
「ありきたりさ」を定式化してみたら2021年最もありきたりだった曲を発見できた話

こんばんは、二階からラグランジュです。
音楽を聞いていると、「どこかで聞いたことある歌詞だなあ」なんて思うことありませんか?
今回は、2021年ヒット曲トップ50(上半期)の中で、「歌詞のありきたりさ」を、定量化してみようという企画です!
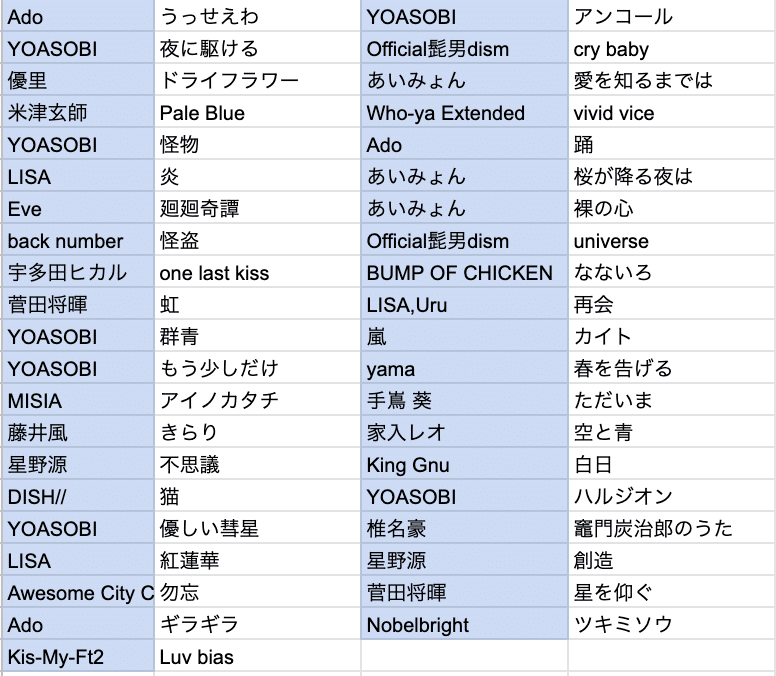
対象とする曲は以下の通りです(歌詞の大半を英語が占める曲は除外)。
考え方
歌詞は単語の集合体なので、「単語のありきたりさ」を算出して、その平均値を取ることで、「歌詞全体のありきたりさ」とすることにします。
$$
①歌詞全体のありきたりさ = \\その歌詞に出現する単語のありきたりさの合計 / その歌詞に出現する単語の種類数
$$
では、「単語のありきたりさ」はどのように算出しましょうか。
「ありきたり」とはすなわち、色んな歌詞に出現するような単語を指しますね。逆に「ありきたりでない」とは、その歌詞にしか出現しないような特徴的な単語でしょう。
この考えの基、以下の式で定義することにします。
$$
②単語のありきたりさ = 1 / その単語が出現する歌詞の数
$$
こんなケースを考えてみましょう。
3つの歌詞があって、それぞれ、1がついている単語から構成されているとします。
例えば、歌詞Aは「君」「私」「いつか」の3単語のみで成り立っているという読み方です。
3つの歌詞の中でどれが1番ありきたりでしょう?
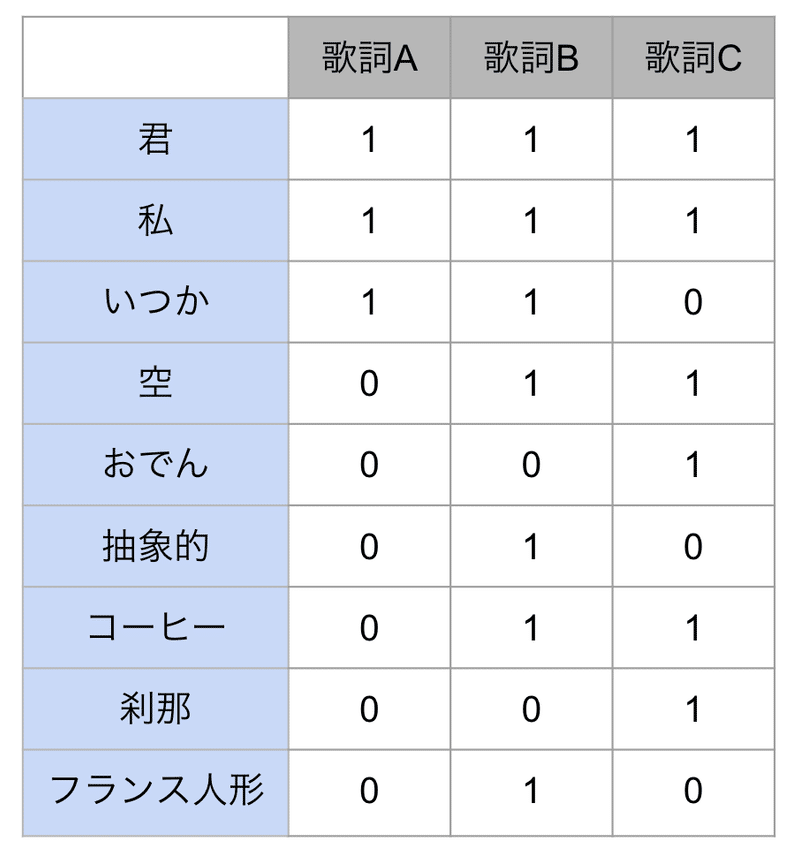
上で示した式②を基に、「単語のありきたりさ」を求めます。
「君」や「私」は3つの歌詞に出現するので値が小さい=ありきたり
「おでん」は1つの歌詞のみに出現するので値が大きい=ありきたりでない
という解釈です。
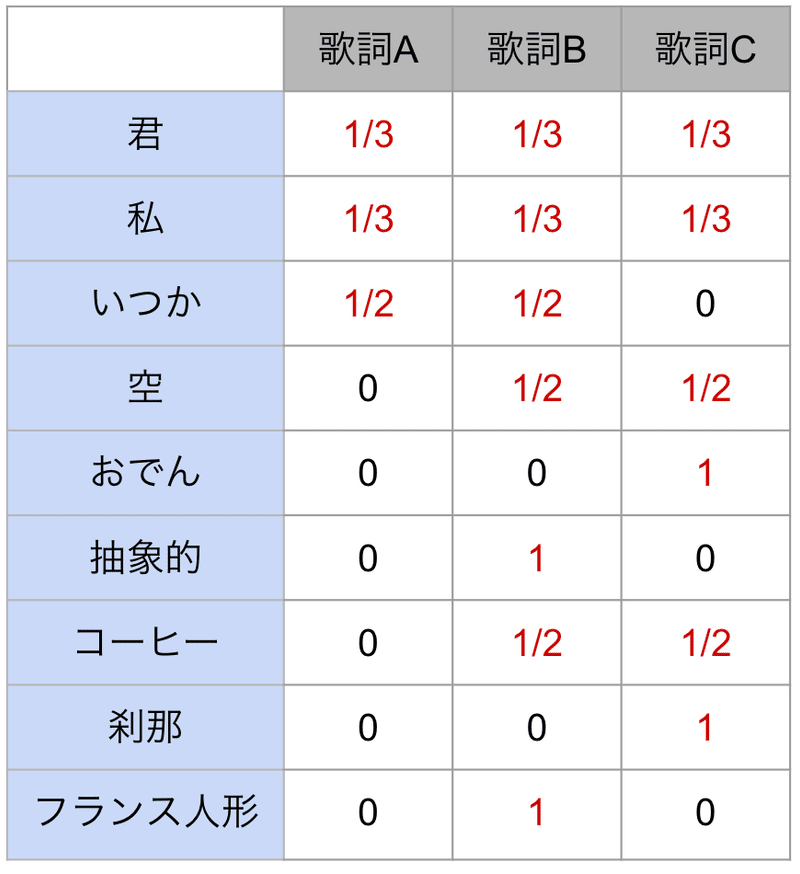
あとは式1を基に、「歌詞全体のありきたりさ」を求めます。
この結果、歌詞A、B、Cの順に「ありきたり」であることがわかりました。

