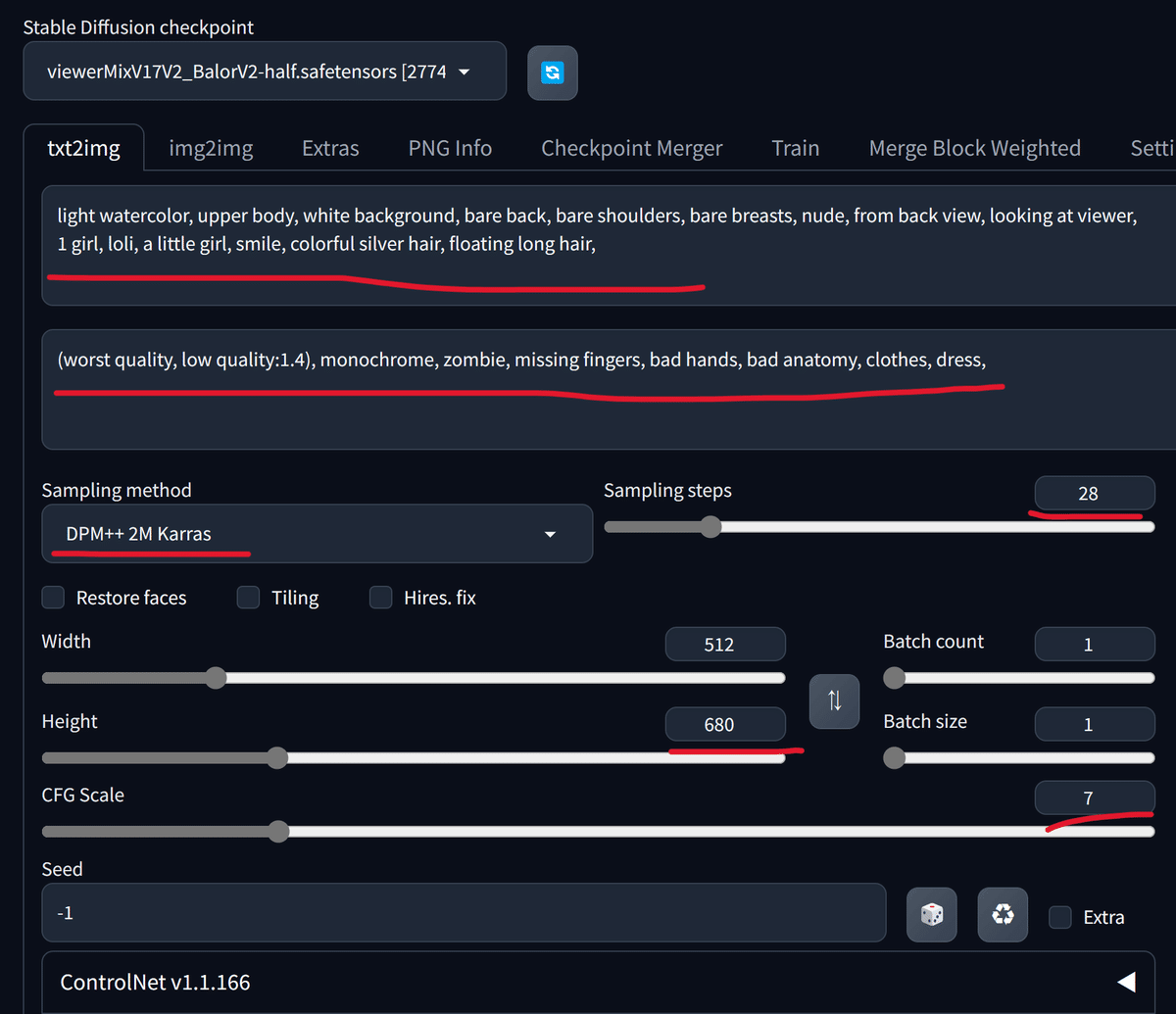
今回使用するプロンプトは以下の通りです。
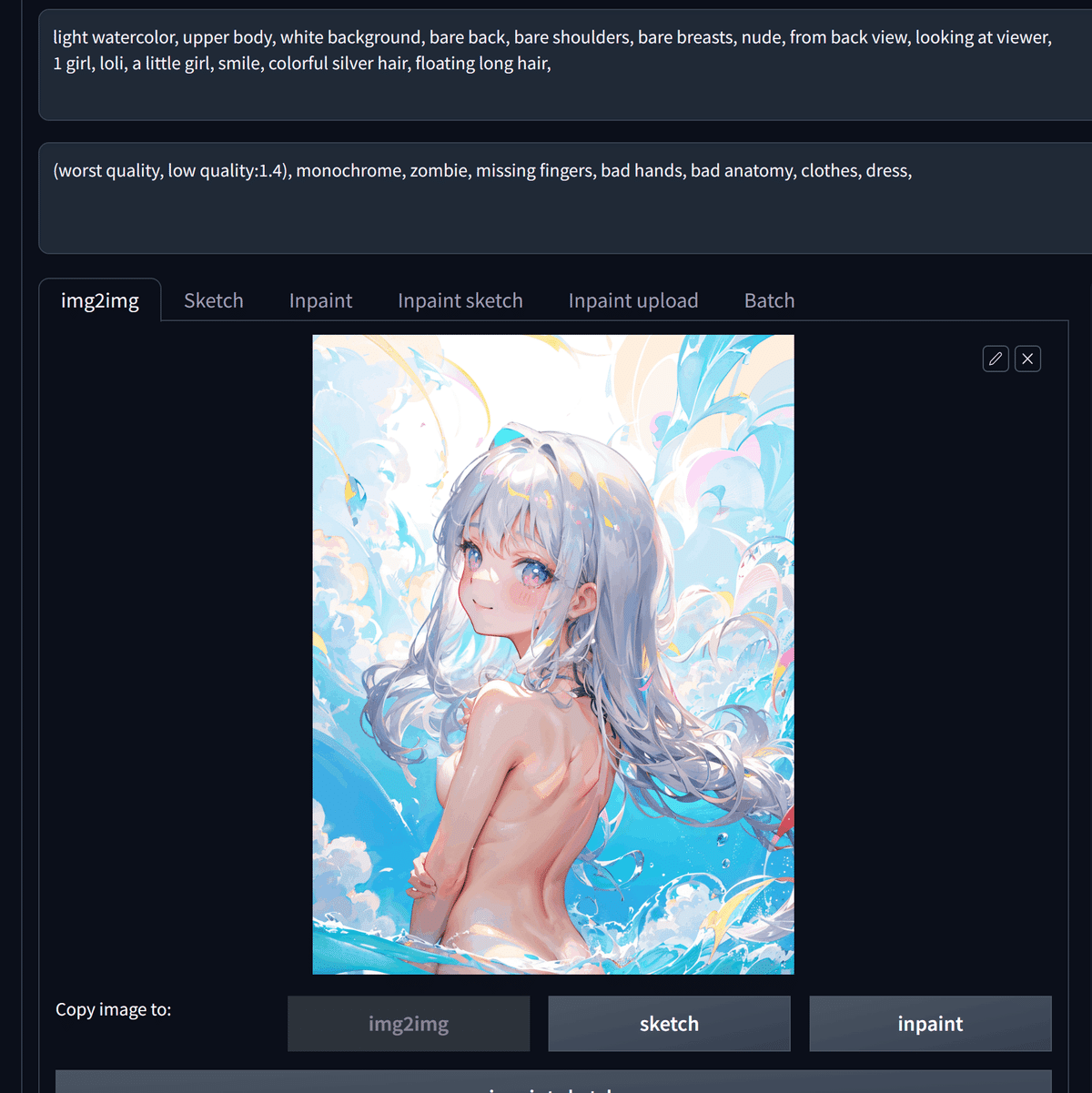
これを画像のように入力します。
light watercolor, upper body, white background, bare back, bare shoulders, bare breasts, nude, from back view, looking at viewer,
1 girl, loli, a little girl, smile, colorful silver hair, floating long