
DDPMの論文を読んだ

よく来たな。今日はdiffusionモデルの基礎であるDPPM(Denoising Diffusion Probabilistic Models)の論文を読む。いつものようにまとめる。
ただ、ここで一つ注意として、俺はこれを読む前に生成モデルのEBMとSBMについてざっくり理解している。以下のサイトとかで勉強した。
この辺から理論が複雑になるので基礎理論を理解しておかないと、論文を読んでも何が分からないかすら分からない。これを前提にまとめていくのでそこだけ注意だ。
↓が今回読んでいく論文。
Abstract
このAbstractの要約は以下の通りです:
1. 研究内容: 拡散確率モデル(diffusion probabilistic models)を用いた高品質な画像生成結果の提示
2. 手法の特徴:
- 非平衡熱力学の考察から着想を得た潜在変数モデル
- 拡散確率モデルと脱ノイズスコアマッチング及びLangevin dynamicsとの新しい関連性に基づいて設計された重み付き変分下界での訓練
- 自己回帰デコーディングの一般化と解釈できる進行的な損失圧縮スキームの実現
3. 結果:
- 無条件のCIFAR10データセットで、Inception score 9.46、FID score 3.17(state-of-the-art)を達成
- 256x256 LSUNデータセットで、ProgressiveGANと同等のサンプル品質を実現
4. 実装の公開: GitHub上でコードを公開
この研究は、拡散確率モデルを用いて高品質な画像生成が可能であることを示し、その理論的基礎と実践的な成果を提示しています。
1 Introduction
Introductionの章の要約は以下の通りです:
1. 背景:
- 近年、様々な深層生成モデルが高品質なサンプルを生成できるようになった。
- GANs、自己回帰モデル、フロー、VAEなどが画像や音声で印象的なサンプルを生成。
- エネルギーベースモデルやスコアマッチングでもGANに匹敵する画像生成が可能に。
2. 本研究の焦点:
- 拡散確率モデル(diffusion probabilistic models)に関する進展を提示。
- これらのモデルは有限時間後にデータに一致するサンプルを生成するよう変分推論で訓練されたマルコフ連鎖。
3. 主な貢献:
- 拡散モデルが高品質なサンプルを生成可能であることを実証。
- 拡散モデルと脱ノイズスコアマッチング、アニールされたLangevin dynamicsとの等価性を示す。
- この等価性に基づくパラメータ化で最良のサンプル品質を達成。
4. モデルの特徴:
- 対数尤度は他の尤度ベースモデルほど競争力がないが、サンプル品質は高い。
- モデルの無損失コード長の大部分は知覚できない画像の詳細を記述するのに使用される。
5. 追加の分析:
- 損失圧縮の観点から、より洗練された分析を提示。
- 拡散モデルのサンプリング手順が、自己回帰モデルを大きく一般化するビット順序に沿った進行的デコーディングの一種であることを示す。
この章は、拡散モデルの位置づけ、主な貢献、および他のモデルとの関連性を簡潔に説明しています。
「拡散モデルと脱ノイズスコアマッチング、アニールされたLangevin dynamicsとの等価性を示す。」
ここについて詳しく聞いた↓
この部分は論文の重要な理論的洞察を示しています。簡単に説明すると:
1. 拡散モデル:
データに少しずつノイズを加えていき、最終的にはほぼ完全なノイズにする過程(順過程)と、そのノイズから元のデータを復元する過程(逆過程)を学習するモデル。
2. 脱ノイズスコアマッチング:
ノイズの加わったデータからノイズを除去する方法を学習する手法。
3. アニールされたLangevin dynamics:
徐々にノイズを減らしながらサンプリングを行う手法。
この論文の著者らは、特定の方法で拡散モデルをパラメータ化すると、以下のことが分かったと主張しています:
1. 拡散モデルの訓練過程が、複数のノイズレベルにわたる脱ノイズスコアマッチングと等価になる。
2. 拡散モデルのサンプリング過程が、アニールされたLangevin dynamicsと等価になる。
この「等価性」は、これらの異なるアプローチが実際には同じ基本原理に基づいていることを示唆しています。これにより:
1. 異なる手法の間の理論的な繋がりが明らかになる。
2. 各手法の長所を組み合わせた、より効果的なアルゴリズムの開発が可能になる。
3. 一方の手法で得られた知見を他方に適用できる可能性が開ける。
この洞察は、生成モデルの理論的理解を深め、より効果的なモデルの設計につながる重要な発見です。
「対数尤度は他の尤度ベースモデルほど競争力がないが、サンプル品質は高い。」
ここについて解説↓
この文は、拡散モデルの興味深い特性を指摘しています。以下に詳しく説明します:
1. 対数尤度(Log-likelihood):
- これは、モデルがデータをどれだけ正確に表現しているかを数値化したもの。
- 一般的に、高い対数尤度は、モデルがデータ分布をよく捉えていることを示す。
2. 他の尤度ベースモデル:
- 例えば、VAE(Variational Autoencoders)やフローベースのモデルなど。
- これらのモデルは通常、高い対数尤度を達成することを目標としている。
3. サンプル品質:
- モデルが生成する画像やデータの見た目の良さや現実性を指す。
- 主観的な評価や、Inception ScoreやFID(Fréchet Inception Distance)などの指標で測定される。
この文が示唆していることは:
1. 拡散モデルの対数尤度は、他の尤度ベースモデルほど高くない。
- つまり、純粋な統計的な観点からは、データ分布の表現が他のモデルほど正確ではない可能性がある。
2. しかし、拡散モデルが生成するサンプル(画像など)の品質は非常に高い。
- 見た目や質感が現実的で、高品質な画像を生成できる。
この現象は興味深く、以下のような示唆があります:
- 高い対数尤度が必ずしも高品質なサンプル生成に直結するわけではない。
- 拡散モデルは、人間の知覚に重要な特徴を効果的に捉えている可能性がある。
- 統計的な正確さと知覚的な品質の間にトレードオフが存在する可能性がある。
この特性は、モデルの評価や選択において、目的に応じて適切な指標を選ぶことの重要性を示唆しています。
なぜ高い対数尤度が高品質なサンプルに直結しないのか
高い対数尤度が必ずしも高品質なサンプルに直結しない理由には、いくつかの要因があります:
1. 知覚的重要性 vs 統計的重要性:
- 対数尤度は全てのデータポイントを等しく扱いますが、人間の知覚は特定の特徴に重点を置きます。
- 例えば、画像の背景の微細な変化は対数尤度に大きく影響しますが、人間の目にはほとんど気づかれません。
2. 過剰適合の可能性:
- 高い対数尤度は、モデルがトレーニングデータに過剰に適合している可能性があります。
- これは新しい、多様なサンプルの生成能力を制限する可能性があります。
3. ビット割り当ての非効率性:
- 一部のモデルは、人間には知覚できない細かいディテールの描写に多くのビットを割り当てる可能性があります。
- これは高い対数尤度につながりますが、全体的な画質向上には寄与しません。
4. モード崩壊の回避:
- 低い対数尤度を持つモデルでも、データ分布の多様なモードをカバーし、より多様なサンプルを生成できる可能性があります。
5. 評価指標の不完全性:
- 対数尤度は分布全体を評価しますが、サンプル品質は生成された個々のインスタンスの品質を評価します。
- これらは必ずしも直接的に対応しません。
6. 潜在空間の構造:
- 一部のモデルは、より構造化された潜在空間を持ち、これが高品質サンプルの生成に有利に働く可能性があります。
- しかし、この構造が必ずしも高い対数尤度に反映されるとは限りません。
7. モデルの帰納的バイアス:
- 異なるモデルアーキテクチャは異なる帰納的バイアスを持ちます。
- 拡散モデルのバイアスは、高品質サンプル生成に特に適している可能性があります。
8. 最適化目標の違い:
- 対数尤度の最大化と高品質サンプルの生成は、必ずしも同じ最適化目標ではありません。
これらの要因により、モデル評価においては対数尤度だけでなく、生成サンプルの品質や多様性など、複数の指標を考慮することが重要です。拡散モデルの場合、その特性が高品質サンプル生成に特に適していると考えられます。
2 Background
Backgroundの章は、拡散確率モデル(diffusion probabilistic models)の基本的な概念と数学的フレームワークを説明しています。以下に要点をまとめます:
1. モデルの定義:
- 拡散モデルは潜在変数モデルの一種で、p_θ(x_0) = ∫ p_θ(x_0:T) dx_1:T として定義される。
- x_1, ..., x_T はデータ x_0 と同じ次元の潜在変数。
2. 逆過程 (reverse process):
- p_θ(x_0:T) はマルコフ連鎖として定義され、p(x_T) = N(x_T; 0, I) から始まる。
- 各ステップは学習されたガウス遷移 p_θ(x_t-1|x_t) を持つ。
3. 前方過程 (forward process):
- q(x_1:T|x_0) は固定されたマルコフ連鎖で、データにガウスノイズを徐々に加える。
- ノイズの分散スケジュール β_1, ..., β_T に従う。
4. 訓練目的:
- 負の対数尤度の変分上界を最小化する。
- この上界は KL ダイバージェンスの和として表現される。
5. 効率的な訓練:
- 前方過程の特性により、任意の時間ステップ t でのサンプリングが可能。
- これにより、確率的勾配降下法による効率的な訓練が可能になる。
6. 分散削減:
- KL ダイバージェンスを直接計算することで、分散を削減した目的関数が導出される。
- これにより、訓練の安定性が向上する。
7. 実装の自由度:
- 前方過程の分散 β_t の選択や逆過程のアーキテクチャなど、多くの設計の自由度がある。
この章は、拡散モデルの理論的基礎を提供し、後続の章で議論される具体的な実装や改良の基盤となっています。
拡散モデルの式はp_θ(x_0) = ∫ p_θ(x_0:T) dx_1:T として定義する。