やってみた
これまでの流れをPythonを使って書いていきます。
まずは適当な方法で歌詞をスクレイピングしてきましょう。

Pandasで読み込んでやって、前処理をしていきます。
ゴールとしては上に示したように、単語×歌詞名(曲名)の行列に出現の有無が格納されているイメージです。
import pandas as pd
import re
#曲名と歌詞からなるテーブルの読み込み
title_lyric_df = pd.read_csv('title_lyric.csv',header=None)
title_lyric_df.columns=['title','lyric']
#正規表現でアルファベット,数字,空白,「」の除去(本当はもっと色々除去したほうが良いです)
title_lyric_df['lyric'] = title_lyric_df['lyric'].apply(lambda x:re.sub('[0-9a-zA-Z\s+「」]+','',x))まずは歌詞を単語ごとに分解する必要があります。今回は、MeCabというパッケージを使います。ポイントは、助詞や助動詞を除くこと、動詞は基本形に戻しておくことです。
import MeCab
#文章を単語+スペースに変換する関数
def split_text_only_noun(text):
tagger = MeCab.Tagger()
words = []
for c in tagger.parse(text).splitlines()[:-1]:
_, feature = c.split('\t')
pos = feature.split(',')[0]
#助詞や助動詞を除く
if pos in ('名詞','動詞','形容詞','副詞','接続詞','感動詞') :
#動詞は基本形に戻す
words.append(feature.split(',')[6])
return ' '.join(words)
#歌詞を単語+スペースに変換
lyric_split = title_lyric_df['lyric'].apply(lambda x: split_text_only_noun(x))こんな感じで、歌詞を基本形の単語+スペースの形に変換できました。

sklearnにあるCountVectorizerを用いることで、所望の行列を得ることが出来ます。
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
bags = count.fit_transform(lyric_split)
features = count.get_feature_names()
word_title_df = pd.DataFrame(bags.toarray())
word_title_df.columns = features
word_title_df.index = title_lyric_df['title']
#出現の有無のみを見たいので,0でない値は1に丸める
word_title_df.where(word_title_df==0,1,inplace=True)(例で示した形式と合わせるために、一時的に転置してます)