hair,(worst quality, low quality:1.4), monochrome, zombie, missing fingers, bad hands, bad anatomy, clothes, dress,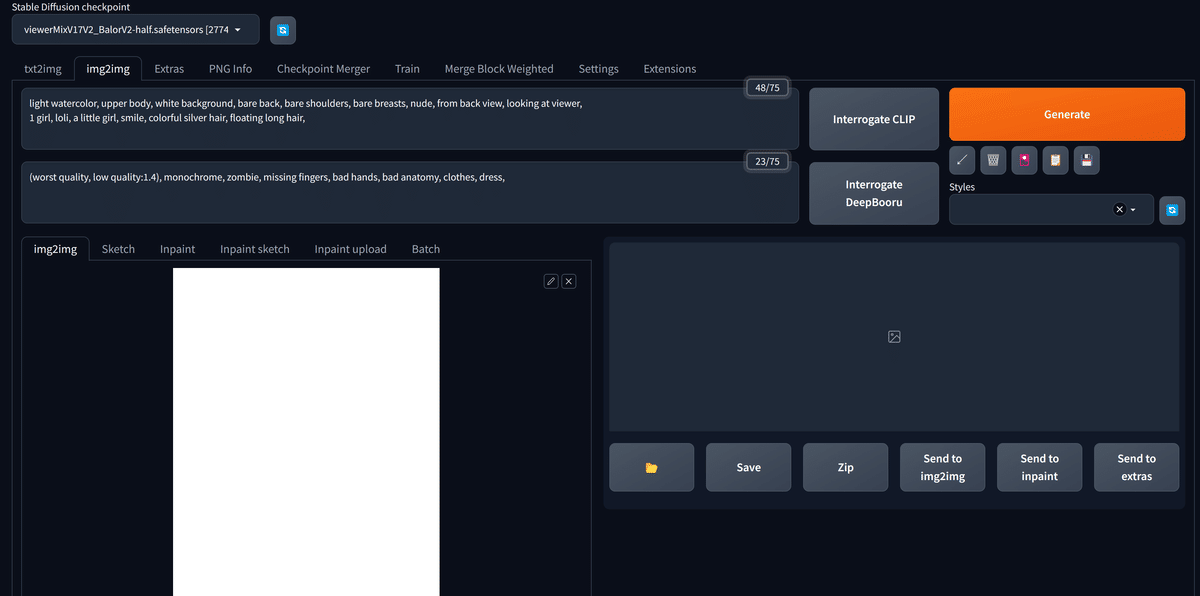
ここで、img2imgタブに真っ白な画像を入力しています。
以下をダウンロードして展開し、white.jpgをドラッグアンドドロップで配置してください。
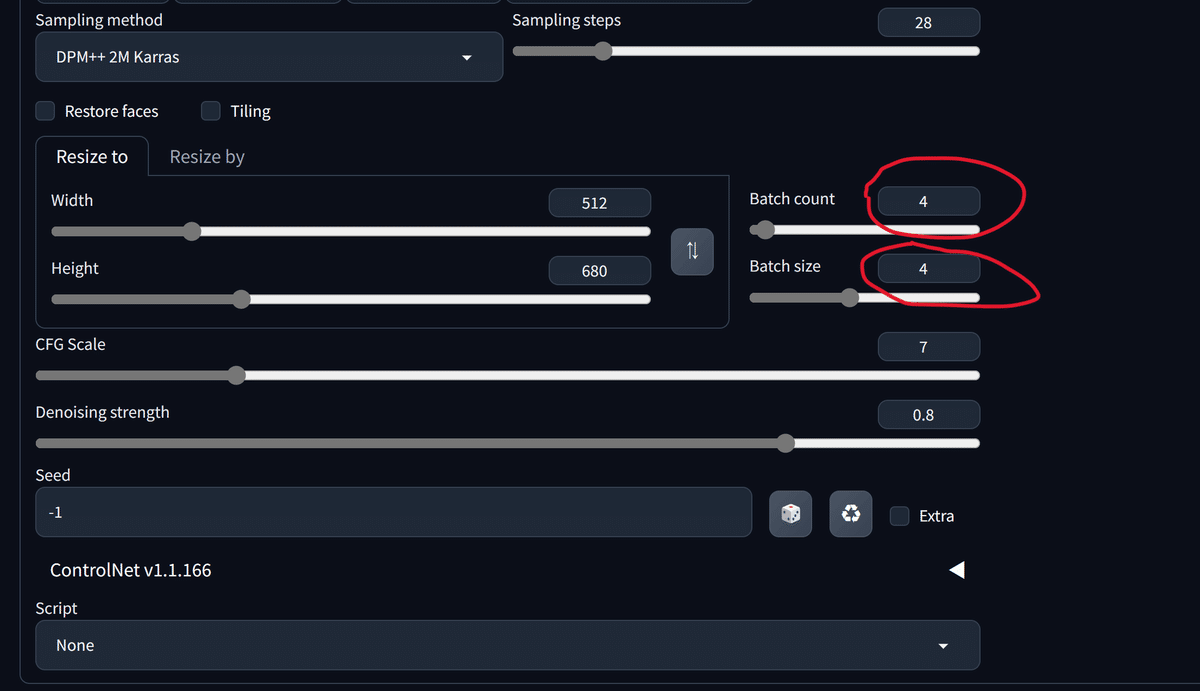
続いて各種設定を行います。
画面をスクロールし、下の画像のように設定を変更します。