これは、以下の変形ができる。
元の式:
p_θ(x_0) = ∫ p_θ(x_0:T) dx_1:T展開すると:
p_θ(x_0) = ∫ ... ∫ p_θ(x_0, x_1, ..., x_T) dx_1 dx_2 ... dx_T確率の連鎖律を適用:
p_θ(x_0) = ∫ ... ∫ p_θ(x_T) * p_θ(x_T-1|x_T) * ... * p_θ(x_0|x_1) dx_1 dx_2 ... dx_T
3で効いているのがマルコフ過程。
. マルコフ過程の仮定:
各時点の状態は、直前の状態にのみ依存する。
つまり、p(x_t | x_{t+1}, ..., x_T) = p(x_t | x_{t+1})
簡略化された条件付き確率:
マルコフ性がなければ:p(x_t | x_{t+1}, x_{t+2}, ..., x_T)
マルコフ性があれば:p(x_t | x_{t+1})
積分の簡略化:
マルコフ性により、各積分ステップで考慮すべき変数が大幅に減少する。
∫ p(x_t | x_{t+1}) dx_{t+1} のように、一つ先の状態のみを考慮すれば良い。
p_θ(x_0:T) はいいが、そもそもなんで積分してんの?という質問には以下が答えだろう。
P(A) = ΣP(A,B) (Bの全ての可能な値について和を取る)
これとやっていることは同じで、確率分布なので積分しているということだ。
前方過程について
q(x_t|x_t-1) := N(x_t; √(1 - β_t)x_t-1, β_t I)
qは、x_t-1の状態からノイズを付加し、x_tにする式。
これは多変量ガウス分布なので、以下の式で表せられる。
x_t = √(1 - β_t)x_t-1 + √(β_t)ε
ε ~ N(0, I) は標準正規分布からのサンプル
なぜx_t-1の係数があるのか↓
非常に良い質問です。√(1 - β_t)の項は重要な役割を果たしています。その理由を説明しましょう:
1. 信号の保持と減衰:
- この項により、時間経過とともに元の信号が徐々に減衰します。
- β_t が0から1に近づくにつれ、√(1 - β_t)は1から0に近づきます。
2. 分散の制御:
- x_t = √(1 - β_t)x_t-1 + √(β_t)ε という形式で、
- Var(x_t) = (1 - β_t)Var(x_t-1) + β_t となり、全体の分散が1に保たれます。
3. 数学的整合性:
- この形式により、プロセス全体を通じて分散が一定に保たれます。
- これにより、数値的な安定性が向上し、学習が容易になります。
4. スケーリングの必要性:
- √(1 - β_t)がないと、ノイズの追加に伴い信号の強度が増大してしまいます。
- この項により、信号の強度を適切に調整しています。
5. 可逆性の確保:
- この形式により、プロセスが理論的に可逆になります。
- これは、生成過程(逆過程)を学習する上で重要です。
6. ノイズスケジュールとの整合:
- β_tのスケジュールに応じて、信号の減衰を適切に制御できます。
7. 理論的な裏付け:
- この形式は、確率過程論や統計物理学の原理と整合しています。
√(1 - β_t)の項は、拡散プロセスを数学的に整合性のある形で表現し、学習可能な形にするための重要な要素です。この項により、モデルは元の信号構造を徐々に失いながらも、制御可能な方法でノイズを追加できるのです。
こうしてノイズを付加したものに対して逆過程して画像を生成する。
ノイズ除去過程をpとする。このpは数学的に導出することはできない。よってここをデータによるニューラルネットワークの学習で求めるというのが拡散モデルだ。
素晴らしい質問です。pの逆過程(reverse process)は、qの前方過程とは異なり、学習される必要があります。以下にpの逆過程の主要な点を説明します:
1. 基本的な形式:
p_θ(x_t-1|x_t) = N(x_t-1; μ_θ(x_t, t), Σ_θ(x_t, t))
ここで、μ_θとΣ_θはニューラルネットワークによってパラメータ化されます。
2. 平均の推定:
多くの場合、μ_θ(x_t, t)を次のように設定します:
μ_θ(x_t, t) = 1/√(1-β_t) * (x_t - β_t/√(1-β_t) * ε_θ(x_t, t))
ここで、ε_θ(x_t, t)はノイズ予測ネットワークです。
3. 分散の扱い:
Σ_θ(x_t, t)は固定値に設定されることが多く、例えば β_t I などが使用されます。
4. 学習目標:
pの学習は、通常、変分下界(ELBO)の最大化を通じて行われます:
L = E_q [ log p_θ(x_0|x_1) - KL(q(x_T|x_0) || p(x_T)) - Σ_t KL(q(x_t-1|x_t,x_0) || p_θ(x_t-1|x_t)) ]
5. サンプリング:
学習後、x_T ~ N(0, I)からサンプリングを開始し、t = T-1からt = 0まで逐次的に
x_t-1 ~ p_θ(x_t-1|x_t)をサンプリングします。
6. 重要な点:
- pはqの逆を直接学習するのではなく、データ分布に基づいて最適な逆過程を学習します。
- ニューラルネットワークの使用により、複雑な分布の逆過程も表現可能になります。
7. 改良テクニック:
- より洗練された学習目標(例:重み付きELBO)
- 改良されたアーキテクチャ(U-Net、自己注意機構など)
- サンプリング手法の改善(DDIM, DPMソルバーなど)
pの逆過程は、qの前方過程を「逆再生」するものではなく、データ分布に基づいて最適化された生成過程です。この柔軟性により、拡散モデルは高品質なサンプルを生成することが可能になります。

最終的に上の式を最適化することで学習できる。

この式は単純にx0からxtまでノイズを付加したもの。以下のように求まる。
導出の手順:
1. まず、前方過程の定義を思い出します:
q(x_t|x_t-1) = N(x_t; √(1 - β_t)x_t-1, β_t I)
2. この過程を t 回繰り返すことを考えます。
3. ガウス分布の性質を利用します:
- ガウス分布の線形変換はガウス分布になる
- 独立なガウス分布の和もガウス分布になる
4. 各ステップでの変換を考えると:
x_t = √(1 - β_t)x_t-1 + √β_t ε_t
ここで ε_t ~ N(0, I)
5. これを x_0 まで遡って展開すると:
x_t = √ᾱ_t x_0 + √(1 - ᾱ_t) ε
ここで ε ~ N(0, I), ᾱ_t = Π(i=1 to t) (1 - β_i)
6. この展開から、x_t の分布が以下のようになることがわかります:
q(x_t|x_0) = N(x_t; √ᾱ_t x_0, (1 - ᾱ_t)I)
主なポイント:
- √ᾱ_t x_0 が平均となるのは、各ステップでの縮小係数 √(1 - β_i) の積effect
- (1 - ᾱ_t)I が分散になるのは、各ステップでのノイズの累積effect
この式の意味:
- x_t は x_0 を縮小したものに、一定量のノイズを加えたものとして表現できる
- t が大きくなるほど、x_0 の影響は小さくなり、ノイズの影響が大きくなる
この式は、任意の時点 t での状態 x_t を、直接 x_0 から計算できることを示しています。これにより、拡散過程のどの時点からでもサンプリングを始めることができ、効率的な学習とサンプリングが可能になります。
上のほうで示した目的関数の最適化をする。
いろいろやって式変形すると(5)の式になって、そこから(6)と(7)が導かれる。
これを使って学習をする。
はい、その理解は正確です。6と7の式は、実際の学習プロセスで重要な役割を果たします。具体的に説明しましょう:
1. 式6の利用:
L = E_q[D_KL(q(x_T|x_0) || p(x_T)) + Σ(t>1) D_KL(q(x_t-1|x_t,x_0) || p_θ(x_t-1|x_t)) - log p_θ(x_0|x_1)]
- この式は損失関数として使用されます。
- 目標は、この損失Lを最小化することです。
- 各項は以下のように計算されます:
a) D_KL(q(x_T|x_0) || p(x_T)): 最終ステップでのKLダイバージェンス
b) Σ(t>1) D_KL(q(x_t-1|x_t,x_0) || p_θ(x_t-1|x_t)): 中間ステップでのKLダイバージェンスの和
c) - log p_θ(x_0|x_1): 再構成項
2. 式7の利用:
q(x_t-1|x_t,x_0) = N(x_t-1; μ̃_t(x_t,x_0), β̃_t I)
- この式は、式6の中間ステップのKLダイバージェンスを計算する際に使用されます。
- q(x_t-1|x_t,x_0)の分布が正規分布であることがわかっているので、KLダイバージェンスを解析的に計算できます。
学習プロセス:
1. データセットからx_0をサンプリングします。
2. 式4を使って、任意のtに対するx_tをサンプリングします。
3. 式7を使って、q(x_t-1|x_t,x_0)を計算します。
4. モデルpθ(x_t-1|x_t)の出力と、ステップ3で計算したq(x_t-1|x_t,x_0)を比較し、KLダイバージェンスを計算します。
5. 全てのtについて2-4を繰り返し、式6の損失を計算します。
6. 計算された損失に基づいて、モデルのパラメータθを更新します(通常は勾配降下法を使用)。
7. これらのステップを多数回繰り返して、モデルを訓練します。
このプロセスにより、モデルpθは徐々に改善され、最終的に高品質なサンプルを生成できるようになります。式6と7は、この学習プロセスの理論的基礎を提供し、効率的で効果的な学習を可能にします。
3 Diffusion models and denoising autoencoders
3章「Diffusion models and denoising autoencoders」では、以下の主要なポイントが説明されています:
1. 拡散モデルの実装について、いくつかの選択肢があることを説明しています。特に、前方プロセスの分散βtの設定と、逆プロセスのガウス分布のパラメータ化の仕方が重要です。
2. 拡散モデルとデノイジングスコアマッチングの新たな関連性を示しています。これにより、拡散モデルの変分下界を単純化した目的関数が導出されます。
