
生成系AI+医療・健康データ=次世代医療【前編】:次世代デジタル医療の3つのキーワード

以前、「社会の価値の総量を増やすための、医療DXの真の役割とは?」で、デジタル化による効率化だけにとどまらず、新たな価値とイノベーションを創出するデジタル医療の重要性について説明しました。医療DX・デジタル化は新たな治療法やデジタル医療機器のような革新的な価値を生み出し、人々の幸福や効用を増加させることで真の効果を発揮します。デジタル化による効率化にとどまらず、社会の価値の総量を増やすためにイノベーションに注目して投資することが重要だと指摘しました。
それでは、医療DX・デジタル化、特に今回は「生成系AI」や「基盤モデル」と呼ばれる次世代AI技術と、「医療・健康データ」を取り上げ、具体的にどのような具体的な価値が創造されるか、次世代デジタル医療の3つのキーワードを説明して、具体的な例を示していきましょう。
次回は、この新たな技術を手にいれ、医療・健康データを組み合わせた人類が、どのような新しい価値と創出できるかについて、「生成系AI+医療・健康データ=次世代医療【後編】:創出される革新的サービス・ビジネス」で解説します。

【用語解説】パーソナル・ヘルス・レコード(PHR)とは?
今後のお話をするにあたり、用語解説をします。
医療・健康データのひとつとして、パーソナル・ヘルス・レコード(PHR)と呼ばれるものがあります。PHRは、個人の健康情報を自分で管理するための記録システムを指します。「自分が管理する」、ということがポイントです。これには、医療機関での診療記録、薬の処方、検査結果、ワクチン接種情報など、健康に関連する様々なデータが含まれます。政府が進める、医療・健康データを自分で管理する仕組みについては、こちらでも解説しています。
PHRは患者が自分の健康情報にアクセスし、必要に応じて共有できるように設計されています。これにより、患者がより自分の健康状態を理解し、医師と効果的にコミュニケーションを取りながら、健康管理や治療の意思決定に役立てることができます。
特徴的なポイントは以下のとおりです:
個人による管理:
PHRは患者自身が管理し、健康データを直接アクセス・共有できる仕組みになっています。
統合された情報:
複数の医療機関で得た情報も一元化して管理できるため、全体的な健康状態の把握が可能です。
情報の共有:
必要に応じて医療従事者や介護者に情報を共有し、より良い治療やケアに活用できます。
PHRは個人の健康情報の管理と共有を容易にし、より質の高い医療を受けることをサポートします。

3つのキーワード
それでは、3つのキーワードを紹介します。それは、「①時系列、②多種類、③基盤モデル」。ひとつづつ見ていきましょう。

① 医療・健康データは、時系列データである
パーソナル・ヘルス・レコード(PHR)を含む医療・健康データは、医療機関での診療記録、薬の処方、検査結果、ワクチン接種情報など、健康・医療に関連する様々なデータが含まれます。また、ウェアラブルデバイスから得られるライフログデータもPHRと呼ばれます。
医療・健康データが時系列データであるというのは、そこに記録される情報が時間の経過とともに蓄積されるためです。たとえば、血圧、体重、血糖値などの定期的な測定結果や、医療機関で受けた検査・治療の記録、予防接種の履歴、服薬のスケジュールなどが挙げられます。これらの情報は時間順に記録され、例えば血圧の推移や体重の変動といった、過去から現在に至る健康状態の変化を把握することができます。
このように、PHRは、これまでの画像検査や血液検査など病院でなければ得られない断片的で一時的なデータとは異なり、継続的に時間をかけて蓄積されるデータです。それにより、個人の健康傾向やパターンを理解し、適切な予防策や医療方針を立てるのに役立ちます。

医療の現場において知りたいこと
さて、皆さんが病院にいって知りたいこと、また医療従事者が知りたいことは何でしょうか?患者さんの立場で行けば、「自分の病気が治るか」、医師の立場ですと「目の前の患者さんを救えるかどうか」ですよね。
しかし、例えば、医薬品の薬事承認において、効果があるかどうかについて確認に使われたデータは、もちろん、あなたのデータではなく、あなた自身で効果を事前に確かめたわけではありません。すなわち、他の誰かの研究データで確かめられた結果をもって、「おそらく、私にもこの医薬品は効果があるだろう」という仮定がされています。そのため、本当に自分に効くのか、この患者さんに効くのかという判断には限界があります。
それでは、なぜこのような限界があるのでしょうか?