ここまで来たらあとは生成するだけです。
右上にあるGenerateをクリックしましょう。
画像のように出力結果が得られるはずです。
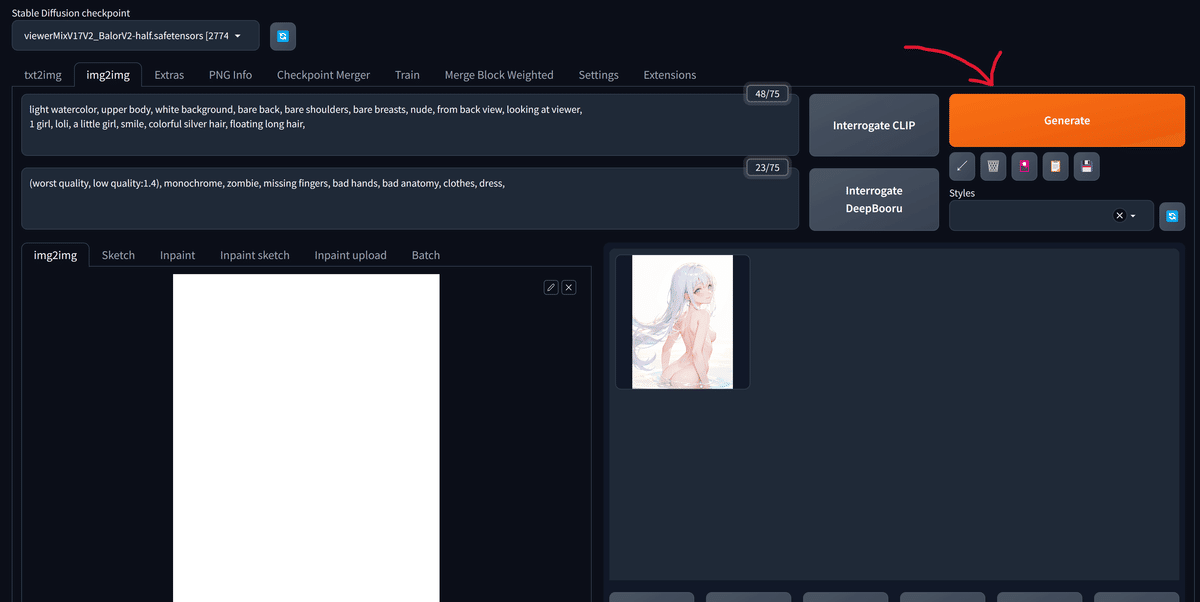
今回、筆者が得られた画像は以下でしたが、おそらく違う結果が得られたはずです。これはSeedによって同じプロンプト、設定であってもランダムな出力が得られるためです。
この画像のSeedは3280277120でした。