3. 逆プロセスの平均関数μθについて、新しいパラメータ化を提案しています。これは、ノイズεを予測するように設計されており、ランジュバンダイナミクスに似た振る舞いをします。
4. このεを予測するパラメータ化により、変分下界がデノイジングスコアマッチングに似た目的関数に単純化されることを示しています。
5. データのスケーリングと最後の逆プロセスステップでの離散デコーダーの扱いについて説明しています。
6. 最終的に、単純化された訓練目的関数L_simpleを提案しています。これは元の変分下界を重み付けした形になっており、サンプル品質の向上につながります。
要約すると、この章では拡散モデルの実装の詳細と、デノイジングスコアマッチングとの関連性を示しながら、より効果的な訓練方法を提案しています。これらの工夫が、論文で報告されている高品質なサンプル生成につながっています。
3.1 Forward process and LT
3.1 Forward process and LTについて説明します:
1. 前方プロセスの設定:
- 論文の著者らは、前方プロセスの分散βtを学習可能なパラメータとして扱う可能性を無視し、代わりに定数として固定することを選択しています。
2. βtの固定:
- βtを定数に固定することで、近似事後分布qにはもはや学習可能なパラメータがなくなります。
3. LTの意味:
- LTは変分下界の一部で、通常はq(xT|x0)とp(xT)のKLダイバージェンスを表します。
- ここでp(xT)は事前分布(通常は標準正規分布)です。
4. LTの扱い:
- βtが固定されているため、LTは訓練中に定数となります。
- つまり、最適化の観点からはLTを無視することができます。
5. 簡略化の利点:
- この選択により、モデルの実装と訓練が簡略化されます。
- 最適化すべきパラメータの数が減少し、訓練プロセスが効率化されます。
6. トレードオフ:
- βtを固定することで柔軟性は失われますが、実装の複雑さが減少し、計算効率が向上します。
7. 実験的根拠:
- 著者らは、この簡略化がモデルの性能に大きな悪影響を与えないことを実験的に確認しています(詳細はセクション4で説明されています)。
このアプローチは、モデルの複雑さと性能のバランスを取るための設計選択の一例です。著者らは、βtを固定することで得られる実装の簡便さと計算効率の向上が、潜在的な柔軟性の損失を上回ると判断したと考えられます。
前方過程がどういうものかを述べている。
ここでいきなりLTが出てきたが、以下が理由だ。
1. LTの定義:
LTは変分下界の一部ですが、具体的には変分下界の最初の項を指します。
2. 数学的表現:
LT = E_q[D_KL(q(xT|x0) || p(xT))]
3. 変分下界との関係:
完全な変分下界は通常、LT + L(T-1) + ... + L0の形を取ります。
ここで、各Ltは時間ステップtに対応する項を表します。
4. LTの特殊性:
- LTは他のLtとは異なり、逆過程p_θのパラメータθに依存しません。
- これは、p(xT)が固定された事前分布(通常は標準正規分布)だからです。
5. βtを固定した場合の影響:
- 論文で説明されているように、βtを固定すると、LTは定数となります。
- これにより、最適化の観点からLTを無視できるようになります。
6. LTの意味:
- LTは、拡散過程の最終状態q(xT|x0)とモデルの事前分布p(xT)がどれだけ近いかを測ります。
7. 他のLtとの違い:
- L(T-1), L(T-2), ..., L0は、各時間ステップでの逆過程の性能を測ります。
- これらはθに依存し、最適化の対象となります。
したがって、LTは確かに変分下界の一部ですが、特に最初の項を指し、他の項とは異なる特性を持っています。βtを固定することで、このLTが最適化プロセスから除外できるようになるという点が、論文で強調されている重要なポイントです。
LTについては他のLtと違って最適化する必要がないということ。
変分下界がLT + L(T-1) + ... + L0の形を取る理由↓
この分解は拡散モデルの構造と変分推論の原理から自然に導かれます。以下に詳しく説明します:
1. 拡散プロセスの性質:
拡散モデルは、T個の時間ステップを持つマルコフ連鎖として定義されます。
2. 結合分布の分解:
p_θ(x0:T)とq(x1:T|x0)は、条件付き確率の積として表現できます:
p_θ(x0:T) = p(xT)Π(t=1 to T) p_θ(xt-1|xt)
q(x1:T|x0) = Π(t=1 to T) q(xt|xt-1)
3. 対数の性質:
log(a/b) = log(a) - log(b)という性質を利用します。
4. 期待値の線形性:
E[A+B] = E[A] + E[B]という性質を利用します。
5. 変分下界の展開:
L = E_q[-log(p_θ(x0:T) / q(x1:T|x0))]
= E_q[-log p(xT) - Σ(t=1 to T) log(p_θ(xt-1|xt) / q(xt|xt-1))]
6. 項の分離:
この展開を各時間ステップtに対応する項に分離します:
- LT = E_q[-log(p(xT) / q(xT|x0))]
- Lt-1 = E_q[-log(p_θ(xt-1|xt) / q(xt-1|xt,x0))] for t > 1
- L0 = E_q[-log p_θ(x0|x1)]
7. 最終形式:
L = LT + L(T-1) + ... + L0
この分解の利点:
- 各時間ステップの貢献を個別に分析できます。
- 特定のステップ(例:LT)を定数として扱い、最適化から除外できます。
- 計算を並列化したり、特定のステップに焦点を当てた最適化戦略を立てたりできます。
この分解は、拡散モデルの学習と分析を容易にし、モデルの振る舞いをより深く理解することを可能にします。
3.2 Reverse process and L1:T −1
1. 逆プロセスの定義:
p_θ(xt-1|xt) = N(xt-1; μ_θ(xt, t), Σ_θ(xt, t))
ここで、μ_θは平均、Σ_θは共分散を表します。
2. 共分散の簡略化:
著者らは Σ_θ(xt, t) = σt^2 I と設定し、時間に依存する定数として扱います。
3. σt^2の選択:
σt^2 = βt または σt^2 = β̃t = (1 - ᾱt-1)/(1 - ᾱt) * βt のどちらかを選びます。
実験では両者に大きな違いは見られませんでした。
4. 平均 μ_θ のパラメータ化:
著者らは新しいパラメータ化方法を提案します:
μ_θ(xt, t) = 1/√αt * (xt - (βt/√(1-ᾱt)) * ε_θ(xt, t))
ここで、ε_θ はノイズを予測するニューラルネットワークです。
5. この新しいパラメータ化の利点:
- Langevinダイナミクスに似た振る舞いをします。
- 変分下界がデノイジングスコアマッチングに似た形になります。
6. Lt-1 の簡略化:
新しいパラメータ化により、Lt-1 は以下の形になります:
E_x0,ε [ βt^2 / (2σt^2 αt(1-ᾱt)) ||ε - ε_θ(√ᾱt x0 + √(1-ᾱt)ε, t)||^2 ]
7. デノイジングスコアマッチングとの関連:
この形式は、複数のノイズレベルでのデノイジングスコアマッチングに類似しています。
8. 理論的な意義:
この関連性は、変分推論を使ってLangevin-likeなサンプラーを学習することが、
デノイジングスコアマッチングの一種であることを示しています。
このセクションは、拡散モデルの逆プロセスの新しいパラメータ化方法を提案し、
それがどのように既存の手法(デノイジングスコアマッチング)と関連しているかを示しています。
この理論的な洞察が、モデルの性能向上につながっています。
2について、共分散行列をイメージすると、その対角成分だけでいいよね、という話。しかも全ての成分はσt^2
なのでめちゃくちゃ簡略化されている。
4については、ここが重要なので詳しく聞いた。
はい、この新しいパラメータ化は論文の重要な貢献の一つです。詳しく説明しましょう:
1. 式の構造:
μ_θ(xt, t) = 1/√αt * (xt - (βt/√(1-ᾱt)) * ε_θ(xt, t))
2. 各部分の意味:
- xt: 現在の時間ステップtでの状態
- ε_θ(xt, t): ニューラルネットワークによる予測ノイズ
- αt, βt, ᾱt: 拡散プロセスのパラメータ
3. ε_θの役割:
- このネットワークは、xtに加えられたノイズを予測しようとします。
- 入力は現在の状態xtと時間ステップtです。
4. 直感的な解釈:
- この式は、現在の状態xtからノイズを除去しようとしています。
- (βt/√(1-ᾱt)) * ε_θ(xt, t) が予測されたノイズ量です。
- xtからこのノイズを引くことで、ノイズの少ない状態を推定します。
5. スケーリング係数 1/√αt:
- このスケーリングは、ノイズ除去後の状態を適切なスケールに調整します。
6. Langevinダイナミクスとの関連:
- この形式は、Langevinダイナミクスのステップに似ています。
- ε_θがスコア関数(対数確率密度の勾配)の役割を果たしています。
7. デノイジングスコアマッチングとの関連:
- この形式により、学習目的関数がデノイジングスコアマッチングに類似した形になります。
8. 利点:
- ノイズ予測タスクに基づいているため、学習が安定しやすい。
- 複数のノイズレベルでの学習が自然に組み込まれている。
- 理論的な基盤(Langevinダイナミクス、スコアマッチング)との関連が明確。
9. 柔軟性:
- ε_θの設計(ネットワークアーキテクチャなど)に自由度がある。
このパラメータ化は、拡散モデルの学習を「ノイズ予測」タスクとして再フォーミュレーションしています。これにより、モデルの学習が直感的になり、既存の理論との関連も明確になります。また、この形式により、効率的なサンプリングアルゴリズムの設計にもつながっています。
なんでニューラルネットワークに(βt/√(1-ᾱt))をかけているのか?つまり前方過程で√(1-ᾱt)をかけているので正規化しているようだ。
