【Python初心者】トラックの貨物輸送量を予測してみた

物流業界の市場規模は年々拡大し、近年では新型コロナウィルスの影響もあり、その需要は増加傾向にあります。
今回はその物流業界の中で、トラック輸送に焦点を当て、その貨物輸送量を予測したいと思います。
実行環境
Microsoft Edge
Google Colaboratory
Python 3.7.13
データ説明
使用するデータは、政府統計のポータルサイトであるe-Statにある「自動車輸送統計調査」の3-1貨物輸送量になります。
自動車輸送統計調査は、国内で輸送活動を行う自動車を対象とする統計調査で、国の重要な統計調査として毎月実施しています。
期間は、2007年8月~2022年2月
CSV形式にて抜き出したデータは以下になります。
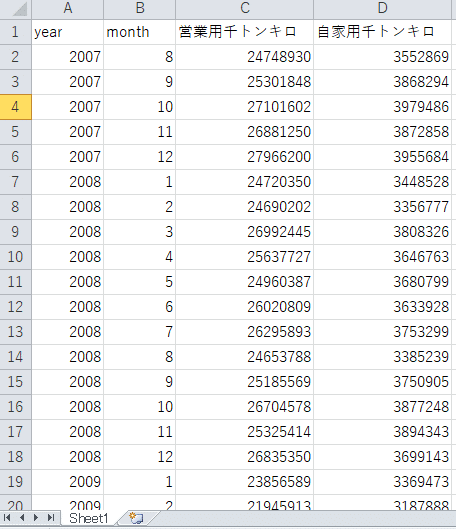
上記データにある”トンキロ”とは、貨物輸送量を表す単位のことです。貨物の重量(t)にそれぞれの貨物の輸送距離(km)を乗じて算出します。
また、営業用と自家用のデータがありますが、これらは営業用(事業用)トラック、自家用トラックの事を指します。
営業用トラックは、「お客様の貨物」を有償で運ぶために使用するトラックの事です。
自家用トラックは、「自分の貨物」を運ぶために使用するトラックの事です。
データ前処理
まず、使用するモジュールを先にインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import statsmodels.api as sm
import itertools次にデータを加工していきます。
df = pd.read_csv("/content/drive/MyDrive/data/data.csv", encoding="shift-jis")
df = df.drop(range(0, 41))
df = df.drop(["year", "month"], axis=1)
index = pd.date_range("2011-01-31", "2022-02-28", freq="M")
df.index = index
df1 = df.drop("自家用千トンキロ", axis=1)
df2 = df.drop("営業用千トンキロ", axis=1)
print(df1.head())
print(df2.head())使用するデータのうち、2010年10月以降はそれ以前とは調査方法が異なるため、前後で値にかなり差が出てしまっています。そのため、2011年1月以降のデータを使用します。※2010年10月~12月のデータは使用するデータと同じ調査方法ですが、念のため除いています。
出力結果

まずdrop関数にて、2010年12月までのデータ、そしてyear,monthの列を削除しています。Pandasのdata_range()にて時系列データを月末単位で生成し、それをインデックスとして設定しています。最後に「営業用千トンキロ」と「自家用千トンキロ」のデータに分け、それぞれdf1、df2としています。出力結果は、df1とdf2の先頭5行を表しています。
データの可視化
データ前処理で加工したデータを可視化し、その傾向を見ていきます。
import statsmodels.api as sm
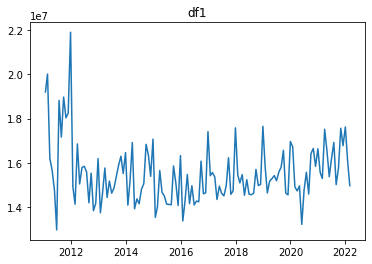
plt.plot(df1)
plt.title("df1")
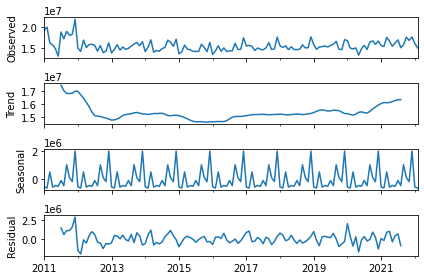
df1_tsdata = sm.tsa.seasonal_decompose(df1["営業用千トンキロ"])
fig1 = df1_tsdata.plot()
plt.show()
plt.plot(df2)
plt.title("df2")
df2_tsdata = sm.tsa.seasonal_decompose(df2["自家用千トンキロ"])
fig2 = df2_tsdata.plot()
plt.show出力結果
【営業用千トンキロ】
【自家用千トンキロ】
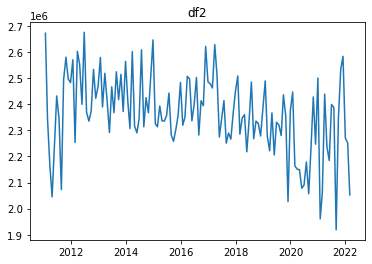
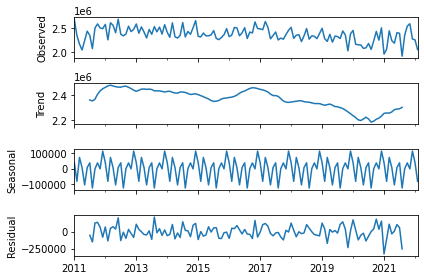
出力結果では、 StatsModelsのtsa.seasonal_decompose()を使用し、それぞれのデータのOvserved(原系列)、Trend(トレンド成分)、Seasonal(季節変動)、Residual(残差)を表しています。
両方のデータのSeasonalに注目すると、同じ形のグラフを毎年繰り返していることが分かります。このことから、これらのデータは季節周期を持っていると判断できます。
よって、予測にはSARIMAモデルを用います
SARIMAモデルとは、端的に言うとARIMAモデルをさらに季節周期を持つ時系列データにも拡張できるようにしたモデルです。
