
X(旧Twitter)スクレイピング+Google Driveアップロード《Python》

こういうネットの知恵袋的な記事を書くのは初めてですが、お役に立てたら幸いです。
作ったきっかけ
毎夜毎夜Twitterで設定を投下し、あまつさえ書籍やサイトにまとめないというコンテンツを自分は追っているのですが……
Twitterの検索は漏れが出たり、引用の文章は検索ワードに引っかからなったり(件のコンテンツはほぼファンの質問に答える形なので凄い困る)、最近ではAPI制限なんか付けられたので無料ユーザーだとすぐに制限が来たり・・・
TwitterAPIが無料で利用できていた頃は検索ツールを作ってくれていた方がいたのですが、API有料化と共に更新を辞めてしまいました。
それならと自動ツイート収集くらいなら出来るかな、と軽い気持ちで始めました。
コード
ほぼ受け売りなので、早速載せていきます。
作った時は公開するつもり無かったので、参考にしたサイトは覚えてません……すみません。
スクレイピングについての疑義も他の記事で沢山言われているのでそっちで確認してください(そっちの方が分かりやすいので)。
import abc
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
import time
import pandas as pd
from selenium.webdriver.chrome import service as fs
from selenium.webdriver.common.by import By
import json
import re
from operator import itemgetter, truediv
import os
import sys
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import os.path
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from googleapiclient import errors
from googleapiclient.http import MediaFileUpload
# If modifying these scopes, delete the file token.json.
SCOPES = ["https://www.googleapis.com/auth/drive"]
FILE_ID_ON_DRIVE="GoogleDriveのテキストファイルID"
my_id = "検索で使うTwitterのアカウントID"
my_ps = "↑のアカウントのパスワード"
# 検索画面でスクレイピングするか
search_on = True
page_url = 'Twitterの検索画面のURL'
twitter_id = "検索対象のアカウント"
file_path = "./data/" + twitter_id + ".json"
# 0で全てのツイートを取得
scroll_count = 0
scroll_wait_time = 2
preloaded=[]
quitFlag=False
new_exist = True
getcount=0
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
def get_tweet(twitter_id):
global quitFlag
global preloaded
# 対象ページURL
target_url = ''
account_url = 'https://twitter.com/' + twitter_id
if search_on:
target_url = page_url
else:
target_url = account_url
id_list = []
tweet_list = []
# ヘッドレスモードでブラウザを起動
options = Options()
#options.add_argument('--headless')
# ブラウザーを起動
driver_path = R"ブラウザの実行ファイルのアドレス→\chromedriver.exe"
chrome_service = fs.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
#driver = webdriver.Chrome(service=chrome_service,options=options)
if(not os.path.exists(file_path)):
open(file_path, encoding='utf-8',mode='w').close()
else:
with open(file_path, encoding='utf-8') as f:
tweet_list= json.load(f)
for d in tweet_list:
id_list.append("https://"+d["link"])
preloaded=id_list.copy()
# ログイン
if search_on:
login_twitter(driver,my_id,my_ps)
driver.get(page_url)
# articleタグが読み込まれるまで待機(最大15秒)
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.TAG_NAME, 'article')))
# 指定回数スクロール
s_cnt = 0
while(True if scroll_count == 0 else scroll_count > s_cnt):
