
【アプリ開発日記57週目】たった1枚のイラストから様々なバリエーションを作り出せるか?〈SD前編〉

おはようございます、ちゅーりんです。自分で描いた絵をAIにかけて自分の絵柄のイラストを色々作ってみたい!ということで今回に至ります!
今回は0から始められるように備忘録も兼ねて。
※2023/3/9追記:57~59週目の内容を、備忘録としてまとめました。Stable Diffusionが使える状態で「自分の絵を学習させたい!」の結論が気になる方は、以下の記事をご覧ください!
以前「1枚の画像を読み込ませるだけでそれに似た画像を作れるよ!」という記事を見かけました。当時は問題アプリ作成でそれどころでもなかったのですが、開発が一区切りついた今「今度こそ!」と思って今に至ります。
去年の11月! 意外と早い時期に公開されていました。「Advanced Prompt Tuning(APT)」というそうです。embedding(埋め込み。テキスト反転と呼ぶことも)という技術の応用系という位置づけですので、調べるときはこちらのほうがいろいろな情報が出てくるかもしれません。
今まで趣味で絵を描いていたこともあって、すると必然的に自分の絵柄を量産してみたくなっちゃう、というのも大きなきっかけですね。最後に結果も載せておきます!

今までデフォルトのstable diffusionしか触っていなかったので、このように自分で拡張機能を追加するのは今回が初めて。さらに、機械学習はCPUだけじゃなくてGPUも必要と知って数十万飛んでいきました。
というわけでさっそく始めていきます!
1,導入
本家のreadmeに沿って。
Python 3.10.6をインストール(※時期によって変わるので、本家の導入を確認して下さい)。インストーラーの最初の画面で「Python を PATH に追加」チェックを忘れないように。
gitをインストール
コマンドプロンプトで「git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git」を使い、stable diffusionをダウンロード
チェックポイント (model.ckpt) をmodels/Stable-diffusionディレクトリに配置(下記参照)
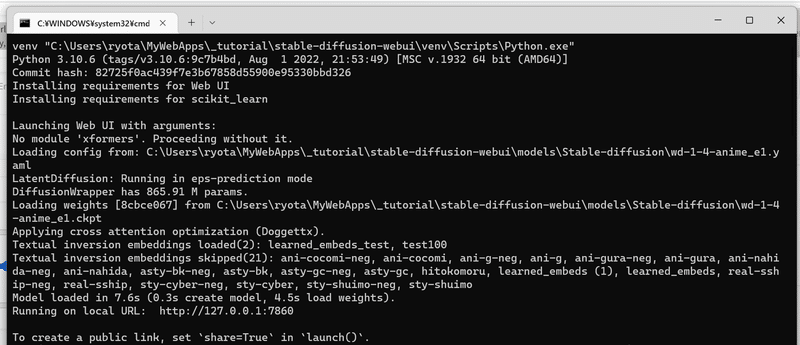
「webui-user.bat」ファイルを通常の非管理者ユーザーとして Windows エクスプローラーから実行 →自動でコマンドプロンプト起動&下の画面のようになり、指示通りhttp://localhost:7860/にアクセスするとstable diffusionをブラウザ上で使えるようになります!