ARIMAモデルとは、ARモデル(自己回帰モデル)とMAモデル(移動平均モデル)からなるARMAモデルへ原系列を階差系列に変換し適応したものになります。
モデル構築
SARIMAモデルの構築にあたって、まずパラメータの決定を行います。SARIMAモデルのパラメータは(p, d, q)(sp, sd, sq, s)で構成されています。
pは自己相関度、dは誘導、qは移動平均、sは周期になります。sp,sd,sqに関しては、sの周期をp,d,qに適用させたものといったイメージになります。
各パラメータ(s以外)は以下のコードにて決定しています。SARIMAモデルのBIC(ベイズ情報量基準)を計算し、BICが最も低くなった場合を表示するようになっています。BICの値が低いほど、パラメータは適切という事になります。また周期については、12か月周期の季節変動を持つデータと判断し、s=12としています。
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]
best_params1 = selectparameter(df1, 12)
best_params2 = selectparameter(df2, 12)
print(best_params1)
print(best_params2)出力結果 [(1, 1, 1), (0, 1, 1, 12), 3713.559309097234]
[(0, 0, 0), (0, 1, 0, 12), 3265.2018605507997]
出力結果より、df1のパラメータは(1,1,1)(0,1,1,12)、df2のパラメータは(0,0,0)(0,1,0,12)が最適であることが分かりました。
これを基にSARIMAモデルの構築を行います。
SARIMA_df1 = sm.tsa.statespace.SARIMAX(df1, order=(1, 1, 1), seasonal_order=(0, 1, 1, 12)).fit()
SARIMA_df2 = sm.tsa.statespace.SARIMAX(df2, order=(0, 0, 0), seasonal_order=(0, 1, 0, 12)).fit()df1のSARIMAモデルをSARIMA_df1、df2をSARIMA_df2としています。
予測結果とその可視化
構築したモデルを使い、実際に予測、そしてその可視化を行っていきます。最後に精度を確かめるために、今回は2013年1月~2022年2月までの予測を行います。
pred1 = SARIMA_df1.predict("2013-01-31", "2022-02-28")
pred2 = SARIMA_df2.predict("2013-01-31", "2022-02-28")
plt.plot(df1)
plt.plot(pred1, color="r")
plt.title("df1")
plt.show()
plt.plot(df2)
plt.plot(pred2, color="r")
plt.title("df2")
plt.show()出力結果
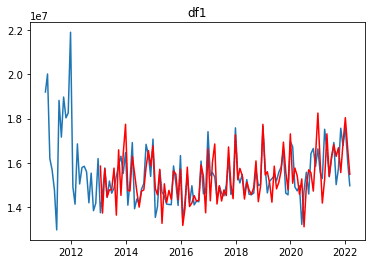
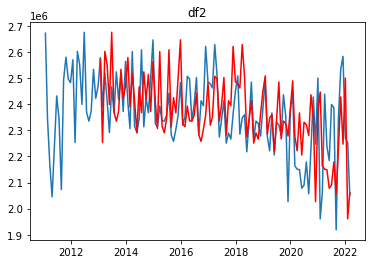
青の折れ線が元データ、赤が予測結果になります。
予測精度評価
最後に予測した結果がどれぐらい正確であるかを評価してみます。今回は、MAPEという評価指標を使用します。
MAPEとは、平均絶対誤差率(Mean Abusolute Percentage Error)と言い、以下の式で表されます。
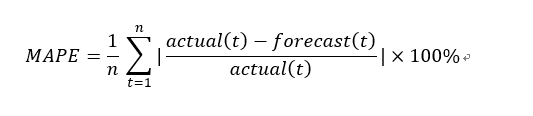
上記の式を今回のデータに当てはめ、Pythonにて計算します。
df1_result = np.mean(np.abs((df1["営業用千トンキロ"][24:] - pred1 ) / df1["営業用千トンキロ"][24:])) * 100
df2_result = np.mean(np.abs((df2["自家用千トンキロ"][24:] - pred2) / df2["自家用千トンキロ"][24:])) * 100
print(df1_result)
print(df2_result)出力結果
4.000300946001734
4.734285956911619
以上から、「営業用千トンキロ」の予測結果には約4%の誤差、「自家用千トンキロ」の予測結果には約5%の誤差があることが分かります。予測精度としては、悪くは無いのではと思っています。また、今回のデータに、貨物輸送量に影響を与える特徴量を追加することができれば、さらに精度の高い結果を出すことができると考えています。
まとめ
Pythonの学習を始めて3か月程度の初心者ですので、間違っている点や説明不足なところが多々あると思います。学習の節目ということもあり今回こういった形でアウトプットさせていただきました。今後も学習を重ね、より高度な分析ができるよう日々精進していきます。
この記事が気に入ったらサポートをしてみませんか?