ここまで出来たら後は、上に示した式を基に、「単語のありきたりさ」、そして「歌詞全体のありきたりさ」を求めていきます。
#式2により単語のありきたりさを算出
word_title_score_df = word_title_df.apply(lambda x: x/x.sum(),axis=0)
#式1により歌詞全体のありきたりさを算出
word_title_score_df['歌詞全体のありきたりさ'] = word_title_score_df.apply(lambda x: x.sum()/(x != 0).count(),axis=1)
#ソート
word_title_score_df.sort_values('歌詞全体のありきたりさ')[['歌詞全体のありきたりさ']]
結果がこちら!
最もありきたりだった歌詞は、一世を風靡した鬼滅の刃の「竈門炭治郎のうた」でした!

たしかに、よくあるフレーズが多用されている印象は受けます。
それだけキャッチーで、多くの人の心を動かしたということでしょう!
目を閉じて 思い出す 過ぎ去りし あの頃の 戻れない 帰れない 広がった 深い闇 戻れない 帰れない 広がった 深い闇 泣きたくなるような 優しい音 どんなに苦しくても 前へ 前へ 進め 絶望断ち 失っても 失っても 生きていくしかない どんなにうちのめされても 守るものがある 失っても 失っても 生きていくしかない どんなにうちのめされても 守るものがある 我に課す 一択の 運命と 覚悟する 泥を舐め 足掻いても 目に見えぬ 細い糸 泣きたくなるような 優しい音 どんなに悔しくても 前へ 前へ 向かえ 絶望断ち 傷ついても 傷ついても 立ち上がるしかない どんなにうちのめされても 守るものがある 守るものがある
逆に、ありきたりさが低い歌詞を見ていくと、vivid vice、廻廻奇譚と、呪術廻戦のものが入ってますね!
たしかに、アニソンは個性的な歌詞の場合が多い印象を受けます。
最もありきたりさが低かった、うっせえわの歌詞。
なるほど。。。。納得です。。
正しさとは 愚かさとは それが何か見せつけてやる ちっちゃな頃から優等生 気づいたら大人になっていた ナイフの様な思考回路 持ち合わせる訳もなく でも遊び足りない 何か足りない 困っちまうこれは誰かのせい あてもなくただ混乱するエイデイ それもそっか 最新の流行は当然の把握 経済の動向も通勤時チェック 純情な精神で入社しワーク 社会人じゃ当然のルールです はぁ?うっせぇうっせぇうっせぇわ あなたが思うより健康です 一切合切凡庸な あなたじゃ分からないかもね 嗚呼よく似合う その可もなく不可もないメロディー うっせぇうっせぇうっせぇわ 頭の出来が違うので問題はナシ つっても私模範人間 殴ったりするのはノーセンキュー だったら言葉の銃口を その頭に突きつけて撃てば マジヤバない?止まれやしない 不平不満垂れて成れの果て サディスティックに変貌する精神 クソだりぃな 酒が空いたグラスあれば直ぐに注ぎなさい 皆がつまみ易いように串外しなさい 会計や注文は先陣を切る 不文律最低限のマナーです はぁ?うっせぇうっせぇうっせぇわ くせぇ口塞げや限界です 絶対絶対現代の代弁者は私やろがい もう見飽きたわ 二番煎じ言い換えのパロディ うっせぇうっせぇうっせぇわ 丸々と肉付いたその顔面にバツ うっせぇうっせぇうっせぇわ うっせぇうっせぇうっせぇわ 私が俗に言う天才です うっせぇうっせぇうっせぇわ あなたが思うより健康です 一切合切凡庸な あなたじゃ分からないかもね 嗚呼つまらねぇ 何回聞かせるんだそのメモリー うっせぇうっせぇうっせぇわ アタシも大概だけど どうだっていいぜ問題はナシ
おわりに
納得感ある結果になったので、他の歌詞でもやってみたいところです。
私見ですが、最近ヒットする曲って、変わった歌詞であることが多くないですか?
数年前と比べてどうなのか、時系列比較して示唆を出したいところです。
今回は比較的シンプルなロジックを考えましたが、改良の余地はあるのかなと思っています。
もっと歌詞の特徴を反映させられる手法を思いついた方がいらっしゃいましたら、是非とも教えてください!
この記事が気に入ったらサポートをしてみませんか?