Seedを固定したい場合は以下のように入力します。ランダムにしたい場合はサイコロのマークをクリックすればOKです。

今回は1度の生成でかなりいい構図の画像が得られましたが、通常はこの作業を繰り返します(いわゆるガチャ)。繰り返すときに便利な設定としてBatch sizeとBatch countがあります。
Batch sizeは1回に生成する枚数を制御するため、複数枚を高速に生成できますが、GPUのメモリを大きく消費します。
Batch countは生成を指定した回数だけ繰り返してくれるもので、下の例では4回繰り返しています。
生成結果です。
表題のTwitterに投稿した画像を生成した際には同条件でBatch size 8、Batch count 10で80枚生成し、以下の画像を選びました。

色味を決める
気に入る構図が得られたら、次に色味を決めます。
既に色味も完璧だと思う場合にはスキップしても大丈夫です。
気に入った構図の画像を下のようにimg2imgタブに入力します。
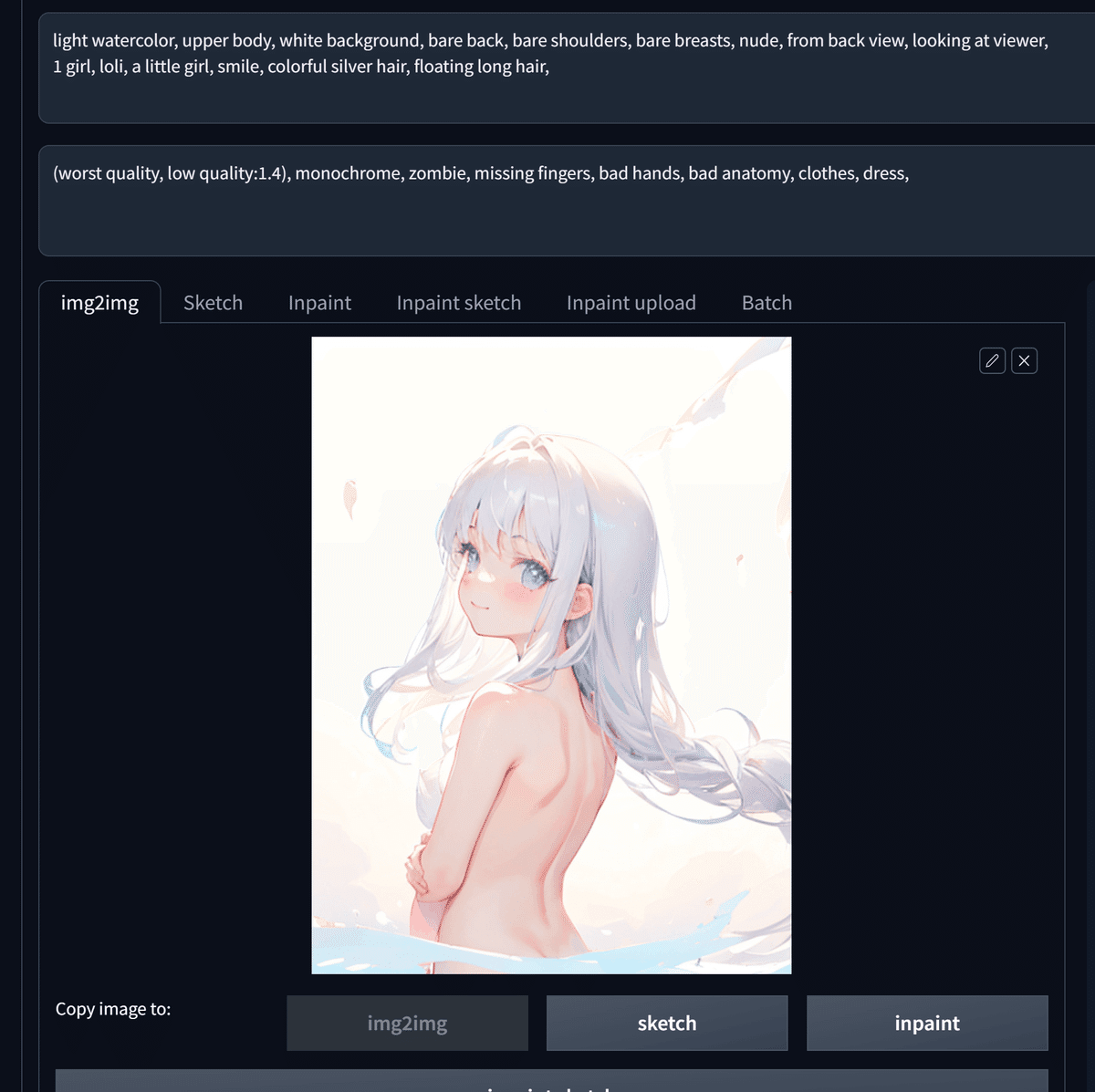
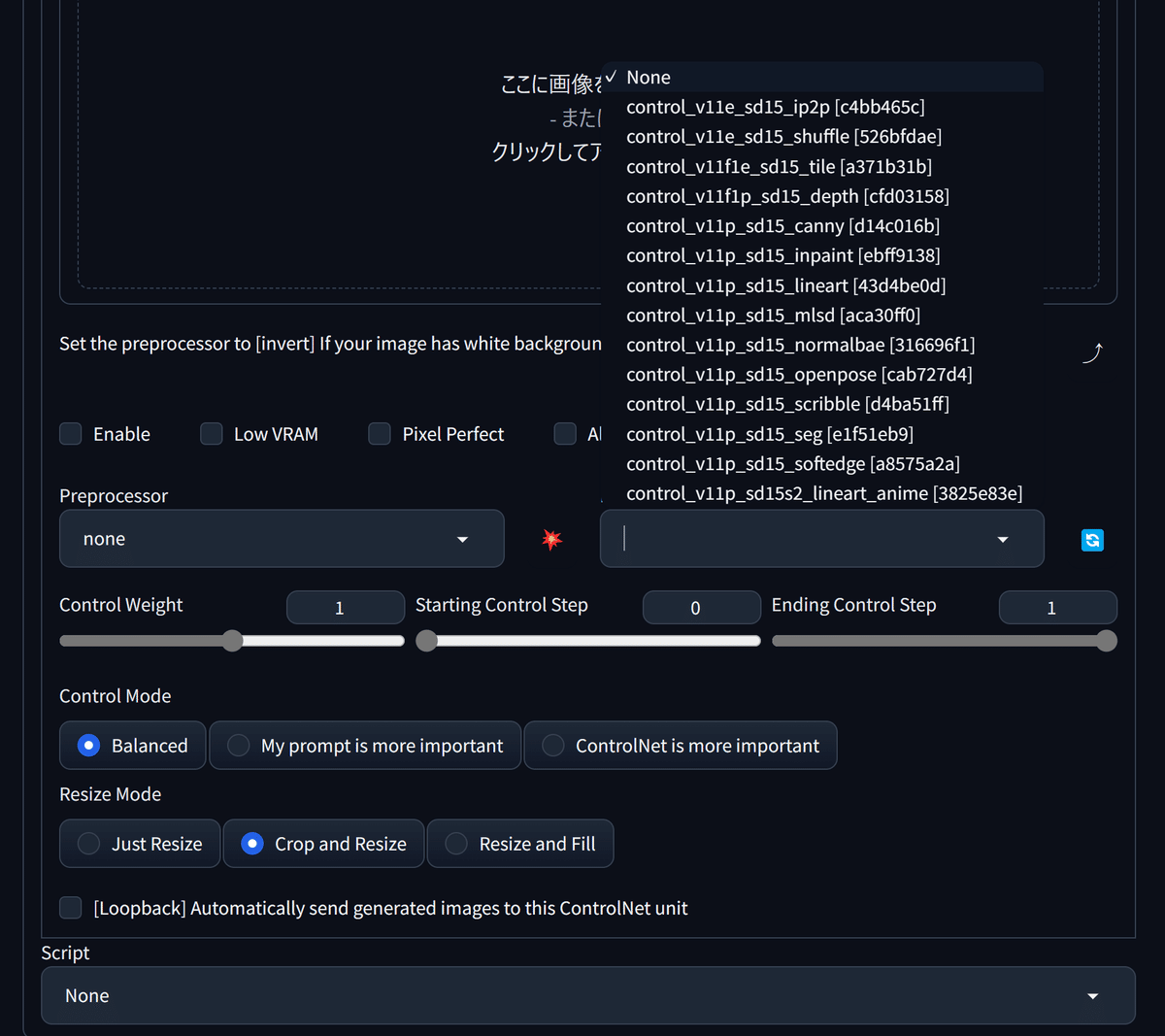
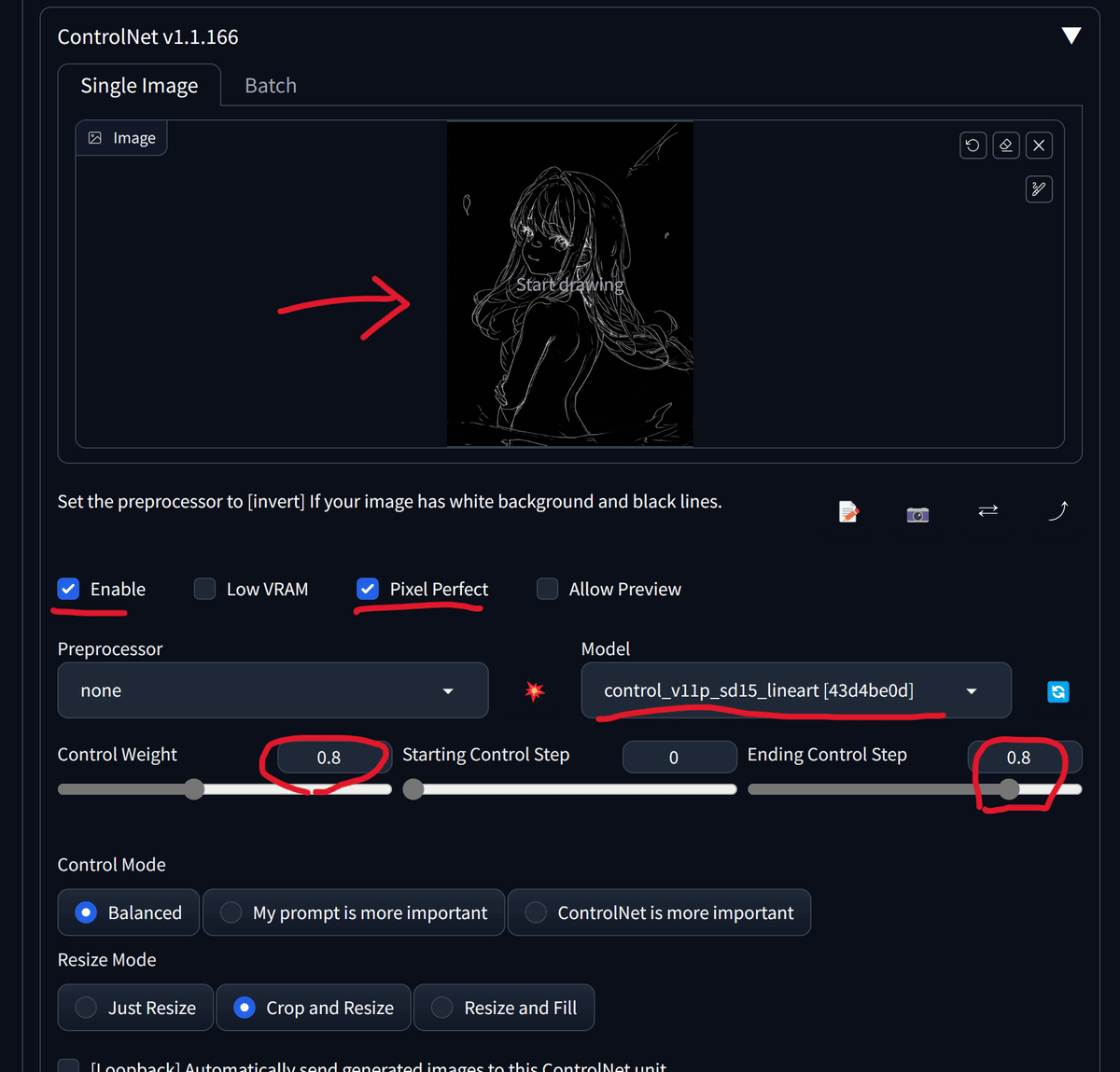
ControlNetを選択し、以下のように設定を変更します。
Batch sizeとBatch countは1に設定してください。
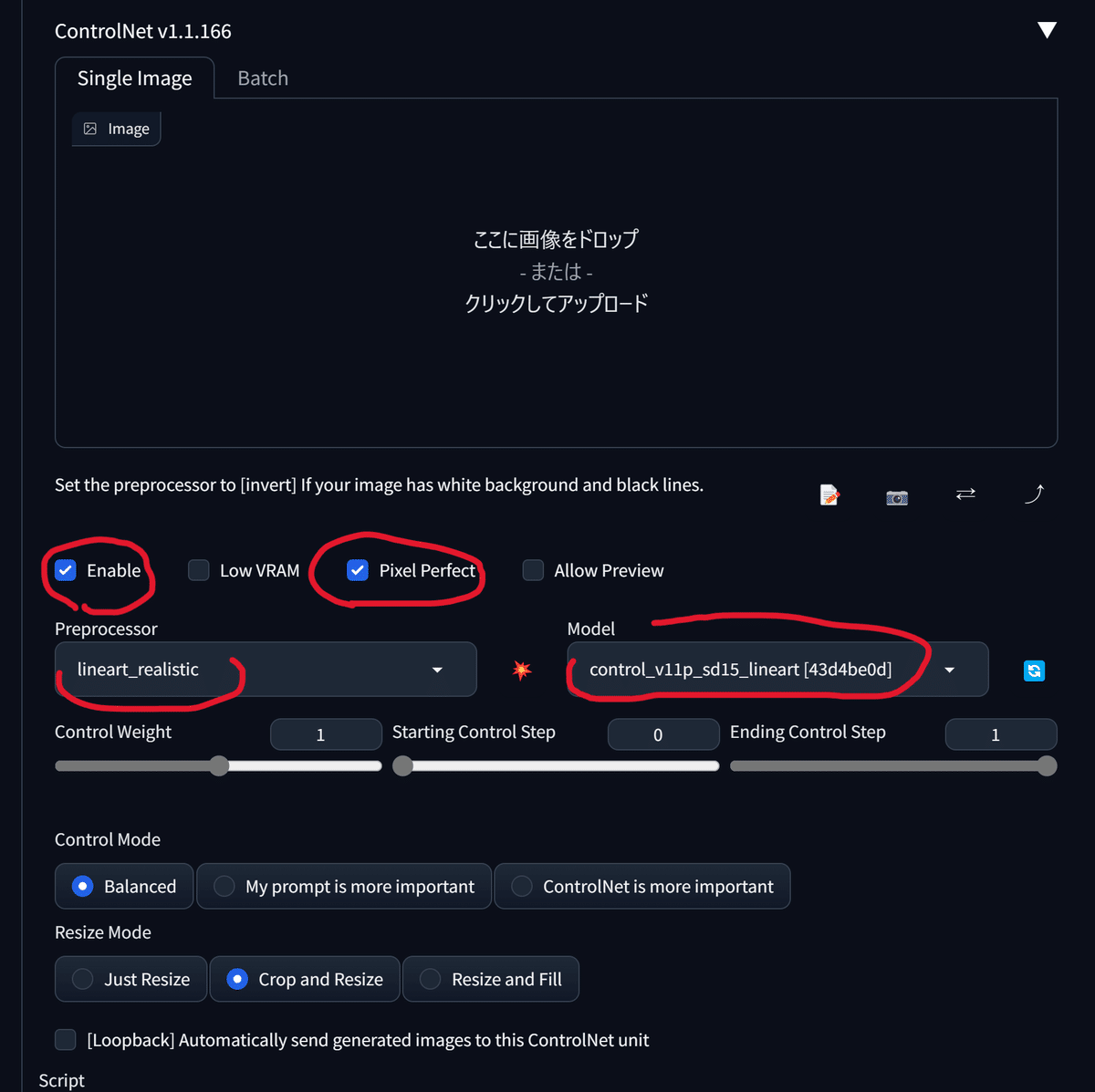
この状態でGenerateすると以下のような画像が得られます。
この画像を用いて構図を保ちつつ、色味を変化させていきます。