s_cnt += 1
id_list, tweet_list = get_article(account_url, id_list, tweet_list, driver)
# 新規ツイート終了
if quitFlag==True:
break;
# スクロール=ページ移動
if scroll_to_elem(driver) == 0:
time.sleep(scroll_wait_time)
id_list, tweet_list = get_article(account_url, id_list, tweet_list, driver)
break
# ○秒間待つ(サイトに負荷を与えないと同時にコンテンツの読み込み待ち)
time.sleep(scroll_wait_time)
# ブラウザ停止
driver.quit()
tweet_list.sort(reverse=True,key=itemgetter('datetime'))
return tweet_list
last_elem = ''
def scroll_to_elem(driver):
global last_elem
# 最後の要素の一つ前までスクロール
elems_article = driver.find_elements(by=By.TAG_NAME,value='article')
# 新しいツイートが現れなくなったら最後の要素を確認して終了
if last_elem == elems_article[-2]:
last_elem = elems_article[-1]
actions = ActionChains(driver);
actions.move_to_element(last_elem);
actions.perform();
return 0
last_elem = elems_article[-2]
actions = ActionChains(driver);
actions.move_to_element(last_elem);
actions.perform();
def get_info_of_article(data,driver):
soup = BeautifulSoup(data, features='lxml')
elems_a = soup.find_all("a")
# 名前
name = elems_a[1].text
# id
id = elems_a[2].text
# リンク
link = 'twitter.com'+ elems_a[3].get("href")
# 投稿日時
datetime = elems_a[3].find("time").get("datetime")
#さらに表示
if(soup.find("div", attrs={"dir":"ltr","data-testid":"tweet-text-show-more-link"})!=None):
before_handle=driver.current_window_handle
before_handles = driver.window_handles
before_len = len(driver.window_handles)
driver.switch_to.new_window("tab")
WebDriverWait(driver, 10).until(lambda d: len(d.window_handles) > before_len)
after_handles = driver.window_handles
newhandle = set(after_handles).difference(set(before_handles)).pop()
driver.switch_to.window(newhandle)
driver.get('https://'+link)
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.TAG_NAME, 'article')))
elems_article = driver.find_elements(by=By.TAG_NAME,value='article')
_tag = elems_article[0].get_attribute('innerHTML')
soup = BeautifulSoup(_tag, features='lxml')
elems_a = soup.find_all("a")
# 投稿
tweets = soup.find_all("div", attrs={"dir":"auto","data-testid":"tweetText"})
content = tweets[0].text if len(tweets) > 0 else ''
# 引用
quote = ""
if len(tweets)>1:
quote = tweets[1].text
driver.close()
driver.switch_to.window(before_handle)
else:
# 投稿
tweets = soup.find_all("div", attrs={"dir":"auto","data-testid":"tweetText"})
content = tweets[0].text if len(tweets) > 0 else ''
# 引用
quote = ""
if len(tweets)>1:
quote = tweets[1].text
info = {}
#info["user_id"] = id
#info["user_name"] = name
info["link"] =link