【補足】
・これを書いた時Python の最新は3.11でしたが、PyTorchが対応しておらずエラーになりました。これを行ったときは公式で3.10.6と書かれていたので、その通りインストールすれば進めます
・「model.ckpt」とは学習データのことです。これはstable diffusionとは別にダウンロードする必要があります。もちろん本家もあれば、有志の方が作った派生系まで様々。私はWDを使いたかったので、以下のサイトからダウンロードしました。
モデル一覧:https://economylife.net/ai-models-list/
WD v1.4:https://fls.hatenablog.com/entry/2023/01/02/141055
・その他、うまくいかないときは最後に起動するコマンドプロンプト上のエラーをよく読んだり、そのままコピペして調べると解決することが多いです
2,拡張機能を追加
今回の本題。この拡張機能に関する説明は意外と日本語が見つからず、それがこの記事に残すことになったきっかけでもあります。
まず本家のディレクトリ(stable-diffusion-webui)直下にコマンドプロンプトで移動(cd stable-diffusion-webui)します。そして以下のコマンドで拡張機能をダウンロード。
git clone https://github.com/7eu7d7/DreamArtist-sd-webui-extension.git extensions/DreamArtistすると「extensions」フォルダ内に拡張機能がダウンロードされるので、この状態で再びwebui-user.batを押してブラウザで開き、
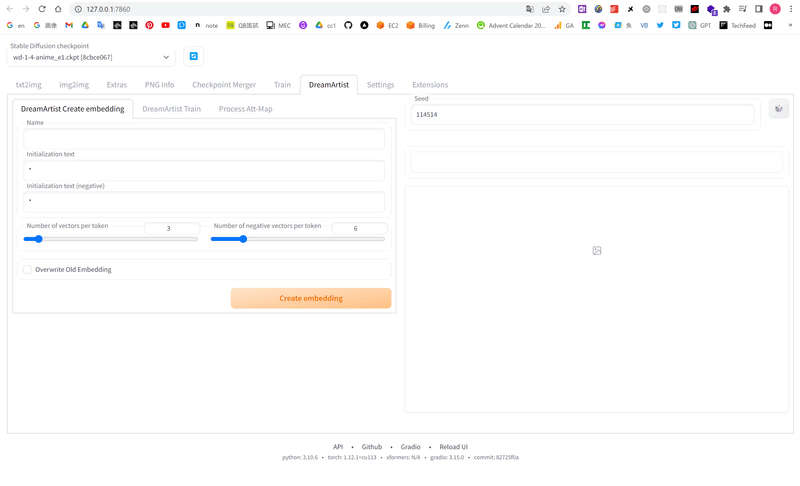
このように「DreamArtist」というタブが増えていれば成功です!
いろいろ試していてわかったことですが、「DreamArtist」は
Create embeddingで何でもいいので(空の)モデルを作る(girlなど)
Trainで、用意しておいたイラストとcheckpointファイル(配布されているもの)から、1で作ったモデルに新たなモデルを上書きする
デフォルトの txt2img で、2で作成したモデルとプロンプトを元に新たな画像を生成
の流れによって、プロンプト「+好みの画像」から新しい画像を生成できる、という仕組みみたいです。
良くも悪くもひと月立たないペースでアップデートされているので、チュートリアルどおりにやってもWaifu diffusionをckptファイルに設定するとうまくいかなかったなど、想定外のところで躓くこともあるかもしれません。根気強く完成させていきましょう。
ではさっそく最初のモデルを作成していきます!
2-1,Create embedding
まず「〇〇.pt」というファイルを作成します。「1枚の画像から似た画像を生成できる」といっても、1枚の画像とptファイルを元に新たなptファイルを作り、それとプロンプトを元に新たな画像を生成するのです。実際に作ってみるまで分かりにくいですね。
その読み込ませるファイルがembeddingという「〇〇.pt」。ここでは仮のembeddingファイルを作成します。ブラウザ上でもこういったファイルの配布が行われていますが、stable diffusionのバージョンが異なると?読み込めないことも多々あったので、自分で作成するのが無難かと。(※ckptファイルによる場合もあります。私の場合、waifu diffusion→anything_v4に変えると読み込めました)
他の方の場合です。もし私が行っていた方法で詰まった場合、下記の記事も参考にしてみてください!