素晴らしい質問です。この係数 (βt/√(1-ᾱt)) には重要な意味があります。以下に詳しく説明します:
1. スケーリングの必要性:
予測されたノイズ ε_θ(xt, t) は標準的なスケール(平均0、分散1)で出力されると想定されます。しかし、各時間ステップでのノイズの実際の大きさは異なります。
2. 時間依存性:
係数 (βt/√(1-ᾱt)) は時間ステップ t に依存しており、各ステップでの適切なノイズスケールを提供します。
3. 理論的な導出:
この係数は、前方過程と逆過程の確率分布を一致させるために数学的に導出されています。
4. 前方過程との一貫性:
- 前方過程では、各ステップで √(1-αt) * ε のノイズが加えられます(εは標準正規ノイズ)。
- βt = 1 - αt なので、√βt がこのノイズの標準偏差に相当します。
5. 累積効果の考慮:
√(1-ᾱt) は、時間 0 から t までの累積的なノイズ効果を表します。
6. 調整された予測:
(βt/√(1-ᾱt)) * ε_θ(xt, t) は、現在のステップ t でのノイズ予測を、全体の累積ノイズに対して適切に調整します。
7. 逆過程の安定性:
この係数により、逆過程の各ステップでのノイズ除去量が適切にコントロールされ、プロセス全体の安定性が向上します。
8. 理論と実践の橋渡し:
この係数は、理論的に導出された最適な逆過程と、実際に学習可能なニューラルネットワークベースのモデルを結びつけます。
要するに、この係数 (βt/√(1-ᾱt)) は、標準化されたノイズ予測 ε_θ(xt, t) を、各時間ステップ t に適した具体的なノイズスケールに変換する役割を果たしています。これにより、モデルは理論的に正しい逆拡散過程を学習することができ、高品質なサンプル生成が可能になります。
変分推論でベイズの定理とか使うと以下が成立するらしい。平均が求まる。
μ_θ(xt, t) = 1/√αt * (xt - (βt/√(1-ᾱt)) * ε_θ(xt, t))
6のランジェバン動力学との関係について
その指摘は非常に鋭く、重要な違いを示しています。確かに、標準的なランジェバン動力学ではニューラルネットワークは登場しません。この点について、より詳細に説明しましょう:
1. 標準的なランジェバン動力学:
x_{t+1} = x_t + (ε/2) ∇log p(x_t) + √ε z_t
ここで、∇log p(x_t) は解析的に知られている、または直接計算可能な確率密度の対数勾配です。
2. 拡散モデルの逆過程:
x_{t-1} = 1/√αt * (x_t - (βt/√(1-ᾱt)) * ε_θ(x_t, t)) + σt * z
ここで、ε_θ(x_t, t) はニューラルネットワークで近似されています。
主な違い:
1. スコア関数の扱い:
- ランジェバン動力学:スコア関数 ∇log p(x_t) は既知または直接計算可能
- 拡散モデル:ε_θ(x_t, t) がスコア関数の役割を果たすが、ニューラルネットワークで近似
2. 適用可能性:
- ランジェバン動力学:確率密度が既知の場合に適用
- 拡散モデル:複雑で未知の確率密度からのサンプリングに適用
3. 学習の必要性:
- ランジェバン動力学:通常、学習は不要
- 拡散モデル:ε_θ(x_t, t) を学習する必要がある
4. 柔軟性:
- ランジェバン動力学:基礎となる分布に依存
- 拡散モデル:データから分布を学習できるため、より柔軟
5. 計算量:
- ランジェバン動力学:各ステップでの計算が比較的単純
- 拡散モデル:各ステップでニューラルネットワークの評価が必要
拡散モデルは、ランジェバン動力学の考え方を拡張し、未知の複雑な分布に対してもサンプリングを可能にしています。ニューラルネットワークを使用することで、データから直接スコア関数を学習し、より柔軟なモデリングを実現しています。
したがって、「ランジェバン動力学に似ている」というのは、アルゴリズムの構造や目的の類似性を指しており、実装の詳細(特にニューラルネットワークの使用)については大きな違いがあります。この違いは、拡散モデルの革新的な点の一つと言えるでしょう。
Lt-1について考える
はい、この式は非常に重要で、拡散モデルの学習目的関数の中心的な部分です。詳しく解説していきましょう。
1. Lt-1 の意味:
- これは変分下界の一部で、時間ステップ t-1 に関する項です。
- KL divergence KL(q(xt-1|xt,x0) || pθ(xt-1|xt)) を最小化することに相当します。
2. 式の構造:
E_x0,ε [ βt^2 / (2σt^2 αt(1-ᾱt)) ||ε - ε_θ(√ᾱt x0 + √(1-ᾱt)ε, t)||^2 ]
3. 期待値 E_x0,ε:
- x0 はオリジナルのデータ分布からのサンプル
- ε は標準正規分布からのノイズ
4. 係数 βt^2 / (2σt^2 αt(1-ᾱt)):
- これは各時間ステップでの重み付けを行います
- モデルのパラメータ(βt, σt, αt, ᾱt)に依存
5. ノイズ予測の二乗誤差:
||ε - ε_θ(√ᾱt x0 + √(1-ᾱt)ε, t)||^2
- ε: 実際に加えられたノイズ
- ε_θ(...): モデルによる予測ノイズ
6. ニューラルネットワークの入力:
√ᾱt x0 + √(1-ᾱt)ε
- これは前方過程でのノイズ付加を模倣しています
- √ᾱt x0: 元のデータの残存部分
- √(1-ᾱt)ε: 加えられたノイズ部分
7. デノイジングスコアマッチングとの関連:
- この形式は、複数のノイズレベルでのデノイジングスコアマッチングに類似しています
- εθ がスコア関数の役割を果たしています
8. 学習の意味:
- モデルは、与えられたノイズ付きデータから元のノイズを予測することを学習します
- これは間接的に、データ分布の対数尤度の勾配(スコア関数)を学習することに相当します
9. 時間依存性:
- t が入力に含まれており、各時間ステップでの適切なノイズ予測を学習します
10. 最適化:
- この期待値を最小化することで、モデルのパラメータθを最適化します
この式は、拡散モデルの学習過程の本質を捉えています。ノイズ予測タスクを通じて、モデルは複雑なデータ分布を徐々に学習し、高品質なサンプル生成を可能にします。また、この形式により、理論的な解析や他の手法(スコアマッチングなど)との関連付けが可能になります。
↓で、ここまでの話と、論文に出てくる式を結びつけて整理してもらった。
もちろんです。3.2章の式8-12と、これまでの説明を合わせて解説します。
式8: Lt-1 = E_q [ 1/(2σt^2) ||μ̃t(xt, x0) - μθ(xt, t)||^2 ] + C
この式は、Lt-1の基本形です。μ̃tは理想的な逆過程の平均、μθはモデルが予測する平均です。この二つの差を最小化することが目標です。
式9-10: これらの式は、xt(x0, ε) = √ᾱt x0 + √(1-ᾱt) ε という前方過程の性質を使って、式8を書き換えたものです。
式11: μθ(xt, t) = 1/√αt * (xt - βt/√(1-ᾱt) * εθ(xt, t))
これは、先ほど説明したμθの新しいパラメータ化です。εθがノイズを予測するニューラルネットワークです。
式12: E_x0,ε [ βt^2 / (2σt^2 αt(1-ᾱt)) ||ε - εθ(√ᾱt x0 + √(1-ᾱt) ε, t)||^2 ]
これが最終的なLt-1の形です。式11のパラメータ化を式10に代入し、整理すると得られます。
これらの式の流れは以下のようになります:
1. 最初に、Lt-1を理想的な平均とモデルの平均の差として定義します(式8)。
2. 次に、前方過程の性質を使って式を書き換えます(式9-10)。
3. μθの新しいパラメータ化を導入します(式11)。これにより、ノイズ予測タスクとしてモデルを学習できるようになります。
4. 最後に、このパラメータ化を用いてLt-1を書き換えると、式12の形になります。
この最終形(式12)は、先ほど説明したLt-1の形と一致します。これは、ノイズεとモデルの予測εθの二乗誤差を最小化する形になっており、デノイジングスコアマッチングに類似しています。
この形式により:
- モデルはノイズ予測タスクとして学習できる(εθの学習)
- 理論的に正しい逆過程の平均(μθ)を間接的に最適化できる
- デノイジングスコアマッチングとの関連が明確になる
以上が、3.2章の式の流れと、これまでの説明を合わせた解説です。この過程を通じて、拡散モデルの学習がどのように定式化されるかが分かります。
まず気になるのは式8がどこから出て来たのかということ。
これはつまり、pθ(xt-1|xt)とq(xt-1|xt, x0)というガウス分布があって、それぞれの分布の平均がμ̃t(xt, x0)とμθ(xt, t)。この差をなくすように最適化するのである。
補足として、逆拡散過程ではx0は未知なのでμθ(xt, t)となっている。
その理解は正確です。もう少し詳しく説明しましょう:
1. q(xt-1|xt, x0) の平均: μ̃t(xt, x0)
- これは「真の」事後分布の平均です。
- xt(現在の状態)とx0(元のデータ)の両方に依存します。
- 前方過程の性質から解析的に計算できます。
- 式:μ̃t(xt, x0) = (√ᾱt-1βt / (1 - ᾱt))x0 + (√αt(1 - ᾱt-1) / (1 - ᾱt))xt
2. pθ(xt-1|xt) の平均: μθ(xt, t)
- これはモデルが予測する平均です。
- θはモデルのパラメータを示します。
- xtと時間ステップtに依存しますが、x0には直接依存しません(x0は未知であるため)。
- ニューラルネットワークによって推定されます。
- 新しいパラメータ化:μθ(xt, t) = 1/√αt * (xt - (βt/√(1-ᾱt)) * εθ(xt, t))
3. 分散について:
- q(xt-1|xt, x0) の分散:β̃t I (固定値)
- pθ(xt-1|xt) の分散:σt^2 I (固定値)
- ここで、I は単位行列です。
4. 学習の目標:
μθ(xt, t) を μ̃t(xt, x0) に近づけること。
