機械学習:モデル評価とハイパーパラメータのチューニング 学習曲線と検証曲線

学習モデルのパラメータが多すぎる場合、バリアンスが高く過学習に陥り、訓練データと交差検証の正解率に大きな差ができやすい。訓練データを増やせば、過学習は防げるが、計算機負荷が大きくなる。
このトレードオフを見るために、学習曲線と検証曲線を使いモデルを評価する。
データは同じく乳癌データセットを使う。
学習曲線
from sklearn.model_selection import learning_curve
pipe_lr = make_pipeline(StandardScaler(),
LogisticRegression(penalty='l2', random_state=1, solver='lbfgs',max_iter=1000))
train_sizes, train_scores, test_scores = learning_curve(estimator=pipe_lr,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1, 1.0, 10),
cv=10,
n_jobs=1)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
訓練データサイズを、10%から100%まで変えて、交差検証(cv=10)を行い学習曲線を計算する。
結果をグラフ化すると、以下のようになる。
plt.plot(train_sizes, train_mean,
color='blue', marker='o',
markersize=5, label='training accuracy')
plt.fill_between(train_sizes,
train_mean + train_std,
train_mean - train_std,
alpha=0.15, color='blue')
plt.plot(train_sizes, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='validation accuracy')
plt.fill_between(train_sizes,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xlabel('Number of training examples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.8, 1.03])
plt.tight_layout()