従来の医学研究
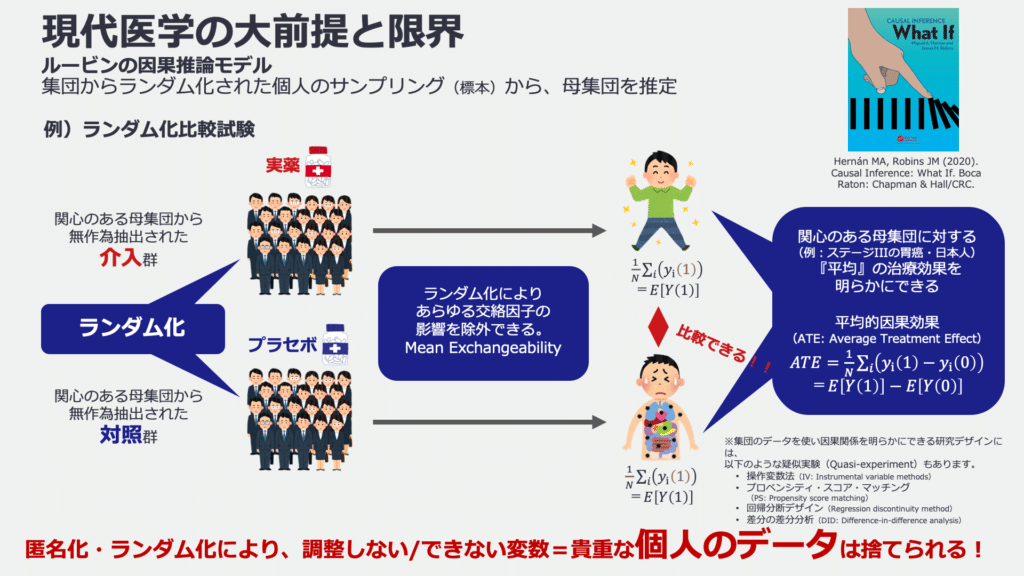
以下の図は、従来の医学研究のデザインを示しています。
これは、ランダム化比較試験(RCT)とよばれ、参加者をランダムに2つのグループに分けて、一方に新しい治療を、もう一方に通常の治療を施す方法です。これにより、治療効果を公平かつ正確に評価できます。RCTは科学的な証拠の中で最も信頼性が高いとされ、新しい薬や治療法の効果を検証する際に重要な役割を果たします。
ランダム化比較試験(RCT)は、マーケティング業界で広く用いられていて、A/Bテストとも呼ばれます。異なるバージョンのウェブページや広告、製品などを比較し、どちらがより効果的かを判定するために使用されます。
この際に、最も重要なことは、サンプリングとランダム割付です。ランダム割付によって、調整していない個人差やばらつきを均等化することができます。それによって、治療薬などの効果の「平均的な」効果を明らかにできます。
あくまで、他の誰かで行われた研究結果であり、そこからわかるのはある集団における「平均の」効果であるため、個人の差や特徴まで考慮した判断はできないのです。