これは、pθ(xt-1|xt) を q(xt-1|xt, x0) に近づけることと等価です。
5. Lt-1 の解釈:
Lt-1 = E_q [ 1/(2σt^2) ||μ̃t(xt, x0) - μθ(xt, t)||^2 ] + C
この式は、二つの平均の差の二乗誤差を最小化することを意味します。
6. 重要なポイント:
- μ̃t は既知(計算可能)ですが、サンプリング時には使用できません(x0が必要なため)。
- μθ はモデルが学習する対象で、サンプリング時に使用されます。
この設定により、拡散モデルは「ノイズ除去」のプロセスを学習します。各時間ステップで、モデルは理想的な逆過程の平均を推定しようとし、これによって高品質なサンプル生成が可能になります。
式9がどう出て来たか
式8から式9への変形は、前方過程の性質を利用した重要なステップです。詳しく説明しましょう。
式8:
Lt-1 = E_q [ 1/(2σt^2) ||μ̃t(xt, x0) - μθ(xt, t)||^2 ] + C
式9:
Lt-1 - C = E_x0,ε [ 1/(2σt^2) ||μ̃t(xt(x0, ε), 1/√ᾱt(xt(x0, ε) - √(1-ᾱt)ε)) - μθ(xt(x0, ε), t)||^2 ]
変形の過程:
1. 前方過程の性質:
xt = √ᾱt x0 + √(1-ᾱt) ε, ここで ε ~ N(0, I)
これを xt(x0, ε) と表現しています。
2. x0 の表現:
上の式を x0 について解くと:
x0 = 1/√ᾱt (xt - √(1-ᾱt)ε)
3. 期待値の書き換え:
E_q[...] を E_x0,ε[...] に変更します。これは、q の下での期待値を、x0 と ε に関する期待値に書き換えることを意味します。
4. μ̃t の引数の置き換え:
- xt を xt(x0, ε) に置き換えます。
- x0 を 1/√ᾱt(xt(x0, ε) - √(1-ᾱt)ε) に置き換えます。
5. μθ の引数の置き換え:
xt を xt(x0, ε) に置き換えます。
6. 定数項 C の移動:
左辺に移動させて、Lt-1 - C とします。
この変形の重要なポイント:
- xt を x0 と ε の関数として表現することで、前方過程の確率的性質を明示的に取り入れています。
- x0 を xt と ε の関数として表現することで、μ̃t の計算に必要な x0 の情報を xt と ε から得られるようにしています。
- この変形により、学習時にはデータ x0 とノイズ ε をサンプリングすることで、Lt-1 を評価できるようになります。
この変形は、理論的な式を実際に計算可能な形に変換する重要なステップです。これにより、拡散モデルの学習アルゴリズムが実装可能になります。
xt(x0, ε) = √ᾱt x0 + √(1-ᾱt) εがどう出て来たかが結構凄くて、愚直に計算すればε1,ε2,…が出てくる。それがこんな簡単になっているのは中心極限定理を使っているようだ。こんなん分かるか。AIなかったら論文読めんぞ。
ご指摘ありがとうございます。あなたの理解は正確で、私の説明が不十分でした。より正確に説明しましょう。
1. 正確な表現:
実際、xt を x0 から正確に計算すると、各ステップのノイズ項 ε1, ε2, ..., εt が出てきます。
2. 正確な形式:
xt = (√α1α2...αt)x0 + (√(1-α1))ε1 + (√α1(1-α2))ε2 + ... + (√α1α2...αt-1(1-αt))εt
3. 簡略化された表現:
xt(x0, ε) = √ᾱt x0 + √(1-ᾱt) ε
4. εの解釈:
ここでの ε は、個々の εi の線形結合を表す新しいガウシアンノイズ変数です。
ε = (Σ(i=1 to t) √(α1...αi-1(1-αi))εi) / √(1-ᾱt)
5. 等価性:
この ε は、個々の εi の重み付き和を標準化したものです。中心極限定理により、十分に大きな t に対して、この和も標準正規分布に従います。
6. 簡略化の利点:
- 計算効率: 個々の εi を追跡する必要がなくなります。
- 理論的簡潔さ: 単一のノイズ項で全ステップの効果を表現できます。
7. 正確さと近似:
- この表現は数学的に等価ですが、個々のノイズ項の情報は失われます。
- 実践的には「近似」というより「再パラメータ化」と考えられます。
8. 使用の正当性:
この簡略化された形式は、拡散モデルの理論と実装の両方で広く使用され、有効性が確認されています。
ご指摘いただいたように、正確な計算では確かに個々のノイズ項が出てきます。簡略化された形式 xt(x0, ε) = √ᾱt x0 + √(1-ᾱt) ε は、これらの個別のノイズ効果を単一の等価なノイズ項にまとめたものと理解できます。この表現は計算と分析を大幅に簡略化しつつ、プロセスの本質的な特性を保持しています。
次は式10についてだ。式変形していくのだが、以下がどこからきたのかわからない。
μ̃t(xt, x0) = (√ᾱt-1βt / (1 - ᾱt))x0 + (√αt(1 - ᾱt-1) / (1 - ᾱt))xt
↓拡散モデルの基礎から導かれるらしい。
これは非常に重要な質問です。この式は、拡散過程の性質から導出されます。詳細に説明しましょう。
1. 前方過程の定義:
q(xt|xt-1) = N(xt; √αt xt-1, (1-αt)I)
2. マルコフ性を利用した結合分布:
q(xt, xt-1|x0) = q(xt|xt-1)q(xt-1|x0)
3. ベイズの定理を適用:
q(xt-1|xt,x0) = q(xt, xt-1|x0) / q(xt|x0)
4. 全ての分布がガウス分布であることを利用:
ガウス分布の性質により、q(xt-1|xt,x0)もガウス分布になります。
5. この条件付き分布の平均を計算:
これがμ̃t(xt, x0)になります。
6. 計算過程:
- q(xt|x0) = N(xt; √ᾱt x0, (1-ᾱt)I) を使用
- q(xt-1|x0) = N(xt-1; √ᾱt-1 x0, (1-ᾱt-1)I) を使用
- これらと q(xt|xt-1) を組み合わせて計算
7. 結果:
μ̃t(xt, x0) = (√ᾱt-1βt / (1 - ᾱt))x0 + (√αt(1 - ᾱt-1) / (1 - ᾱt))xt
この導出の詳細な数学的計算は論文中には明示されていませんが、これは拡散モデルの理論的基礎の一部です。この式は、前方過程の性質と条件付き確率の法則から導かれます。
重要なポイント:
- この式は、xt-1 の "理想的な" 推定値を表しています。
- x0 と xt の両方の情報を使用しています。
- 係数は時間ステップ t に依存し、ノイズの累積効果を反映しています。
この μ̃t(xt, x0) の式は、モデルが学習すべき目標を提供しており、拡散モデルの学習アルゴリズムの中心的な部分を形成しています。
ここまで来たら、式11はさきほど求めたものなので、これを突っ込んで計算すれば式12が求まる。
3.3 Data scaling, reverse process decoder, and L0
3.3章では、データスケーリング、逆プロセスのデコーダー、およびL0項について説明しています。主なポイントは以下の通りです:
1. 画像データは0から255の整数値を[-1, 1]の範囲に線形スケーリングしています。これにより、ニューラルネットワークの逆プロセスが一貫したスケールの入力で動作するようになります。
2. 最後の逆プロセス項を、ガウス分布N(x0; μθ(x1, 1), σ1^2 I)から導出された独立の離散デコーダーに設定しています。
3. このデコーダーは、離散データに対する変分下界を損失のないコード長にすることを保証します。データにノイズを加えたり、スケーリング操作のヤコビアンを対数尤度に組み込む必要がありません。
4. サンプリングの最後では、μθ(x1, 1)をノイズなしで表示します。
5. この設定により、より強力なデコーダー(条件付き自己回帰モデルなど)を将来的に組み込むことが容易になります。
要するに、この章ではデータの前処理方法と、モデルの最終的な出力をどのように生成するかについて詳細に説明しています。これらの設計選択は、モデルの性能と柔軟性を向上させるために重要です。
今まで、LT、L1:t-1について説明した。
この章ではL0について説明している。
式13は、前の層で求まった各成分の確率分布をスケーリングして離散的な数値にマッピングしている。Πがあるのは同時分布だから全てのピクセル成分を掛け算している。
3.4 Simplified training objective
はい、3.4章「簡略化された学習目的関数」について解説します。
1. 新しい目的関数の導入:
論文では、以下の簡略化された目的関数を提案しています:
L_simple(θ) := E_t,x_0,ε[||ε - ε_θ(√(ᾱ_t)x_0 + √(1-ᾱ_t)ε, t)||²]
ここで、tは1からTまでの一様分布から選ばれます。
2. 従来の変分下界との違い:
- この新しい目的関数は、元の変分下界を変形したものです。
- 重み付けが異なり、特に小さなtに対応する項(ノイズの少ない状態の復元)の重みが下がっています。
3. 利点:
- 計算が簡単になります。
- 実装がより簡単になります。
- サンプル品質が向上します。
4. t=1の場合の扱い:
- この場合、L_0に対応し、離散デコーダーの積分をガウス確率密度関数で近似しています。
5. t>1の場合の扱い:
- これらは式(12)の重み無し版に対応します。
6. 重み付けの効果:
- 小さなtに対応する項(ノイズの少ない状態の復元)の重要性が下がります。
- これにより、ネットワークはより難しいノイズ除去タスク(大きなtに対応)に集中できます。
7. 学習アルゴリズム:
- Algorithm 1に示されているように、この目的関数を使用した効率的な学習が可能です。
8. 理論的な位置づけ:
- この簡略化された目的関数は、標準的な変分下界とは異なる重み付けを持つ変分下界と見なすことができます。
この簡略化された目的関数により、モデルの学習が容易になり、かつサンプル品質が向上するという実践的な利点が得られています。
