機械学習:モデルの評価とハイパーパラメータのチューニング:グリッドサーチ

検証曲線で扱ったように、パラメータの一つを最適化するのではなく、網羅的探索手法により最適なパラメータの組み合わせを見つけ出すのがグリッドサーチである。
ハイパーパラメータ値のリストを指定し、それをGridSearchCVに入れて行う。
パイプラインは標準正則化と、サポートベクトルマシンの組み合わせとし、このサポートベクトルマシンのsvc$${\_\_}$$Cとsvc$${\_\_}$$gamma、svc$${\_\_}$$kernelのlinearかrbfをチューニングしている。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
pipe_svc = make_pipeline(StandardScaler(),SVC(random_state=1))
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
param_grid = [{'svc__C': param_range,
'svc__kernel': ['linear']},
{'svc__C': param_range,
'svc__gamma': param_range,
'svc__kernel': ['rbf']}]
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=10,
n_jobs=-1)
gs = gs.fit(X_train, y_train)
print(gs.best_score_)
print(gs.best_params_)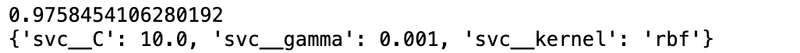
この組み合わせを使った、テスト結果での性能は以下のように出せる。
clf = gs.best_estimator_
clf.fit(X_train, y_train)
print('Test accuracy: %.3f' % clf.score(X_test, y_test))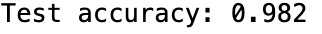
グリッドサーチとk分割交差検証
入子式の交差検証は、機械学習のアルゴリズムのどれかを選ぶため行われる。外側のループでグリッドサーチ、内側でk分割交差検証の組み合わせた入子式交差検証は5✖️2交差検証法とも呼ばれる。
内側2回のループでグリッドサーチで訓練データを訓練サブセットと検証サブセットに分割してパラメータをチューニングし、外側五回のループで最適なパラメータでk分割交差検証をする。
この実装は以下のように行われる。
from sklearn.tree import DecisionTreeClassifier
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train,
scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores),
np.std(scores)))

ここで、SVMモデルを決定気分類器に変えて行う入子交差検証法は以下のコードで実装できる。
gs = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0),
param_grid=[{'max_depth': [1, 2, 3, 4, 5, 6, 7, None]}],
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train,
scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores),
np.std(scores)))
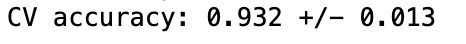
この記事が気に入ったらサポートをしてみませんか?