txt2imgタブに移動します。
プロンプト、WEB UIの設定をこれまでと同様、以下のようにします。
続いてControlNetを開き、先ほどの画像をドラッグアンドドロップして配置します。また、各種設定を以下のようにします。
この設定でGenerateを押して生成されたのが以下の画像です。

胸のあたりによく分からないものがあります。
意図しない結果になった場合、先ほどの黒い画像が原因である場合が多いため、修正が必要です。
先ほどの画像を画像編集ソフトで開きます。
ここではgimpを使用します。

赤の矢印で示した箇所が影響していたので、黒く塗りつぶして修正します。
また、指も若干修正しました。

修正した画像を再度ControlNetに配置し、生成します。

いい感じです!
この後は自分の好きな色味を探すため、モデルを変えたりパラメータを調整したり、プロンプトを変更したりしてベースとなる画像を決定します。
ControlNetの設定を少し変更し……
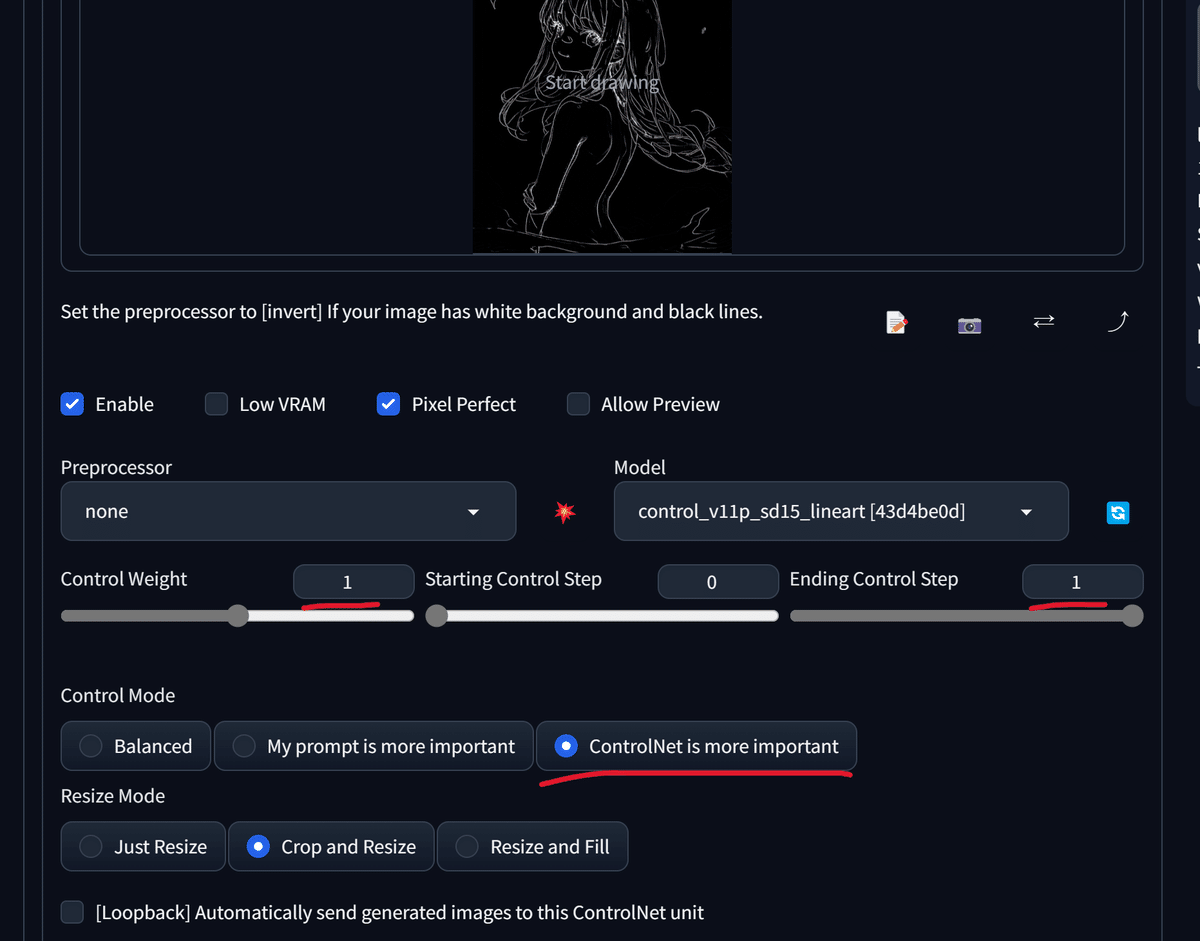
最終的に以下の画像を得ました。

