
ComfyUIでAniportraitを試してみた

chaojieのComfyUI-AniPortraitをインストールしたがうまく動かなかったが
frankchiengのComfyUI_Aniportraitが使えた。
この記事の内容を行うとVRAM使用量が12GBなので、それ以上のグラボが必要です。
<筆者環境 win10 RTX4070ti ComfyUI: 2045[b7b559](2024-03-04)>
インストール
まずgit cloneするかComfyUI Managerからインストールする。
モデルのダウンロードが必要だが、今回は結構インストールする必要がある。
レポジトリのルートディレクトリである"ComfyUI\custom_nodes\ComfyUI_Aniportrait"の中に"pretrained_model"フォルダを作る。
"pretrained_model"フォルダ内に移動し、コマンドプロンプトを開き、次のコマンドを打つ。
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
git clone https://huggingface.co/stabilityai/sd-vae-ft-mse
git clone https://huggingface.co/facebook/wav2vec2-base-960h次に
config.json
pytorch_model.bin
をダウンロードし、"pretrained_model"内に
"image_encoder"フォルダを作り、中に入れる。
更に以下のモデルをダウンロードする。
denoising_unet.pth
reference_unet.pth
pose_guider.pth
motion_module.pth
audio2mesh.pt
最終的に以下の配置になる。
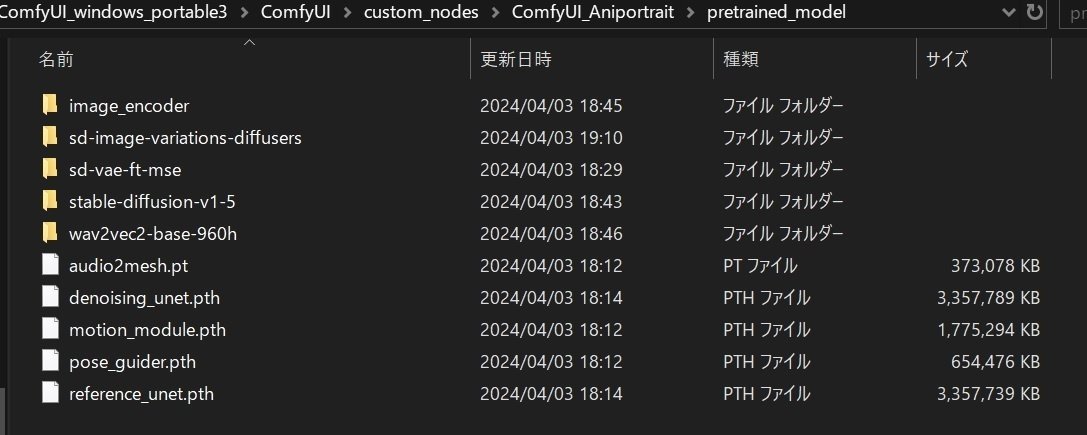
テスト実行
ワークフローは、assetsフォルダ内にある。
audio2video_workflow.json
pose2video_workflow.json
face_reenacment_workflow.json
assetsフォルダ内にはサンプルデータもある。
ワークフローのノードがパス指定タイプなので、
windows環境では手打ち入力が面倒です。
なので以下のビデオサンプルと音声サンプルのパスをコピーしてワークフローのノード内のpathに張り付けてください。
ComfyUI/custom_nodes/ComfyUI_Aniportrait/assets/pose_ref_video.mp4
ComfyUI/custom_nodes/ComfyUI_Aniportrait/assets/lyl.wav入力画像は好きな画像を用意してもらえればいいですが、
画像いっぱいに顔が映っている画像の方がいい結果になる傾向があるように思います。
顔が小さい画像は、歪みが出ます。