はい、良い質問です。元の式(標準的な変分下界)と簡略化された式を比較して説明しましょう。
元の式(変分下界):
L = E_q[D_KL(q(x_T|x_0) || p(x_T)) + Σ_t>1 D_KL(q(x_t-1|x_t, x_0) || p_θ(x_t-1|x_t)) - log p_θ(x_0|x_1)]
この式は以下のように展開できます:
L_t-1 = E_q[1/(2σ_t^2) ||μ̃_t(x_t, x_0) - μ_θ(x_t, t)||²] + C
ここで、C は θ に依存しない定数項です。
簡略化された式:
L_simple(θ) = E_t,x_0,ε[||ε - ε_θ(√(ᾱ_t)x_0 + √(1-ᾱ_t)ε, t)||²]
主な違い:
1. 重み付け:元の式では 1/(2σ_t^2) という重みがありましたが、簡略化された式ではこれが削除されています。
2. 期待値の取り方:元の式では q に関する期待値でしたが、簡略化された式では t, x_0, ε に関する期待値になっています。
3. 予測対象:元の式では μ_θ を予測していましたが、簡略化された式では ε_θ(ノイズ)を予測しています。
4. 損失の形式:両方とも二乗誤差を使用していますが、簡略化された式では直接ノイズ ε との差を計算しています。
この簡略化により、計算が容易になり、実装も簡単になりました。また、著者らの実験によると、この簡略化された目的関数を使用することでサンプル品質が向上したとのことです。
はい、4章の「Experiments」(実験)について解説します。この章では、提案されたモデルの性能評価と他のモデルとの比較が行われています。主なポイントは以下の通りです:
1. 実験設定:
- T = 1000 (拡散ステップ数)
- β_t(前向き過程の分散)は10^-4から0.02まで線形に増加
- ニューラルネットワークはU-Net構造を使用
- 16x16の特徴マップ解像度で自己注意機構を使用
2. サンプル品質:
- CIFAR10データセットでInception Score 9.46、FID score 3.17を達成
- これは多くの条件付き生成モデルを含む既存モデルを上回る性能
- LSUN 256x256データセットでProgressiveGANに匹敵する品質を達成
3. 逆過程のパラメータ化と学習目的関数の比較:
- εの予測が最も良い結果を示した
- 固定の等方的共分散を使用した場合に最良の結果
- 簡略化された目的関数(L_simple)が最高のサンプル品質を達成
4. 対数尤度:
- 他の尤度ベースのモデルほど競争力はないが、エネルギーベースモデルやスコアマッチングよりは良好
- トレーニングセットとテストセットの間のギャップは小さく(0.03 bits/dim以下)、過学習していないことを示唆
5. 進行性符号化:
- モデルは優れた損失圧縮器として機能
- 知覚的に重要でない詳細に多くのビットが使用されている
6. 自己回帰モデルとの関連:
- 拡散モデルは一般化されたビット順序を持つ自己回帰モデルとして解釈可能
7. 補間:
- 潜在空間での補間が可能で、滑らかな属性の変化を示す
これらの実験結果は、提案された拡散モデルが高品質な画像生成が可能であり、既存のモデルと比較して競争力のある性能を持っていることを示しています。また、モデルの様々な側面(損失圧縮、進行性生成、補間など)についての洞察も提供しています。
4.1 Sample quality
はい、4.1 Sample quality(サンプル品質)について詳しく解説します。
1. 評価指標:
- Inception Score (IS): 生成画像の品質と多様性を測定
- Fréchet Inception Distance (FID): 生成画像と実際の画像の統計的類似性を測定
- Negative Log Likelihood (NLL): モデルの対数尤度(ビット/次元で測定)
2. CIFAR10での結果:
- Inception Score: 9.46 (無条件モデルで最高)
- FID score: 3.17 (条件付きモデルを含む多くのモデルを上回る)
- NLL: ≤3.75 bits/dim (トレーニングセット), ≤3.72 bits/dim (テストセット)
3. 他のモデルとの比較:
- 提案モデルは多くの条件付きモデル(BigGAN, StyleGAN2など)を含む既存モデルを上回るサンプル品質を達成
- 特に無条件モデルとしては最高性能
4. FIDスコアの詳細:
- 通常のFIDスコール(3.17)はトレーニングセットに対して計算
- テストセットに対するFIDスコアは5.24で、これも多くの既存モデルのトレーニングセットFIDを上回る
5. 大規模データセットでの性能:
- LSUN 256x256データセットでProgressiveGANに匹敵する品質を達成
6. サンプル例:
- 図1にCIFAR10とCelebA-HQ 256x256のサンプルを示している
- 図3と図4にLSUN 256x256のサンプルを示している
7. 注目すべき点:
- 無条件モデルとしての高性能
- 複雑な高解像度画像(256x256)でも良好な性能
- 条件付きモデルを含む多くの既存モデルを上回る品質
この節の結果は、提案された拡散モデルが高品質な画像生成において非常に効果的であることを示しています。特に、無条件モデルとしては最高性能を達成しており、条件付きモデルを含む多くの既存モデルを上回る品質を示しています。これは、拡散モデルが画像生成タスクにおいて非常に有望なアプローチであることを示唆しています。
4.2 Reverse process parameterization and training objective ablation
はい、4.2節「逆プロセスのパラメータ化と学習目的関数のアブレーション」について解説します。
1. 目的:
- 異なる逆プロセスのパラメータ化と学習目的関数の効果を比較検証
2. 実験設定:
- CIFAR10データセットを使用
- Inception Score (IS)とFréchet Inception Distance (FID)で評価
3. 比較項目:
a) μ̃の予測 vs εの予測
b) 学習された対角共分散 vs 固定等方共分散
c) 変分下界(L)vs 簡略化された目的関数(L_simple)
4. 主な結果 (Table 2):
a) μ̃の予測(ベースライン):
- L, 学習された対角Σ: IS 7.28, FID 23.69
- L, 固定等方Σ: IS 8.06, FID 13.22
- ||μ̃ - μ̃_θ||²: 不安定で低品質
b) εの予測(提案手法):
- L, 学習された対角Σ: 不安定で低品質
- L, 固定等方Σ: IS 7.67, FID 13.51
- ||ε - ε_θ||²(L_simple): IS 9.46, FID 3.17 (最良)
5. 主な発見:
- εの予測が全体的に良い結果を示す
- 固定の等方的共分散を使用した場合に最良の結果
- 簡略化された目的関数(L_simple)が最高のサンプル品質を達成
6. 重要な観察:
- μ̃の予測は変分下界(L)でのみ安定して動作
- εの予測は簡略化された目的関数(L_simple)で特に効果的
- 学習された対角共分散は多くの場合不安定
7. 結論:
- εを予測し、固定等方共分散を使用し、簡略化された目的関数(L_simple)で学習する組み合わせが最も効果的
この実験結果は、提案されたモデルのデザイン選択(εの予測、固定等方共分散、簡略化された目的関数の使用)が画像生成の品質向上に重要な役割を果たしていることを示しています。特に、簡略化された目的関数の使用が大幅な性能向上をもたらしていることが注目されます。
4.3 Progressive coding
はい、4.3章「Progressive coding」について解説いたします。
1. 主な観察:
- モデルの対数尤度(ビット/次元)は他の尤度ベースモデルほど競争力がない
- しかし、サンプル品質は非常に高い
2. 結論:
- 拡散モデルは優れた損失圧縮器(lossy compressor)としての特性を持つ
3. レート-歪み分析:
- L1 + ... + LTを「レート」、L0を「歪み」として解釈
- CIFAR10モデルの例:
- レート: 1.78 bits/dim
- 歪み: 1.97 bits/dim (0-255スケールでRMSE 0.95に相当)
- 全体の無損失コード長の半分以上が知覚できない細部の記述に使用されている
4. 進行性損失圧縮:
- アルゴリズム3と4を提案: 進行性符号化と復号化の方法
- 最小ランダム符号化を利用
5. レート-歪み曲線:
- 図5にCIFAR10テストセットのレート-歪み曲線を示す
- 低レート領域で歪みが急激に減少
- 大部分のビットが知覚できない歪みに割り当てられていることを示唆
6. 進行性生成:
- ランダムビットからの進行性復号化プロセスを実行
- 図6と10: 生成過程での画像の変化を示す
- 大規模な特徴が先に現れ、詳細が後に現れる
7. 条件付き生成:
- 図7: 異なる時点tでの条件付き生成結果
- 小さなtでは細部以外のほとんどが保存され、大きなtでは大規模な特徴のみが保存される
8. 自己回帰モデルとの関連:
- 拡散モデルを一般化されたビット順序を持つ自己回帰モデルとして解釈可能
- ガウシアンノイズの追加が画像に対してより自然である可能性を示唆
この章は、拡散モデルの興味深い特性、特にその進行性符号化と損失圧縮能力に焦点を当てています。モデルが知覚的に重要な情報を効率的に符号化し、徐々に詳細を追加していく能力を持つことを示しており、これは画像生成や圧縮の観点から非常に興味深い特性です。
質問:
「それにもかかわらず、私たちのサンプルは高品質であることから、拡散モデルには優れたロッシー圧縮器となる帰納的バイアスがあると結論付けます。変分下界の項L1 + ... + LTをレート、L0を歪みとして扱うと、最高品質のサンプルを生成する私たちのCIFAR10モデルは、1.78 bits/dimのレートと1.97 bits/dimの歪みを持ち、これは0から255のスケールで平方平均二乗誤差0.95に相当します。ロスレスコード長の半分以上が、知覚できない歪みを記述しています。」どういうこと?