画質を上げる
最後の仕上げに画質を向上させます。
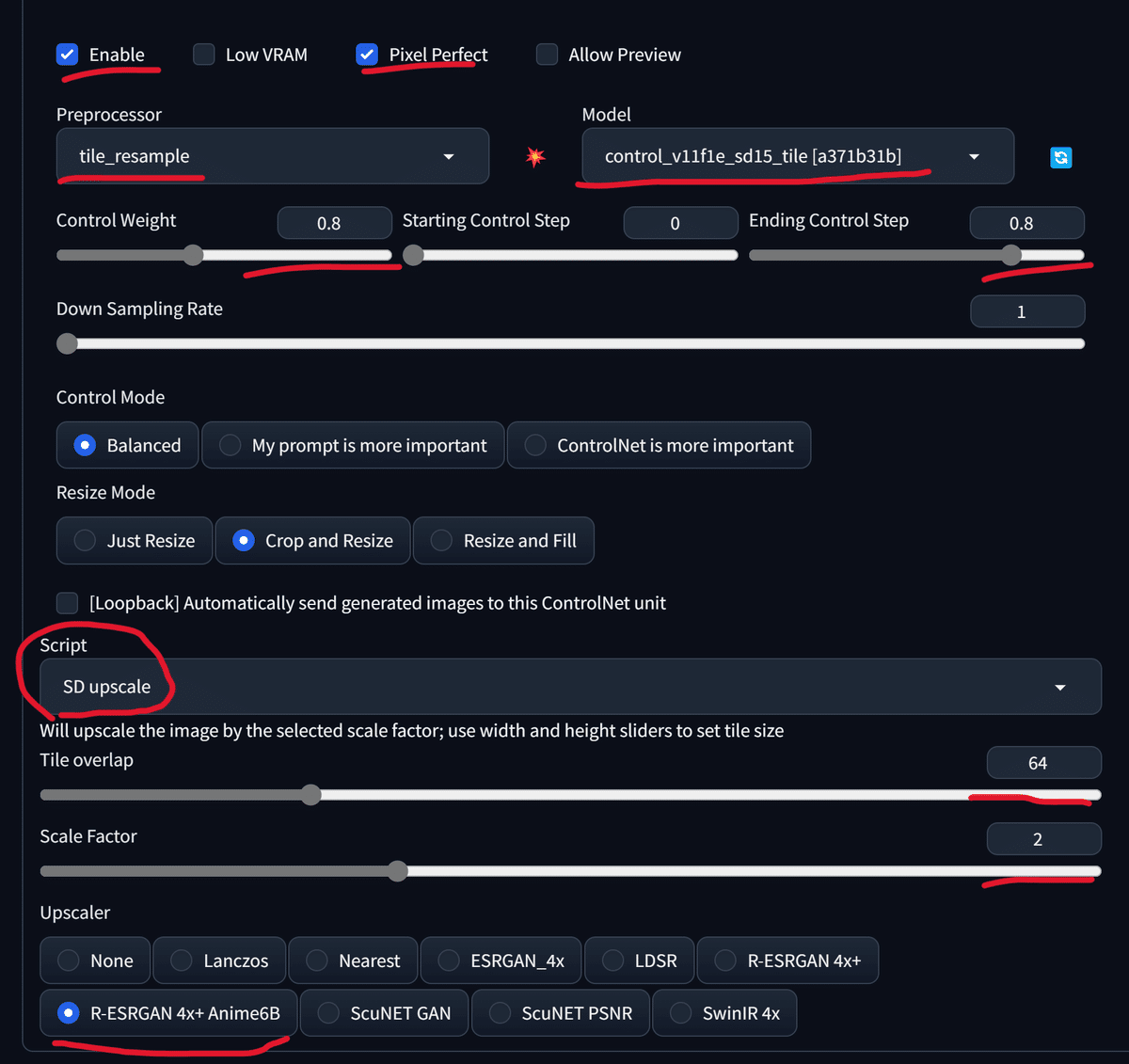
ExtrasタブにはUpscalerがありますが、今回はControlNetのtileを利用します。
……が、その前に指を軽く修正しておきます。
スポイトを使って同じ色で指を描きつつ、gimpの「にじみ」などの機能で境界線をぼかすといい感じになります。