info["datetime"] = datetime
info["content"] = content
if quote:
info["quote"]={"content" : quote}
return info
def get_article(url, id_list, tweet_list, driver):
global preloaded
global quitFlag
global getcount
global new_exist
elems_article = driver.find_elements(by=By.TAG_NAME,value='article')
for elem_article in elems_article:
tag = elem_article.get_attribute('innerHTML')
elems_a = elem_article.find_elements(by=By.TAG_NAME,value='a')
# 非表示ツイート
if len(elems_a) == 0:
continue
tweet_user = elems_a[1].get_attribute("href")
tweet_link = ""
if tweet_user == url:
# tweet
tweet_link = elems_a[3].get_attribute("href")
# 以前に取得済み
if tweet_link in preloaded:
quitFlag=True
if getcount == 0:
new_exist=False
break
else:
if tweet_link in id_list:
#print("重複")
continue
# tweet情報取得
info = get_info_of_article(tag,driver)
id_list.append(tweet_link)
tweet_list.append(info)
getcount+=1
print(f"\r\033[K%d"% len(tweet_list), end="")
return id_list, tweet_list
def login_twitter(driver, account, password):
# ログインページを開く
driver.get('https://twitter.com/login/')
# メールアドレスorユーザーIDを入力する
WebDriverWait(driver, 60).until(EC.visibility_of_element_located((By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div/div/div/div[5]/label/div/div[2]/div/input')))
driver.find_element(By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div/div/div/div[5]/label/div/div[2]/div/input').send_keys(account)
# 次へボタンをクリックする
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div/div/div/div[6]/div')))
driver.find_element(By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div/div/div/div[6]/div').click()
# パスワードを入力する
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div[1]/div/div/div[3]/div/label/div/div[2]/div[1]/input')))
driver.find_element(By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div[1]/div/div/div[3]/div/label/div/div[2]/div[1]/input').send_keys(password)
# ログインボタンをクリックする
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div[2]/div/div[1]/div/div/div/div')))
driver.find_element(By.XPATH, '/html/body/div/div/div/div[1]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div[2]/div/div[1]/div/div/div/div').click()
time.sleep(5);
if __name__ == '__main__':
# tweet情報をlist型で取得
print('collecting tweets of the target...\n')
tweet_list = get_tweet(twitter_id)
if new_exist == False:
print('There is no new one.\n')
os.system('PAUSE')
sys.exit()
# データフレームに変換
df = pd.DataFrame(tweet_list)
# jsonとして保存
print('\nSaving the data as json.\n')