注意点は、デフォルトの「Train」はここでは意味がないということ。DreamArtist内のTrainは「〇〇.pt」に加え「〇〇-neg.pt」というファイルも生成し、これが後で必要になってくるためです。
前置きが長くなりましたが、「DreamArtist > DreamArtist Create embedding」タブへ。
あくまで仮ファイルなので、Nameは「test1」、Initializetion textは「girl」のようにシンプルで問題ないです。もともと単一のキャラクターを狙う場合は、Initialization text に要素を加えてあげます。
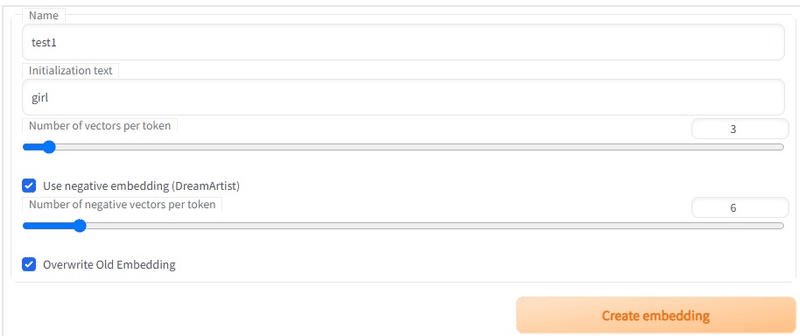
(読み飛ばして問題ないです)
Name:作成する embedding のファイル名。学習データを呼び出す際にプロンプトに入力するワードになる
Initialization text:画像の特徴を指定する初期テキスト。たとえば "zzzz1234" という名前の1ベクトル(1トークン)の embedding で初期テキスト "tree" を指定したとする。トレーニングなしでそれを "a zzzz1234 by monet" というプロンプトで使うと、その出力結果は "a tree by monet" と同じになる。
つまり Initialization text には学習してほしいタグを書く。白髪赤目センター分けショートヘアーを学習させたいなら、Initialization text には red eyes, white hair, parted bangs, short hair を入れる。
Initialization text は学習画像に含まれる属性かつモデル(ckpt)で認識できる語が望ましい。
Number of vectors per token:embedding のトークンひとつあたりのサイズ。この値を大きくすればより多くの情報を詰め込めるが、より多くのトークン数を消費する。たとえば 16 ベクトル embedding はたとえ1語であっても 16 トークン消費する。プロンプトは 75 トークンしか入力できない。大ベクトルで良い結果を得るには、より多くの画像が必要になる。また大ベクトルは余計な情報を学習してしまう事にも注意が必要。
続いて「txt2img」タブ内にも入力。このとき上の方に先程の「{Name}」(test1など)、下の方に「{Name}-neg」(test1-negなど)を入れるのを忘れないで下さい。