img2imgタブに移動します。
ベースとなる画像をドラッグアンドドロップで配置し、プロンプトやControlNetの設定を変更します。

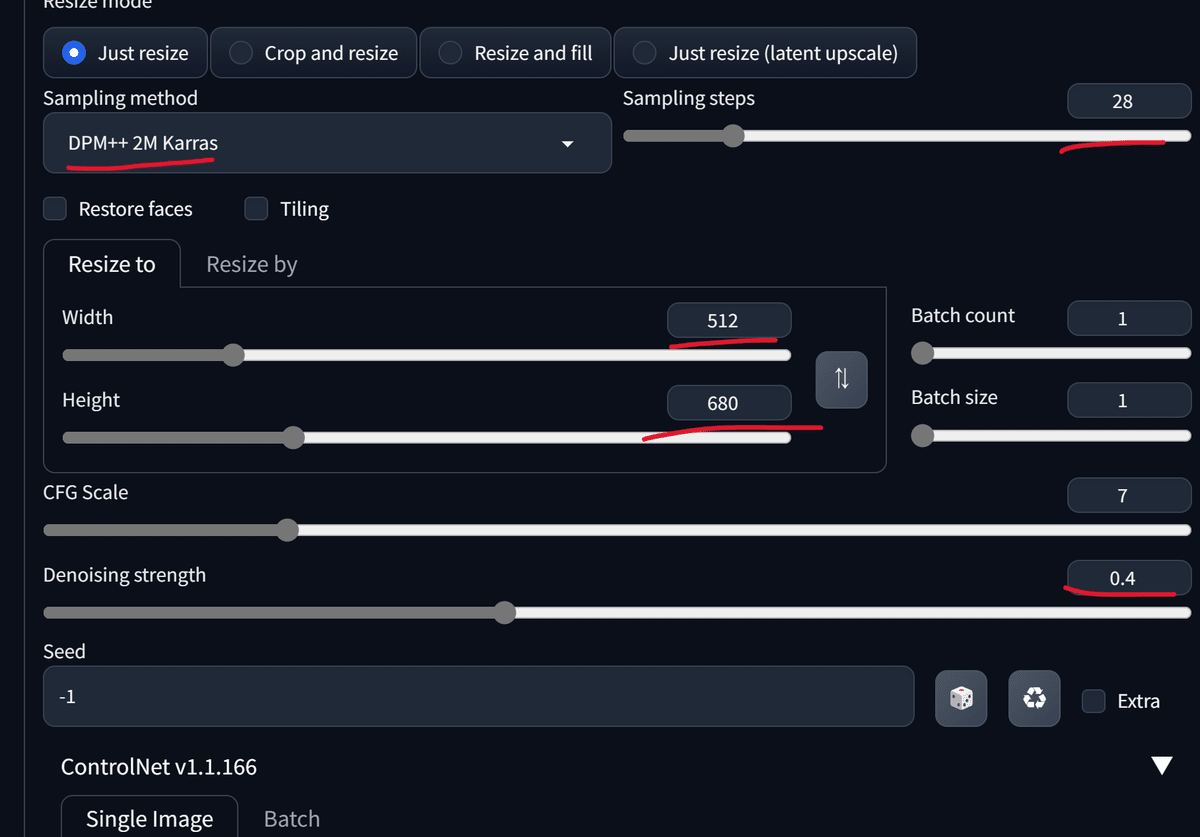
生成結果です。

ここからはDenoising strengthを調整して何枚かの候補を得ます。



Denoising strengthを1に近づけることで書き込み量を増やすことができますが、表情が大きく変化したり、不自然な指が生えてきたり、比喩ではなく小さな妖精が出現したりします。
そこで、Denoising strength 0.3~0.4程度で得た画像を表情に用い、他の画像を背景に用いることでより良いものにします。
ここでレイヤー分け可能な画像編集ソフトが必要になります。

画像のようにレイヤーに分け、すべてのレイヤーに対して、gimpであればレイヤー>透明部分>アルファチャンネルの追加とクリックします。
この状態で消しゴムを用いると透明になるので、余計な書き込みを透明にしていくことでより好みの画像に近づけることができます。

これで完成でもいいですが、さらにControlNet tileによって画質を上げます。
設定は変えず、編集して得られた画像をimg2imgにドラッグアンドドロップで配置します。
Denoising strengthを0.3程度にし、再度Generateします。

表情を含めていい感じになりました!
ここで修正することもありますが、大まかにはこのような流れで生成しています。
Twitterに投稿した画像については、以下のモデルを用いて生成した候補画像を組み合わせ、ControlNet tileで画質を上げた後に若干修正しています。
AnythingV5_v5PrtRE.safetensors
ShiratakiMix-add-VAE.safetensors
viewer-mix_V1.7V1_Balor-V2-half.safetensors(最初に説明したviewer-mixのバージョンのみ違う同構成モデル)
ここから得られた画像が以下です。

これをControlNet tileで画質を上げます。

parameters light watercolor, upper body, white background, bare back, bare shoulders, bare breasts, nude, from back view, looking at viewer, 1 girl, loli, a little girl, smile, colorful gradation, colorful silver hair, floating long hair, Negative prompt: (worst quality, low quality:1.4), monochrome, zombie, missing fingers, bad hands, bad anatomy, clothes, dress, badhandv4, Steps: 28, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1162480420, Size: 2048x2731, Model hash: 8b16c0d634, Model: viewer-mix_V1.7V1_Balor-V2-half, Denoising strength: 0.35, Ultimate SD upscale upscaler: R-ESRGAN 4x+ Anime6B, Ultimate SD upscale tile_width: 1024, Ultimate SD upscale tile_height: 1024, Ultimate SD upscale mask_blur: 8, Ultimate SD upscale padding: 32, ControlNet 0 Enabled: True, ControlNet 0 Preprocessor: tile_resample, ControlNet 0 Model: control_v11f1e_sd15_tile [a371b31b], ControlNet 0 Weight: 0.8, ControlNet 0 Starting Step: 0, ControlNet 0 Ending Step: 0.8, ControlNet 0 Resize Mode: Crop and Resize, ControlNet 0 Pixel Perfect: True, ControlNet 0 Control Mode: Balanced, ControlNet 0 Preprocessor Parameters: "(512, 1, 64)", Noise multiplier: 1.05
腕のあたりを若干修正して完成です!

あとがき
ここまでお読みいただきありがとうございました!
いきなり8000文字オーバーになってしまいましたが、なんとか詰め込めたかなと思います。
以下で電気代を支援していただける方向けにおまけとして生成時のイラスト80枚やpng形式のLineart、最後の修正時のgimpファイルと構成画像、grid imageをzipファイルで載せています。
この記事が役に立った場合にはぜひお願いいたします!
ここから先は
¥ 100
この記事が気に入ったらサポートをしてみませんか?