
Trying Data Science(8) : Cramming Machine Learning Basic Concepts

Intro
Hello, everyone!
Last time, I covered data visualization. This time, I'm going to cover some important concepts surrounding machine learning.
What is Machine Learning?
● Machine learning is a method of data analysis
that automates analytical model building.
● Using algorithms that iteratively learn from
data, machine learning allows computers to
find hidden insights.
Supervised VS Unsupervised
Supervised Learning is using labeled examples, such as an input where the desired output is known.
ex) Spam vs Legitimate Email
The network receives a set of inputs along with
the corresponding correct outputs, and the
algorithm learns by comparing its actual
output with correct outputs to find errors.
Supervised learning is commonly used in
applications where historical data predicts
likely future events.

Unsupervised learning is another way of machine learning, when you don’t have historical labels.
Let's get the gist of them.
● Clustering
Grouping together unlabeled data
● Anomaly Detection
Detecting outliers in a dataset
● Dimensionality Reduction
Reducing the number of features in a
data set to better understand trends

Anyway, we'll mainly cover supervised learning process below.
Overfitting and Underfitting
Overfitting means the model fitting too much to the noise from the data. This often results in low error on training sets but high error on test/validation sets.

Underfitting means the model that does not capture the underlying trend of the data and does not fit the data well enough. It has low variance but high bias. Underfitting is often a result of an excessively simple model.
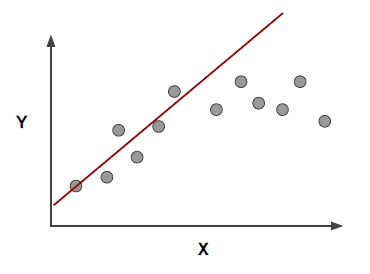
When thinking about overfitting and underfitting we want to keep in mind the relationship of model performance on the training set versus the test/validation set.
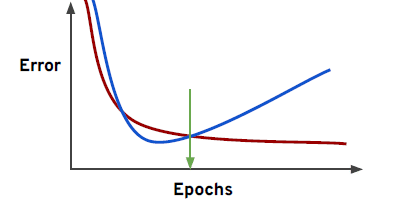
If overfitting on the training data, it means we would perform poorly on new test data! So you should look for the point to cut off training time!
Evaluating Performance: Classification
The key classification metrics we need to understand are four points.
○ Accuracy
The number of correct predictions made by
the model divided by the total number
of predictions.
Correct Prediction / Total Predction
○ Recall
Ability of a model to find all the relevant cases within a dataset. The precise definition of recall is the number of true positives divided by the number of true positives plus the number of false negatives.
True Positives / ( True Positives + False Negatives)
○ Precision
Ability of a classification model to identify only the relevant data points. The number of true positives divided by the number of true positives plus the number of false positives.
True Positives / (True Positives + False Positives )
○ F1-Score
The F1 score is the harmonic mean of precision and recall. We use the harmonic mean instead of a simple average because it punishes extreme values.

We can also view all correctly classified versus incorrectly classified images in the form of a confusion matrix.

Often we have a precision/recall trade off, so we need to decide if the model will should focus on fixing 'False Positives vs. False Negatives'
Evaluating Performance: Regression
Regression is a task when a model attempts to predict continuous values.
ex) attempting to predict the price of a house given its features => regression
cf) attempting to predict the country a
house is in given its features => classification
Mean Absolute Error(MAE)
This is the mean of the absolute value
of errors. MAE won’t punish large errors, but account for them.

Mean Squared Error(MSE)
This is the mean of the squared errors. Larger errors are noted more than with MAE.

Root Mean Square Error(RMSE)
This is the root of the mean of the squared errors. It is the most popular one among three above.

Outro
Today I have covered the definition of machine learning and deference between 'Supervised and Unsupervised', 'Overfitting and Underfitting', 'Classification vs Regression'. They are basic concepts for machine learning, so we have to keep mind them.
エンジニアファーストの会社 株式会社CRE-CO
ソンさん
この記事が気に入ったらサポートをしてみませんか?