
仮想通貨で右肩上がりの結果を得る機械学習

機械学習が過去の価格データから将来の価格を予測してくれるのであればこんなに嬉しいことはありません。ネットで検索してみると機械学習で株価が予測できたという記事がたくさん見つかります。これで資産を増やすことができる、と思って試してみるとあれ?全然うまくいかないぞ、という方はこの記事を読んでみることをお薦めします。
私自身はネットや論文で株などのトレードに機械学習で良い結果が得られた、というものを見つけては実際に試してきました。ところが、実際に試してみると全然良い結果が得られないのです。ソースコードを公開しているものもあって確かにその通り動かすと訓練データとテストデータの結果は公開されている通りにはなります。ですが、フォーワードのデータに試してみると全然違う結果になってしまう。
なぜだろう、と考えてみて私はある間違いに気がつきました。トレードの機械学習で非常に良い結果が出ているものを全て検証してみたのですが、全てが同じ間違いを犯していました。もちろん間違えていないものもありましたが、その場合は良い結果は出なかったという結論で記事が締めくくられています。
チャートの動きはランダムウォークともいわれているので、そのようなデータから簡単に特徴を見つけてくれるほど機械学習が賢いとも思いません。画像認識の世界ではディープラーニングは成功を収めていますが、そもそも画像認識は人間が見れば正解は導き出せます。人間が見てわかることを機械に判断させようとしているわけです。それに比べて、チャートの世界は人間が見ても正解が全くわからないものを機械に判断させようとしています。人間よりも機械の方が判断力は高いのかもしれませんが、だからといって簡単に正解を出してくれるようなものとも感覚的には思えません。画像認識の機械学習でも、ただの画像データを入力に突っ込めば良いというものではなく、多くの前処理が必要です。機械が正しい判断をするためには、様々なフィルタリングやアンサンブル学習をさせた努力の賜物です。
では、チャートにもアンサンブル学習を入れてみるなど様々な努力をすればうまくいくでしょうか。私の場合はうまくいかず一度諦めました。確かに証券会社などでは AI を導入したトレードをしているなどの話も聞きましたが、そのためには専門的な統計知識などを駆使したモデル構築がされているのでしょう。とても素人ができるようなものではないと感じたのです。
一度は諦めるのですが、そんな時 richmanbtc さんという方の存在を知ります。全くの独学で機械学習を使って仮想通貨で月 1 億を叩き出すという方です。これは非常に印象深くてもう一度自分も機械学習のトレードを試してみようと思ったものです。
https://www.amazon.co.jp/本-richmanbtc/s?rh=n%3A465392%2Cp_27%3Arichmanbtc