【専門的な説明】従来の医学研究の限界
さらに、もう少し、学術的な説明をします。(読み飛ばして大丈夫です。)
ランダム化比較試験(RCT)は、医学研究や社会科学など多岐にわたる分野で使用される、エビデンスの質を評価するための最も信頼性の高い研究デザインの一つです。RCTの主な特徴は、参加者をランダムに実験群と対照群に割り当てることで、治療法や介入の効果を公平かつ正確に測定することができる点にあります。このランダム化により、選択バイアスが排除され、治療効果の真の影響を把握することが可能となります。その背景の理論の一つが、ルービンの因果推論モデル(RCM)です。
ルービンの因果推論モデル(RCM)は、個々の介入や治療が個人に与える効果を評価するために用いられる統計的アプローチです。このモデルは、各個体が異なる条件下でどのような結果を示すかという「潜在的結果」を考慮し、介入の割り当てをランダム化することで治療効果を純粋に評価しようとします。また、他の介入に影響されずに、各個体の介入のみが結果に影響を及ぼすという仮定(SUTVA)を置くことで、より正確な因果関係の推定が可能になります。ルービン因果モデルでは、平均治療効果(ATE)や条件付き治療効果(CATE)などの指標を用いて、介入が集団に与える平均的な影響や特定のサブグループに与える影響を測定します。
ルービンの因果推論モデル(RCM)において、ランダム化は非常に重要です。これにより、治療群と対照群の間で事前の特性が等しくなり、介入の効果を純粋に測定できるため、結果の差が治療自体によるものであると確実にすることが可能です。ランダム化は選択バイアスや交絡変数の影響を排除し、因果効果の信頼性と妥当性を高めます。
ルービン因果モデルは、医療、社会科学、経済学など多岐にわたる分野で広く使用されています。実験が倫理的または実践的な理由で実施できない場合、このモデルは観察データから因果関係を推定する強力なツールとなります。
しかし、以下の図で示すように、ランダム化は、個人のばらつき、すなわち治療群と対照群の間での潜在的な共変量(影響要因)の分布を均一化することにより、個人ごとの差や特徴的なデータは捨ててしまっているのです。(バイアスにつながってしまいますからね)それによって、個人単位での因果推論ができないという、現代医学の限界となっているのです。
個人の時系列ライフログデータは、因果関係の解明における究極のツール
近年、ウェアラブルデバイスに多くのセンサーが搭載され、数多くのバイオマーカーが測定できるるようになっています。例えば、これまでは、血液検査は病院などの医療機関で、月に1回などの感覚でしか計測できませんでした。しかし、近い将来、病院で検査することと同等レベルの検査結果が、いつもどこでも得られるようになることが予想されます。

個人の時系列ライフログデータは、一個人の行動、生理的反応、環境変化などを継続的に記録したデータで、サンプル数が膨大になることが特徴です。時系列データは、単一の瞬間だけでなく、時間を通じての変動を捉えるため、因果関係を明らかにするのに非常に有効です。

データサイエンスが急速に発展する中、個人の時系列データが重要な情報源となっています。このデータは、個々人の行動、生理的反応、環境変化を時間を通じて継続的に記録し、サンプル数が膨大になることが特徴です。時系列データは過去と現在の自分自身を対照として比較・モデル化し、未来を予測することが可能で、特定の個人(n=1)の因果関係を明らかにするための究極のツールとなります。
すなわち、個人の医療・健康時系列データは、上記の伝統的な医学研究とその限界を突破できる可能性をもっているのです!
このデータの活用により、個人の行動が健康に及ぼす影響や、環境変化が心理状態に与える効果を具体的に追跡し、因果関係を科学的に解析することができます。しかし、この分析を行うには、従来の医学研究では用いられてこなかった新しい時系列データ解析手法が必要になります。ここで重要なのはサンプル数(n)よりも、データのサンプリングレートです。データの詳細度が高まるほど、より精密な因果関係の推定が可能になり、個別化された介入が実現します。

時系列データの分析は、相関関係の特定を超え、どの要因が実際に結果に影響を与えるかを明らかにすることで、個別化医療、ウェルネスの推進、生活習慣の最適化に至るまで、幅広い応用が期待されます。このデータ駆動型のアプローチは、科学的根拠に基づく意思決定を可能にし、それぞれの個人に最適な未来を設計するための強力な基盤を提供します。

②医療・健康データは多種類である
ところで、AI・深層学習(ディープラーニング)という言葉を聞かない日はないと思いますが、そもそも、「AI・深層学習」とはなんでしょうか?一言で、なんと言えるでしょうか?

AIとは行列計算である
私は、「AI・深層学習」とは「行列の計算」であると考えています。ディープラーニングは、大量のデータから特徴を学習する行列計算の技術です。この技術により、複雑なパターンや関係性をモデル化し、新たなデータに対する予測や分析が可能になります。

言い方を変えれば、「AI・深層学習」とは「行列の計算」なので、行列で表すことができれば、ディープラーニングできるということです。実際、医療データや個人の時系列ライフログデータは、画像、動画、波形などであり、これらは行列として表記することが可能です。すなわち、医学に関するさまざまなデータを単一のモデルで扱うということが可能であるということです。