plt.show()
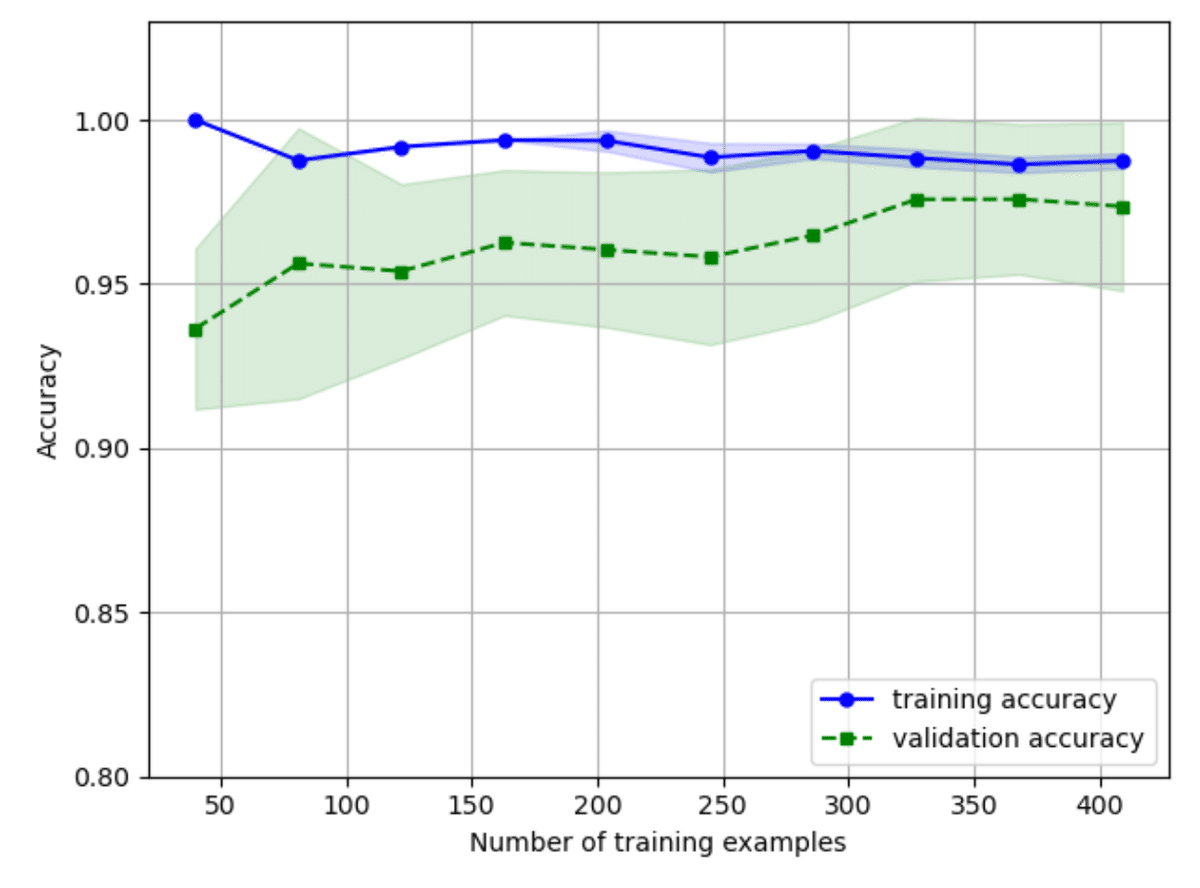
性能が高くても、訓練データと検証データの結果の開きが大きく出ている訓練データサイズ250以下は、過学習の可能性が高い。よって、データサイズは300以上が望ましく、350以上では性能に差がない。
検証曲線
学習曲線は訓練とテストの正解率をサンプルサイズの関数としてプロットしたが、検証曲線はモデルのパラメータの値を変化させ、訓練データとテストデータの正解率を比較する。
ここでは、ロジスティック回帰の逆正則化パラメータのCを変化させる。
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
train_scores, test_scores = validation_curve(
estimator=pipe_lr,
X=X_train,
y=y_train,
param_name='logisticregression__C',
param_range=param_range,
cv=10)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(param_range, train_mean,
color='blue', marker='o',
markersize=5, label='training accuracy')
plt.fill_between(param_range, train_mean + train_std,
train_mean - train_std, alpha=0.15,
color='blue')
plt.plot(param_range, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='validation accuracy')
plt.fill_between(param_range,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xscale('log')
plt.legend(loc='lower right')
plt.xlabel('Parameter C')
plt.ylabel('Accuracy')
plt.ylim([0.8, 1.0])
plt.tight_layout()
plt.show()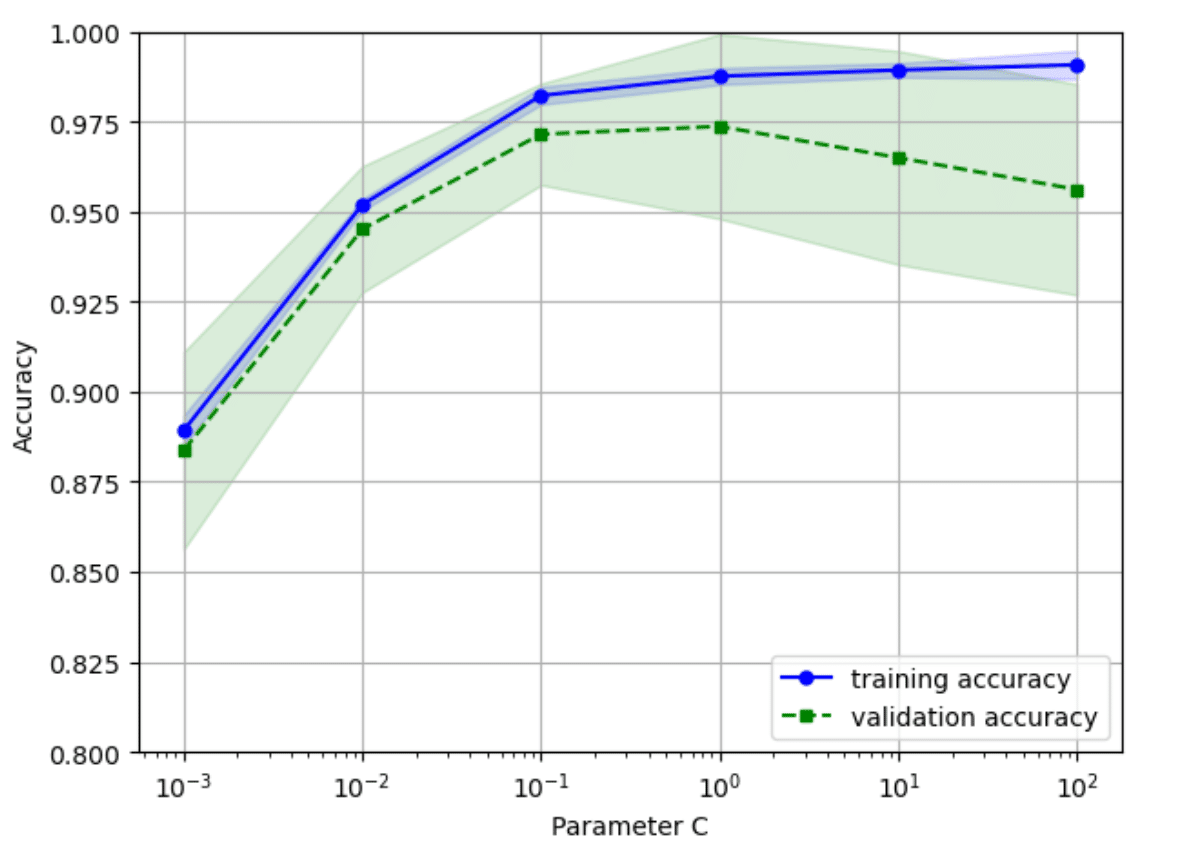
この図から、Cは0.01から0.1間の値が最適となる。
この記事が気に入ったらサポートをしてみませんか?