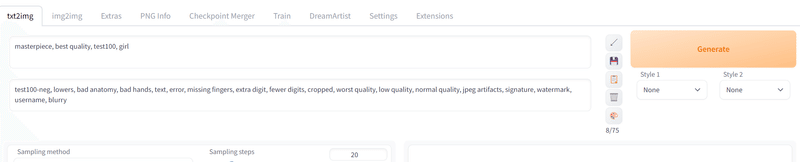
masterpiece, best quality, test2, girltest2-neg, lowers, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry 下の方はnegative、つまり「このワードは入れないで!」というものです。これにより「こんな絵になるはずじゃ…」を防ぎます。
2-2,「Train」で絵を学習させる
続いて「DreamArtist > DreamArtist Train」タブ内を以下のように設定。
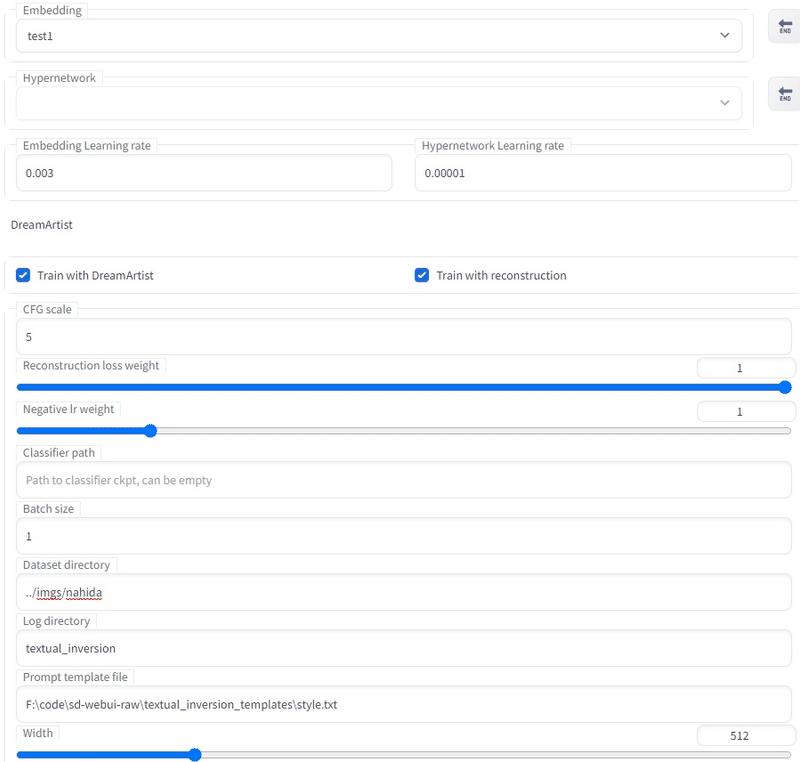
「Dataset directory」にはstable-diffusion-webuiを親として、どこに学習させる(1枚の)正方形の画像があるか、を記します。上の画像であれば「stable-diffusion-webui/imgs/nahida」ディレクトリ内の画像を参照します。画像のファイル名は入れなくて大丈夫です。
以下の設定も忘れないように。これにより、train中リアルタイムでtxt2imgのプロンプトをもとに100stepごとにプレビューを作成してくれます。

これでトレーニングを開始させ、
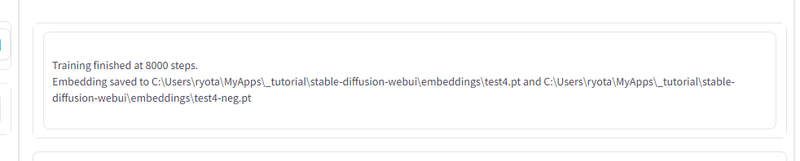
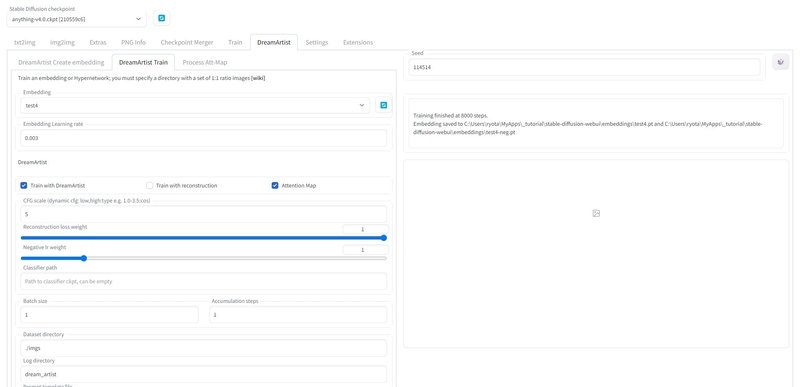
となれば成功です!
先ほどの最後の設定ですが、stepが100進むごとにその時点までに作成された学習モデルとtxt2imgのプロンプトからイラストが自動生成されるようです。特に1枚目は学習元データとcreate embeddingを作成した時のinitialization textに入力したプロンプトが色濃く反映されており、そこから自分のイラストの要素を徐々に取り入れている印象。なので、極稀に開くとR18が並んでいるときもあります、気を付けてください笑。逆に言えば、step数が多ければinitialization textの影響はかなり少ないとも考えられます。
girlなどシンプルにしているといろいろなキャラが生まれるので、これだけでもキャラデザのインスピはかなり滞ります!(しかも少なくともパクリは意識しなくて済む!)