「マルチモダリティ」とは
その登場以来、多くの話題を集めているChatGPTとその裏で動いている最新のGPT-4は、テキストだけでなく、画像を含む他の種類のデータも理解し、それらを統合して処理することができます。具体的には、GPT-4はテキストと画像の入力を同時に受け取り、それらの情報を基にした質問に答えたり、内容を解析したりすることが可能です。
この能力により、GPT-4は例えば画像の内容を説明したり、画像と関連したテキスト情報からの問いに答えたりすることができます。また、複数の情報源からのデータを融合し、より豊富な背景情報やコンテキストを提供することが可能です。この機能は「生成系AI」と呼ばれ、多種類のデータを扱えることを「マルチモダリティ(多種類)」と呼び、2つ目のキーワードです。

医療・健康データのマルチモダリティ
上記でも述べたように、医療データや個人の時系列ライフログデータは、画像、動画、波形などであり、これらは行列として表記することが可能です。すなわち、医療・健康データのマルチモダリティであり、医学に関するさまざまなデータを単一のモデルで扱うということが可能であるということです。
これにより、より高次の仮説検証・シミュレーション・予測・データ生成が可能となります。このことは、次のセクションで説明します。


③PHRで基盤モデルを創る
さて、最後3つ目のキーワードが「基盤モデル」です。
近年の人工知能技術の中でも、特に注目されているのが大規模言語モデルです。その中でもGPT-4は、多くのアプリケーションでその能力を発揮しています。このモデルは、膨大な量のテキストデータを学習し、それに基づいて新しいテキストを生成する能力を持っています。そのため、ChatGPTのような会話型AIに使用されることが多いです。
GPT-4を含むこれらのモデルは「基盤モデル」とも呼ばれます。この用語は、モデルが多様なタスクやアプリケーションに適用可能であり、新たな技術や製品の「基盤」となることを意味しています。例えば、言語翻訳、文章要約、質問応答など、さまざまな領域で応用されています。

基盤モデル(Foundation Models)という用語はスタンフォード大学で提唱され、一つの大規模な学習モデルが広範囲の応用に使用されることを指します。スタンフォード大学の研究者たちは、これらのモデルの可能性を探求するとともに、倫理的、社会的な課題に対する深い理解を進めており、法学者、倫理学者、コンピュータ科学者など多様な分野の専門家が協力して、技術の進展とその社会への影響を評価しています。
基盤モデルの強みは、一つのモデルで多くの異なる問題を解決できる点にあります。それにより、開発者は特定のタスク専用のモデルを一から訓練する必要がなく、効率的にアプリケーションを開発することが可能です。また、これらのモデルは、新たなデータに対しても迅速に適応し、性能を向上させることができます。

深層学習による部分最適から、基盤モデルによる全体最適へ
深層学習は、複数の層を持つ人工ニューラルネットワークを利用してデータから学習する技術です。このアプローチは特定の問題に対して高度に最適化されたモデルを生成することが目的で、特定のタスクや限定されたデータセットに対して最適化されることを指します。つまり、部分最適化であり、一つのモデルが一つの問題を解決するために訓練されます。
一方で、基盤モデルは、より広範な応用が可能で汎用的なモデルを指します。これらは膨大な量のデータとタスクから学習し、さまざまな種類の問題に対応可能な能力を持っています。すなわち、深層学習とは対比的に、「全体最適化」です。多様なタスクに対して一つのモデルが柔軟に対応できることを意味し、多目的かつ汎用的な使用が可能です。基盤モデルは、それ自体がアップグレードや新たなタスクへの適応が容易であり、広範なドメインにわたる知識を統合しています。
この違いにより、基盤モデルは新しいタイプのデータや未知の問題に対しても柔軟に応じる能力を持ち、広い範囲の応用が期待されるのに対し、深層学習モデルは特定の問題を解決するために最適化されており、その適用範囲は比較的狭いです。

【より専門的な内容】基盤モデルと汎用人工知能(AGI)の将来
基盤モデルは、汎用人工知能(AGI)の実現に向けた基礎技術として重要な役割を果たしています。これらのモデルは大量のデータから学習し、多様なタスクに適用可能な一般的な知識と能力を獲得することが特徴です。これにより、基盤モデルはさまざまな新しい問題に対しても柔軟に対応できるため、汎用性の高い人工知能の開発に不可欠です。
特に注目すべきは、基盤モデルにおける転移学習の能力です。転移学習は、モデルが一つのタスクから学んだ知識を別のタスクに適用するプロセスを指します。基盤モデルでは、広範な初期トレーニングを通じて獲得した一般的な知識を活用し、少量のデータで新しいタスクに迅速に適応することが可能です。これは、AGIへの道のりで必要とされる適応性と汎用性を提供します。
このように、基盤モデルはその汎用性と転移学習の能力により、限定された専門的な知識を超えた、広範囲にわたる知識の応用を可能にします。これらの特性は、基盤モデルをAGIにおいて中心的な技術として位置づけるものであり、今後の人工知能研究においてその重要性は増すことでしょう。