data = json.loads(df.to_json(orient='records'))
with open(file_path, 'w', encoding='UTF-8') as f:
json.dump(data, f, indent=2,ensure_ascii=False)
creds = None
# The file token.json stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first
# time.
if os.path.exists("token.json"):
creds = Credentials.from_authorized_user_file("token.json", SCOPES)
# If there are no (valid) credentials available, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
"credentials.json", SCOPES
)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open("token.json", "w") as token:
token.write(creds.to_json())
print('trying to update the data on cloud.\n')
try:
service = build("drive", "v3", credentials=creds)
# First retrieve the file from the API.
file = service.files().get(fileId = FILE_ID_ON_DRIVE).execute()
# File's new metadata.
#file['title'] = new_title
#file['description'] = new_description
#file['mimeType'] = new_mime_type
del file['id']
# File's new content.
media_body = MediaFileUpload(file_path,mimetype="application/json",resumable=True)
# Send the request to the API.
updated_file = service.files().update(
fileId=FILE_ID_ON_DRIVE,
body=file,
media_body=media_body).execute()
print('completed.\n')
os.system('PAUSE')
except HttpError as error:
# TODO(developer) - Handle errors from drive API.
print(f"An error occurred: {error}")
きったないコードでごめんなさい!(コメント残さない癖なので……)
頑張って解説します。
main関数
それぞれの機能をまとめて管理しています。
tweet_list = get_tweet(twitter_id)
でツイートデータのリストを受け取り、データフレーム→jsonに変換、一応ローカルに保存し、その後GoogleDrive上のテキストファイルに「上書き」アップロードしています。
GoogleDrive操作は後で説明します。
get_tweet関数
ツイート取得機能をまとめています。
・Selenuimというブラウザ操作フレームワークを使用してChrome(シークレットモード)を起動
・Twitterにログイン
・スクレイピングしたいページ(ホーム画面や基本的には検索画面)に移動
・自動でスクロール+スクレイピング
・ブラウザを終了してツイートデータを返す
という流れで行っています。
# ヘッドレスモードでブラウザを起動
options = Options()
#options.add_argument('--headless')
ヘッドレスモードとはブラウザを新しいウィンドウで立ち上げず、内部で操作するモードで、操作によってウィンドウをアクティブ(ウィンドウをクリックした時に最前面に出てくるアレ)にしないなどの利点があります(実行中は結構邪魔)
自分はエラーなどが発生した時分かりやすいようにこの機能は切っていますが、2024/4/13現在、ログインに画像認証を求められたので、ヘッドレスモードでログインできない時はこれが原因かもしれません。
login_twitter関数
ブラウザで最初にTwitterログイン画面を開き、ログイン操作を行います。
WebDriverWait は「(タイムアウト時間内に)指定した要素が現れるまで待機」する機能です。
ここではTwitter IDやパスワード記入のテキストエリアを指定しています。
driver.find_element().send_keys() で指定したテキストエリアに引数で渡したテキストを挿入し、
driver.find_element().click() で「次へ」や「ログイン」ボタンをクリックしています。
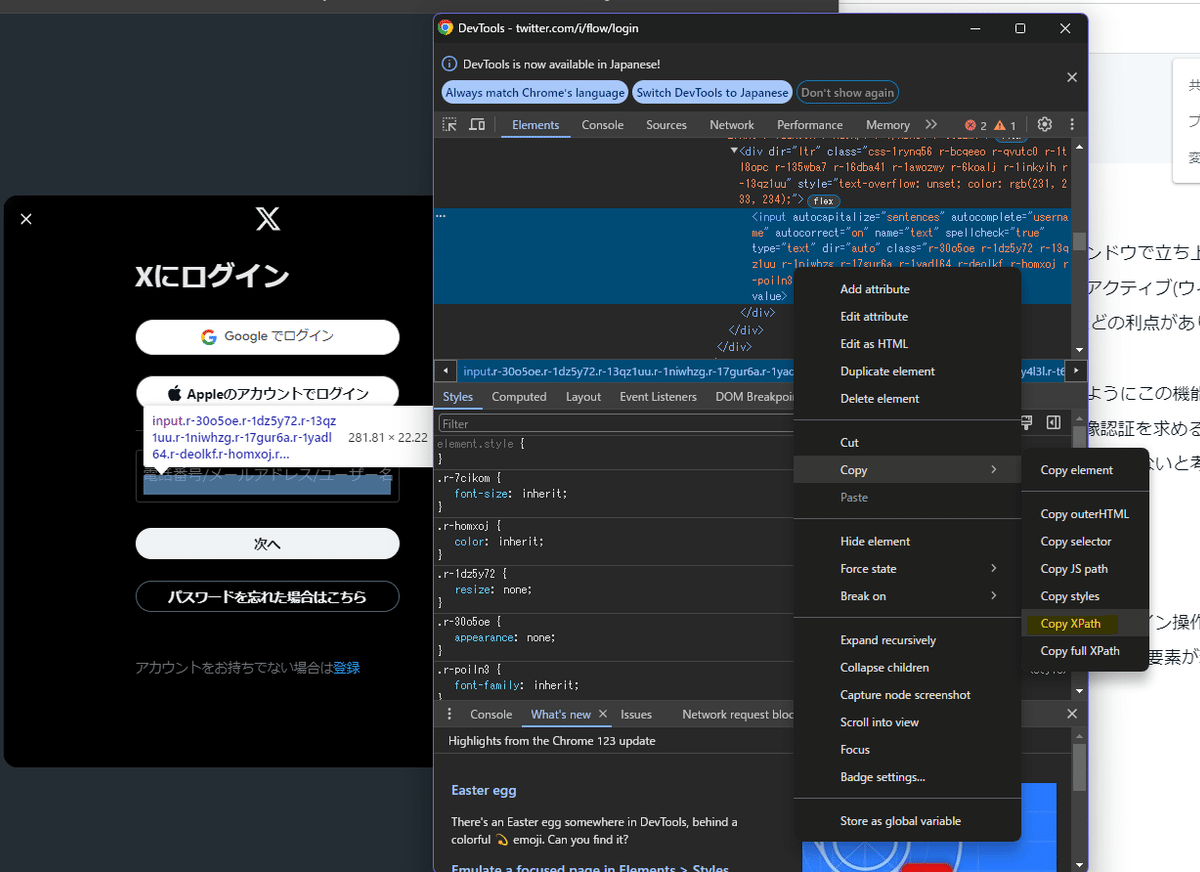
DevToolで一発で取れるので便利です。

飽きたのでそのうち更新します
Python上からGoogleAPIを操作する方法
https://zenn.dev/spacegeek/articles/45270323b1d2bc

Google APIを有効にし、クライアントファイルをダウンロードする。
この記事が気に入ったらサポートをしてみませんか?