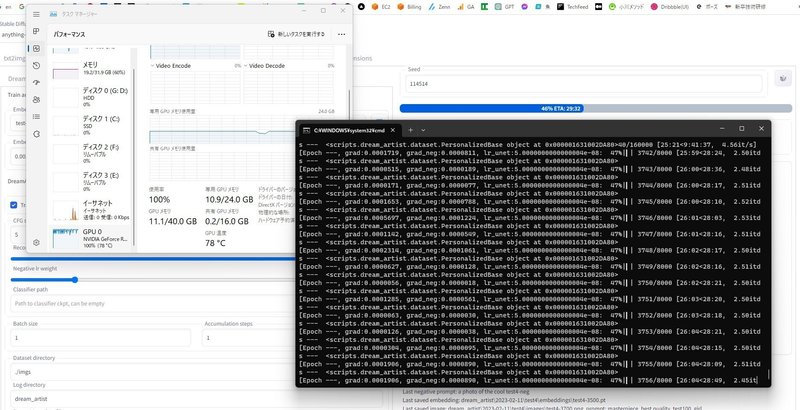
【GPU不足エラーが出た時の対処法】(前提としてGPU 8gb以上は必要)
PowerShellなどで以下のコマンドを入力
GPUの余裕とプロセスIDを確認:nvidia-smi
GPUを食っている処理をkill:taskkill /pid プロセスID /f
※高性能のGPUでも連続して使うとオーバーすることがあります。その時は一度stable diffusionのpowershellを閉じて再起動すると回復します
2-3,txt2imgで画像生成!
待ちに待った画像生成。ここまでくればあと少し。
「txt2img」タブのプロンプトを「test1」「ani-nahida」などのトレーニングで作成した名前を指定(変えていなければそのままで大丈夫です)して生成ボタンを押せば…
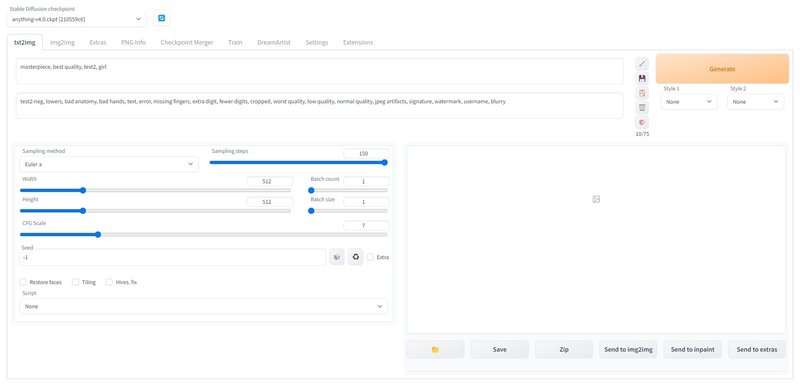
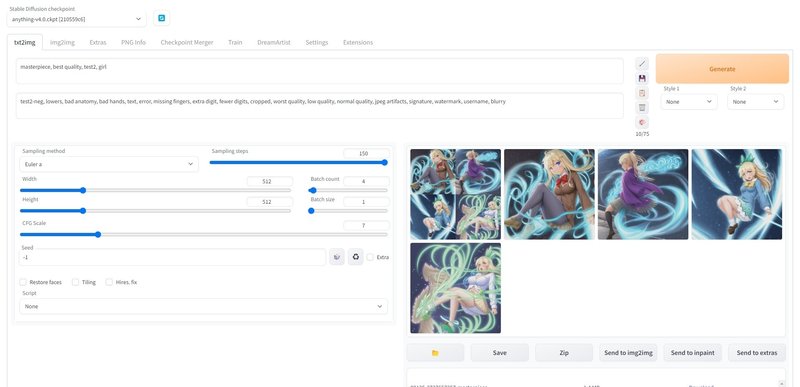
結果!