筆者の研究内容
大規模言語モデルは、膨大なテキストデータから学習し、自然言語処理タスクを行うAI技術であると説明しました。昨今では、上記のように言語だけでなく、さまざまな映像や画像などのさまざまなデータを扱うことができます。
それでは、もし、同じく多種類で時系列データである医療・健康データで、大規模言語モデルのような基盤モデル、いうなれば「大規模人体モデル」を作ったら、何が起こる、何ができるでしょうか?私が代表を務める一般社団法人 持続可能社会推進機構では、ChatGPTが発表される数年前の2020年からこの開発に着手し、現在これに関する技術を特許出願中です。

「いのちの方程式®︎」とは?
私は、この医療領域のChatGPT/GPTである大規模人体モデルの技術を「いのちの方程式®︎」と読んでいます。
「① 医療・健康データは、時系列データである」で述べたように、これまでの医学研究では個人レベルのばらつき—すなわち、個々人の独特な特性が結果に及ぼす影響—は、真の効果を歪めるバイアスと見なされ、しばしば排除の対象とされてきました。通常、このようなばらつきは匿名化やランダム化によって取り除かれていますが、これにより個人特有のデータの価値が見過ごされがちでした。
今、私たちは「いのちの方程式」のアプローチでは、長い間無視されてきた個人レベルのばらつき—それぞれの特徴量—を重視します。ウェアラブルデバイスや行動経済学に基づく認知傾向などから得られる時系列データ、さらにはゲノムレベルの分子レベルデータに至るまで、膨大な個人データを活用することで、一人ひとりの全体像をモデル化します。
この技術では、金融工学、自動運転、自然言語処理など、他分野で活用されている最新の深層学習技術を医学領域に応用します。パーソナライズされた医療は、一人ひとりの患者に最適な治療計画を提案し、より効果的な健康管理を実現できるようになり、医療を根本から変える可能性を秘めています。
この先進的な取り組みにより、医療はもはや一般化された解決策を提供するだけでなく、個々の患者の具体的なニーズに応じたカスタマイズされたケアを提供する時代へと移行しています。これは単なる技術革新ではなく、より個別化された治療へと進むための哲学的シフトです。

【より専門的】「いのちの方程式®︎」と恒常性
恒常性は、生体がその内部環境を一定に保つメカニズムを指します。これには体温、pH値、電解質濃度など、生命活動に必要な条件が含まれます。例えば体温が外気温に影響されず一定に保たれたり、血液のpHがほぼ中性を保持したり、食後に上昇する血糖がインスリンによって調節されることで健康が維持されます。このように恒常性は生物体が外部環境の変化に適応し、生命活動を最適に行うための基礎となっています。
この恒常性について、医療・健康時系列データを解析し、単一でマルチモーダルな基盤モデルである大規模人体モデル「いのちの方程式®︎」を構築すれば、上記のような、個体レベルでの人体の反応をモデル化できる可能性があると考えています。恒常性の維持は健康を保つ上で極めて重要であり、このバランスが崩れると多くの疾患が引き起こされる可能性があります。
私たちは、恒常性が保たれた状態を「健康」、その破綻した状態を「疾患」、破綻を見つけることを「診断」、元の恒常性に戻すことを「治療」と読んでいます。
もし、私が開発している「いのちの方程式®︎」が、生成系AIのように、上記のような状態などを予測・シミュレーションできたら、今の医療は具体的にどのように変わるでしょうか?

次回は、この新たな技術と医療・健康データを組み合わせた人類が、どのような新しい価値と創出できるかについて、「生成系AI+医療・健康データ=次世代医療【後編】:創出される革新的サービス・ビジネス」で解説します。
この記事が気に入ったらサポートをしてみませんか?