richmanbtcさんはソースコードも公開していたので読んでみました。確かに参考になる部分はありました。公開されていたソースコードは確かに良い結果も示してはいましたが、だんだん機能しなくなっていく様子も見えていました。今では公開しているサンプルソースはトレードとしては全くうまくいっていないはずです。
richmanbtcさん自身は公開したソースコードとはまた別な手法で月に億を稼ぐトレーダーに辿り着いたようですが、最近はあまり結果が振るわないという記事も目にした記憶があります。
相場は変わります。つい、この前まで右肩あがりで高騰を続けていた仮想通貨の相場は今は下げ基調かもみあいが続く相場が多くなっています。もし、試行錯誤によって良い機械学習モデルを作ることができたとしても、相場が変わってしまえば使い物にはなりません。また試行錯誤をすれば利益を上げるモデルを作成することはできるのかもしれませんが、どうやったらうまく機能する学習モデルを構築できるかを知らなければ、とても利益をあげ続けるということは難しいと感じました。
どうやったら訓練データだけでなくテストデータにも機能し、さらにはその先のフォワードデータで機能し続けるモデルを作れるだろうか。この答えを考えることがチャートを使った価格予測で右肩上がりの機械学習モデルを作ることに成功したきっかけでした。以下が私が作成した機械学習の利益曲線です。
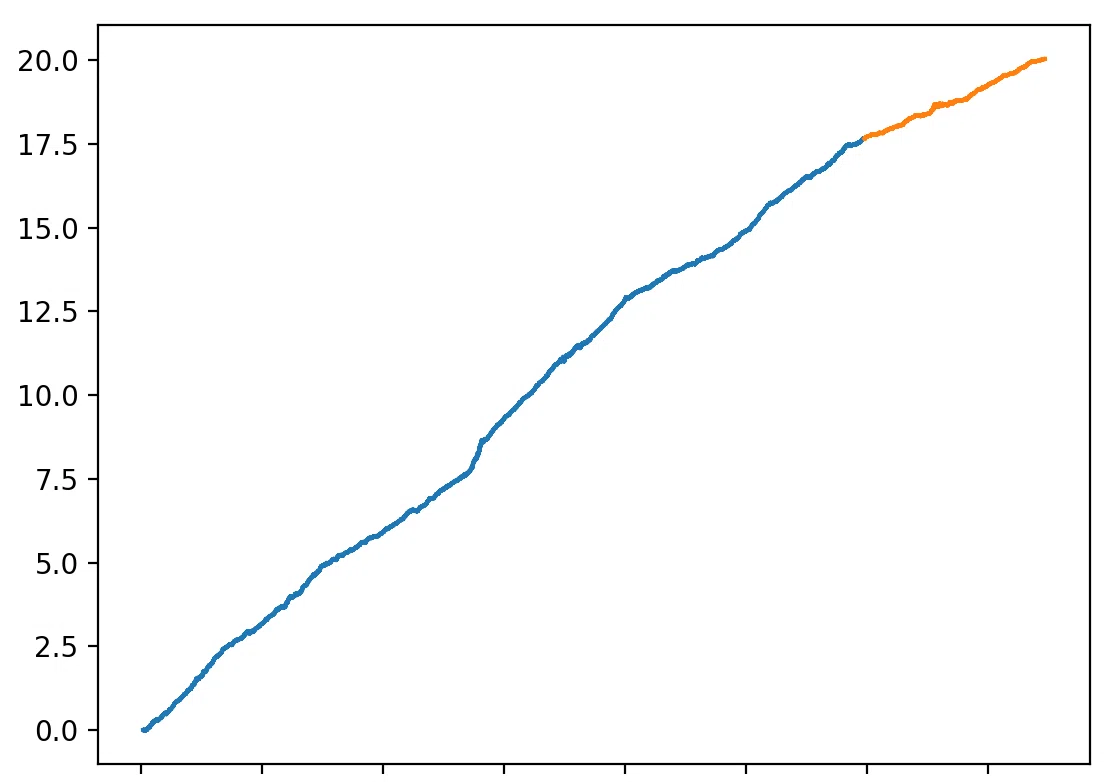
曲線というよりは直線に近いですね。青が訓練データでオレンジがテストデータです。BTCについて機械学習モデルを作成してモデルが予測した価格が上に行くなら買い、下に行くなら売ります。当たれば利益を計上し、外れれば損失を計上します。積み上がっていく利益率をプロットしたものです。
大事なことは右上がりの傾向はこの先も続いていくように考えながらこのモデルを作成したということです。テストデータの結果を確認して、その数値が良くなるまでモデルのパラメータを調整して何度も訓練をやり直すということは一切していません。テストデータの確認は最後に1回やるだけです。テストデータと訓練データで同じ予測精度になるように狙いながらモデルを作成していくのです。
テストデータが良くなるように何度もトライアンドエラーをするやり方だと、確かにテストデータに対する結果を良くすることはできるでしょうが、再現性があるモデルになっているとは言えないでしょう。フォワードに対して運用すると間違いなく性能が下がってしまいます。
何よりモデルに対してトライアンドエラーを繰り返してもこのような綺麗な右肩あがりの結果を得ることはできないでしょう。私の場合はこの方法を確立する前は、モデルパラメータを色々チューニングすることを行いましたがこのような綺麗な結果に辿り着くことはできませんでした。
どのように再現性が高いモデルを構築するかを考えた結果、再現性が高いと同時に良い結果を示すモデルを作ることができるようになったのです。ここではこの方法を公開したいと考えて記事を書き始めています。
この記事が気に入ったらサポートをしてみませんか?