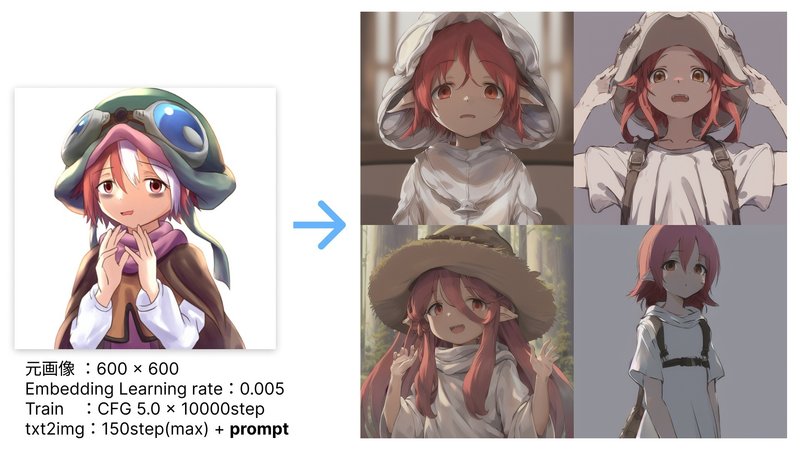
キャラとして認識できるよう、背景やエフェクトは取り払ってみました。著作権フリーや元絵を自由に加工できるのは描いた本人の特権なのかもしれません!笑
全体的に彩度が低いというか、線画が細くてやや暗め、淡い感じのテイストはcheckpoint(学習データ)のanything V4.0の影響でしょうか?
絵柄はまだまだ改善の余地がありますが、「元の1枚のイラストをベースに様々なバリエーションを作り出す」は少しずつ近づいてきたような気がします。これだけでもかなりすごいです!
読み込ませる画像と同じキャラを出す方法はまだ模索中ですが、一度作成した学習モデルからはだいぶ同じ特徴を持ったキャラが生まれてくる印象があります。これにプロンプトで細かい設定を付け加えてあげれば、比較的安定して同じキャラのいろんなシチュエーションを量産できそうですね!
参考にさせていただいたこの記事では8万回学習させていました。過学習の基準はわかりませんが、少なくともここでは絵柄も特徴も非常に安定していたので、このあたりも調整大事なのかも。にしてもこのクオリティすごい…! 悔しいけど、まだまだ実力不足です。
また、『1枚のイラストから狙った画像を出すポイントまとめ』にembedingの回数などを中心に自分なりのポイントをまとめておきました。同じtrainタブ内の Embedding Learning rate みたいに他にもいじれるパラメーター色々ありそうです。
やる前から楽しみにしていたけど、不完全ながらちゃんと機械学習できたという安堵感と、やっぱ画像生成すごい!AIすごい!という感動が長い初期設定を終えた後に流れ込んできて、落ち着いた興奮、充実感にあふれている今です。できて本当に良かった!
おわりに
不思議なことに、こうやって自分のイラストを学習させて新たな絵を作っていると、久しぶりにガッツリとした手書き(PC)の絵も描きたくなってきます。AIでも何でも使って、もっとすごい作品作ってやろうと。
AI画像生成を始めたときはもうコードの世界に行ったきりになるとばかり思っていましたが、意外とアートへの興味が再燃してくるってあるんですね。最近マンガを読んでいた衝動で自分でも描いてみたくなったりしてキャラデザとストーリーをひたすら考えていましたが、もしかしたらそれもコードを書いていたことと関係しているのかもしれません。
そんなわけで、コードを書く傍ら画像生成の可能性も探る今後になりそうです。
ではでは!