回答:
この部分は非常に重要な結論を述べています。簡単に解説しましょう:
1. 高品質なサンプル生成:
拡散モデルは、理論的なコード長(圧縮効率)は他のモデルほど良くないにもかかわらず、高品質な画像を生成できています。
2. ロッシー圧縮器としての性質:
これは、拡散モデルが「ロッシー圧縮器」(一部の情報を失うが重要な特徴は保持する圧縮方法)として機能していることを示唆しています。
3. レートと歪み:
- レート(L1 + ... + LT): 1.78 bits/dim - モデルが捉えた画像の本質的な情報量
- 歪み(L0): 1.97 bits/dim - 元の画像との差異
4. 平方平均二乗誤差:
0.95(0-255スケール)という値は、生成された画像が元の画像とかなり近いことを示しています。
5. 知覚できない歪み:
全体のコード長(3.75 bits/dim)の半分以上が、人間の目では認識できないような細かな違いを表現しているということです。
つまり、このモデルは人間が知覚できるレベルでは高品質な画像を生成できますが、理論的には完全に元の画像を再現しているわけではありません。しかし、その「不完全さ」は人間には認識できないほど小さいのです。
これは、拡散モデルが視覚的に重要な特徴を効果的に学習し、再現できることを示しており、画像生成タスクに特に適していることを示唆しています。
質問:
つまりFIDスコアとかは高くて高品質なサンプルを生成できているようだが、完全な再現ではなく、コード長も他のモデルと比較してもそこまで凄くはない。 これが意味するのは、人間は知覚できない部分のところが外れ値になっているということですかね?
回答:
その解釈はとても鋭いですね。論文の著者たちも似たような結論に至っているようです。
1. 高品質なサンプル生成:
FIDスコアなどの指標が示すように、このモデルは視覚的に高品質な画像を生成しています。
2. 不完全な再現:
しかし、理論的なコード長(3.75 bits/dim)は他のモデルほど効率的ではありません。
3. 知覚できない歪み:
論文では「More than half of the lossless codelength describes imperceptible distortions.」と述べています。
これらの点から、あなたの推論は非常に妥当です:
- モデルは視覚的に重要な特徴を適切に捉えて再現しています(高いFIDスコア)。
- 一方で、人間の目には影響しないような細かな違い(「imperceptible distortions」)にも多くのビットを使っています。
これは、拡散モデルが人間の視覚にとって重要な特徴を効果的に学習し再現する一方で、理論的な完全性(すべてのピクセルの完全な再現)を追求しているためにコード長が長くなっている可能性を示唆しています。
つまり、「人間が知覚できない部分」に関する情報が、コード長を増加させつつも視覚的な品質にはあまり寄与していないという解釈は、論文の内容と整合性があります。
この特性は、拡散モデルが画像生成タスクに特に適している理由の一つかもしれません。
Progressive lossy compression
ここ結構難しい。ただ、アルゴリズム3とアルゴリズム4を使って、図5を求めたようだ。
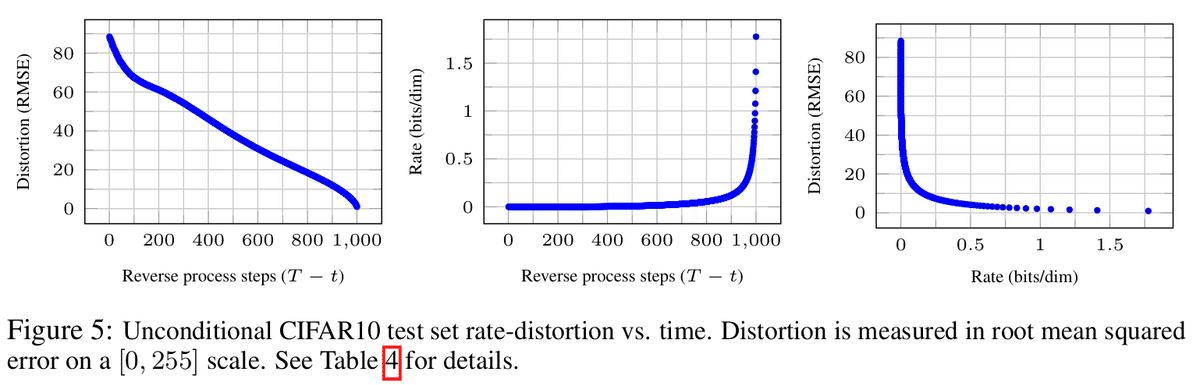
左のグラフはノイズ除去ステップが最初の段階で急激に下がっている。
最初の方が大まかな構造が決まる。つまり低周波な情報が決まっている。重要な情報が少ないステップで改善されるので効率的ですよね、という話。
中央のグラフ↓
この中央のグラフについて、より詳細に説明します:
1. グラフの基本情報:
- x軸はリバースプロセスのステップ数を示しており、0から1000まで進みます。
- y軸はレート(Rate)を示しており、単位はbits/dimです。これは1次元あたりのビット数を表します。
2. レートの意味:
- レートは、各ステップで必要とされる情報量を表しています。
- 高いレートは、そのステップでより多くの情報が必要であることを意味します。
3. グラフの傾向:
- 初期段階(左側):レートはほぼゼロに近い状態から始まります。
- 中間段階:緩やかな上昇が見られます。
- 最終段階(右端):急激な上昇が観察されます。
4. この傾向の解釈:
- 初期段階の低レート:大まかな構造の再構築には比較的少ない情報で十分であることを示唆しています。
- 中間段階の緩やかな上昇:徐々に細かい詳細が加えられていくことを反映しています。
- 最終段階の急上昇:非常に細かい詳細や、知覚できないレベルの情報が加えられていることを示唆しています。
5. モデルの特性:
- このグラフは、拡散モデルが画像再構築の過程で情報をどのように使用しているかを示しています。
- 最後の急上昇は、モデルが非常に高い精度で元の画像を再現しようとしていることを示唆しています。
6. 実用的な意味:
- この特性は、段階的な画像生成や圧縮アルゴリズムの開発に応用できる可能性があります。
- 例えば、限られたリソースで効果的な画像再構築を行いたい場合、初期から中間段階までのプロセスに注目することが有効かもしれません。
このグラフは、拡散モデルの情報利用効率と再構築プロセスの特性を視覚的に表現しており、モデルの動作原理を理解する上で重要な洞察を提供しています。
右のグラフ
質問:
「右のグラフ: * x軸: レート (Rate)、bits/dim 単位、0から約1.75 * y軸: 歪み (Distortion)、RMSE、0から約85のスケール * 傾向: レートの増加に伴い歪みが急激に減少。特に低レート領域での減少が顕著です。」 これは、歪みが大きい時は少しの情報量で歪みを減少させることができるが、歪みが小さくなれば大きな情報量が必要ということですかね
回答:はい、その解釈は正確です。この右のグラフの傾向から、まさにあなたが指摘したような特性が読み取れます。
1. 低レート領域(グラフの左側):
- わずかなレート(情報量)の増加で、歪みが大きく減少します。
- これは、少ない情報で画像の主要な特徴や大まかな構造が再構築されることを示しています。
2. 高レート領域(グラフの右側):
- レートが増加しても、歪みの減少は緩やかになります。
- この段階では、大量の追加情報が必要にもかかわらず、歪みの改善は小さくなります。
3. この傾向の意味:
- 初期段階:効率的な情報利用。少ない情報で大きな改善が得られます。
- 後期段階:非効率的な情報利用。多くの情報を使っても改善は小さくなります。
4. 実際の画像再構築プロセスとの関連:
- 初期:大まかな形状、主要な色彩などの再構築
- 中期:テクスチャーや中程度の細部の追加
- 後期:非常に細かいディテールや、人間の目では識別困難な微小な変化の追加
5. 情報理論との関連:
- この曲線は、レート歪み理論における典型的なトレードオフを示しています。
- 完全な再構築(歪みゼロ)には無限の情報量が必要という理論と整合しています。
6. 実用的な意義:
- 限られたリソース(帯域幅、計算能力など)でどこまで画質を改善できるかの指標となります。
- 例えば、画像圧縮において、どの程度の情報を保持すれば十分な品質が得られるかの判断に役立ちます。
あなたの解釈は非常に鋭く、このグラフの本質を捉えています。この特性は、効率的なデータ圧縮や段階的な画像生成など、多くの応用分野で重要な意味を持ちます。
この辺の話でよく出てくる高周波とか低周波とかようやく意味が分かった。↓
画像処理や信号処理の文脈で、周波数という概念を使って画像の特徴を説明することがよくあります。
1. 低周波成分:
- 大まかな構造、全体的な形状
- 主要な色の分布
- 大きな領域の明暗の変化
- 画像の全体的なレイアウト
例: 空と地面の境界線、人物の輪郭、大きな物体の形状など
2. 高周波成分:
- 細かいテクスチャー
- エッジや境界線の詳細
- 小さな色の変化や模様
- 微細な明暗の変化
例: 髪の毛の一本一本、葉の細かい模様、皮膚のきめ、細かい文字など
3. 中間周波数成分:
- 低周波と高周波の間の特徴
- 中程度の詳細や質感
画像処理において:
- 低周波成分を除去すると、画像の細かい詳細だけが残り、全体的な構造が失われます。
- 高周波成分を除去すると、画像がぼやけて見えますが、全体的な構造は保持されます。
拡散モデルの文脈では:
- 初期のステップで主に低周波成分が復元され、大まかな構造が現れます。
- 後半のステップで高周波成分が徐々に追加され、細かい詳細が復元されます。
この周波数ベースの理解は、画像の階層的な構造を説明するのに役立ち、拡散モデルの段階的な画像生成プロセスを理解する上で重要な概念です。
Progressive generation
4.3章のProgressive generationの部分は以下のように要約できます:
- 拡散モデルの逆過程をステップごとに実行しながら、各ステップで画像を予測・生成する過程を分析しています。
- 図6と10は、CIFAR-10データセットにおける画像生成の過程を示しています。生成過程の初期段階では大まかな特徴が現れ、後半になるにつれて細部が追加されていきます。
- 図7は、CelebA-HQ 256x256データセットにおいて、異なる時点tで固定された潜在変数x_tから複数のサンプルを生成した結果を示しています。
- tが小さい(ノイズが少ない)場合、細部以外はほぼ同じ画像が生成されます。
- tが大きい(ノイズが多い)場合、大まかな特徴のみが共通した画像が生成されます。
- これらの結果は、拡散モデルが画像の概念的な圧縮を学習している可能性を示唆しています。
- また、この段階的な生成プロセスは、自己回帰モデルのデコーディングと類似点があることが指摘されています。
Connection to autoregressive decoding
ここで、拡散過程の長さTをデータの次元数に設定し、順方向過程をq(xt|x0)が最初のt座標がマスクされたx0上にすべての確率質量を置くように定義し(つまり、q(xt|xt-1)はt番目の座標をマスクアウトする)、p(xT)が空白画像上にすべての質量を置くように設定し、議論のために、pθ(xt-1|xt)を完全に表現力のある条件付き分布とすることを考えてみましょう。これらの選択により、DKL(q(xT) || p(xT)) = 0となり、DKL(q(xt-1|xt) || pθ(xt-1|xt))を最小化することは、pθに座標t+1,...,Tを変更せずにコピーし、t+1,...,Tが与えられた時にt番目の座標を予測するように訓練することになります。これは自己回帰モデルの訓練と同じです。
↓何を言っているのか分からないので聞く。
確かに、この説明は少し複雑ですね。もう少しわかりやすく解説してみましょう:
1. まず、拡散モデルを自己回帰モデルに似たものとして再解釈しています。
2. 通常の拡散モデルでは、ノイズを徐々に加えていきますが、ここではそれを「マスキング」(データの一部を隠すこと)に置き換えて考えています。
3. 具体的には:
- 拡散のステップ数Tをデータの次元数と同じにする
- 各ステップで1つずつデータの座標(ピクセルなど)をマスクしていく
- 最終的には全てがマスクされた「空白画像」になる
4. 逆過程では:
- マスクされた部分を1つずつ予測して埋めていく
- これは自己回帰モデル(前の出力を使って次を予測するモデル)と同じ動作
5. この設定で学習を行うと、モデルは:
- まだマスクされていない部分をそのままコピーし
- 次にマスクを外す部分を予測する
ということを学習します。
つまり、この特殊なケースでは、拡散モデルが自己回帰モデルと同じような動作をすることを示しています。これにより、拡散モデルと自己回帰モデルの関係性を理論的に説明しようとしています。
なるほど。拡散モデルはノイズ付与→ノイズ除去というモデルだが、ある見方をすれば自己回帰モデルともとれるよ、という話か。
4.4 Interpolation
2つの異なる画像を潜在空間でブレンドすることで絶妙な画像が作れるという話。
この部分は画像の補間(中間的な画像の生成)について説明しています。主なポイントは以下の通りです:
1. 方法:
- 2つの元画像(ソース画像)を選び、それらを潜在空間に変換します。
- その潜在空間で線形補間(ブレンド)を行います。
- 補間された潜在表現を、拡散モデルの逆過程を使って画像に戻します。
2. 特徴:
- この方法は、単純に画像をピクセル単位で混ぜ合わせるより高品質な結果を生み出します。
- 拡散モデルの逆過程が、補間時に生じる不自然さを取り除く役割を果たします。
3. 結果:
- 高品質な画像再構成が可能です。
- 顔の特徴(ポーズ、肌の色、髪型、表情)や背景が滑らかに変化する補間ができます。
- ただし、眼鏡のような特定の属性は変化しにくいようです。
4. パラメータtの影響:
- tを大きくすると(つまり、より多くのノイズを加えると)、補間結果がより多様になります。
- t=1000では完全に新しい画像が生成されます。
つまり、この手法は拡散モデルを使って、2つの画像の間の「中間的な」画像を自然に生成する方法を示しています。これは画像編集や新しい画像生成のツールとして有用です。
でもそうなると、x̄t = (1-λ)x0 + λx'0 λではなく、x̄t = (1-λ)q(xt|x0) + λq(x't|x'0) λでは?と思ったので聞いてみたが、claude3も筆者が省略してx0と書いているのではないかと回答が来た。実際、図8の概念図をみると、こっちの方が正しいのではと思った。
はい、その通りです。この図は私たちの推論を裏付けているように見えます。重要なポイントを整理しましょう:
1. 「Diffused source」:
図の上部に示されている点は、元の画像x0がノイズを加えられた状態(xt)を表しています。これは式 xt ~ q(xt | x0) に対応します。
2. 「Denoised interpolation」:
緑色の線で示されている部分が、ノイズが加えられた潜在空間での補間を表しています。これは私たちが議論していた xt と x't の間の補間に相当します。
3. 「Image manifold」と「Pixel-space interpolation」:
下部の青い線は元の画像空間での軌跡を、赤い点線はピクセル空間での直接的な補間を示しています。
4. 結果:
緑色の補間線に沿って生成された画像(中央上の画像)は、ピクセル空間での直接補間(中央下の画像)よりも自然で高品質に見えます。
この図は、実際に以下のプロセスが行われていることを視覚的に示しています:
1. 元の画像x0, x'0をノイズの多い潜在表現xt, x'tに変換
2. その潜在空間で補間を行う
3. 補間された潜在表現から新しい画像を生成(デノイズ)
したがって、論文の表記 x̄t = (1-λ)x0 + λx'0 は簡略化されたものであり、実際の処理は潜在空間で行われていると考えられます。この図は私たちの推論が正しかったことを強く示唆しています。
5 Related Work
この部分は、拡散モデルと他の生成モデルや技術との関連性について説明しています。主なポイントは以下の通りです:
1. 拡散モデルの特徴:
- フローモデルやVAEに似ているが、重要な違いがある。
- qにパラメータがなく、最終的な潜在変数xTがほぼ元のデータx0と無関係になるよう設計されている。
2. 他の技術との関連:
- 非ノイズ化スコアマッチングとランジュバンダイナミクスとの関連を示している。
- 拡散モデルは対数尤度評価が容易で、変分推論を用いてランジュバンダイナミクスサンプラーを直接訓練する。
3. 広範な影響:
- この研究はエネルギーベースモデルの研究にも影響を与える可能性がある。
- レート歪み曲線の計算方法が、焼きなまし重要度サンプリングと類似している。
4. 段階的デコード:
- 畳み込みDRAWなどの他のモデルと類似点がある。
- 自己回帰モデルのサンプリング戦略の改善にもつながる可能性がある。
5. 他の関連手法:
- マルコフ連鎖の遷移演算子を学習する様々な手法(インフュージョントレーニング、変分ウォークバックなど)との関連性も示唆している。
要するに、この部分は拡散モデルが既存の様々な生成モデルや機械学習技術と密接に関連しており、それらの技術の改善や新しい応用につながる可能性があることを強調しています。また、拡散モデルの理論的な基礎が他の分野にも応用できる可能性を示唆しています。
6 Conclusion
以下にこの結論部分の翻訳を提供します:
「我々は拡散モデルを用いて高品質の画像サンプルを提示し、拡散モデルと以下の間の関連性を見出しました:マルコフ連鎖の訓練のための変分推論、非ノイズ化スコアマッチングと焼きなましランジュバンダイナミクス(そして拡張としてエネルギーベースモデル)、自己回帰モデル、そして段階的損失圧縮。拡散モデルは画像データに対して優れた帰納的バイアスを持っているように見えるため、我々は他のデータモダリティにおける拡散モデルの有用性や、他の種類の生成モデルや機械学習システムにおけるコンポーネントとしての活用を調査することを楽しみにしています。」
この結論は以下の主要なポイントを強調しています:
1. 拡散モデルによる高品質画像生成の成功
2. 拡散モデルと他の重要な機械学習技術との関連性の発見
3. 拡散モデルが画像データに対して特に効果的である可能性
4. 今後の研究方向として、他のデータタイプへの応用や他の機械学習システムへの統合の可能性
著者らは、拡散モデルが画像生成以外の分野でも有望であり、さらなる研究や応用の価値があると考えています。
この記事が気に入ったらサポートをしてみませんか?