【裏話】バグの対処法と、GPUが足りずパソコンを購入した話
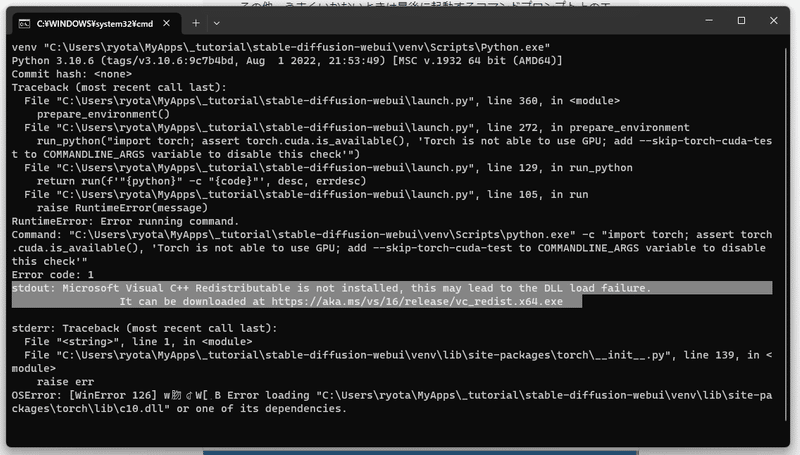
上記ではスムーズに行ったかのように見えますが、実は途中で思いっきり沼にハマっていました。たくさんのエラーに加え、そもそもGPUが足りなかったのです。
上では省略したその過程を、ここではつらつら書いていきます。個人的な、日記です。
1,embeddingが作成できない
これはパソコン関係なく、checkpointファイル(.ckpt)の問題でした。はじめは「stable-diffusion-webui \ embeddings」内に
wd-1-4-anime_e1.ckpt
wd-1-4-anime_e1.yaml
(yamlファイルもあるのはWaifu diffusionの特性です)
を入れていたのですが、これだとDreamArtist内のCreate embeddingができないうえに、Trainタブ内でも外部からとってきたほとんどの学習済みモデル(.ptファイル)が選択できなかったのです。そこで
anything-v4.0.ckpt
に変えたところ、上記の2つの問題は無事解消できました。もちろん、最後のtxt2imgの絵柄も変わってきますが……
2,trainできない
ここもかなり迷走してました。trainを始めるとプログラム内でエラーが起きて、すぐ止まってしまうんですよね。print()を使ってもコンソールに何も表示されなかったため、エラーになっているところを力技で書き換えました。
幸いエラーとなっていた部分はいずれもコンソールの表示に関わるものだったので、機械学習自体の処理は変わっていません(たぶん)。
以下、修正一覧(#コメント文がもともとの処理)です。
stable-diffusion-webui\extensions\DreamArtist\scripts\dream_artist\cptuning.py
def write_loss(log_directory, filename, step, epoch_len, values):
(中略)
with open(os.path.join(log_directory, filename), "a+", newline='') as fout:
csv_writer = csv.DictWriter(fout, fieldnames=["step", "epoch", "epoch_step", *(values.keys())])
if write_csv_header:
csv_writer.writeheader()
# epoch = step // epoch_len
# epoch_step = step % epoch_len
epoch = 0
epoch_step = 0
csv_writer.writerow({
"step": step + 1,
"epoch": epoch,
"epoch_step": epoch_step + 1,
**values,
})stable-diffusion-webui\extensions\DreamArtist\scripts\dream_artist\cptuning.py
def train_embedding(embedding_name, seed, learn_rate, batch_size, data_root, log_directory, training_width, training_height, steps, create_image_every, save_embedding_every, template_file, save_image_with_stored_embedding, preview_from_txt2img, preview_prompt, preview_negative_prompt, preview_steps, preview_sampler_index, preview_cfg_scale, preview_seed, preview_width, preview_height,
cfg_scale, classifier_path, use_negative, use_att_map, use_rec, rec_loss_w, neg_lr_w, ema_w, ema_rep_step, ema_w_neg, ema_rep_step_neg, adam_beta1, adam_beta2, fw_pos_only, accumulation_steps,
unet_train, unet_lr):
(中略)
pbar = tqdm.tqdm(enumerate(ds), total=steps-ititial_step)
for i, entries in pbar:
(中略)
steps_done = embedding.step + 1
# epoch_num = int(embedding.step.astype(int)) // len(ds)
# epoch_step = int(embedding.step.astype(int)) % len(ds)
epoch_num = 0
epoch_step = 0
pbar.set_description(f"[Epoch ---, "
# pbar.set_description(f"[Epoch {epoch_num}: {epoch_step}/{len(ds)}]loss: {losses.mean():.7f}, "
f"grad:{embedding.vec.grad.detach().cpu().abs().mean().item():.7f}, "
f"grad_neg:{embedding_neg.vec.grad.detach().cpu().abs().mean().item() if use_negative else 0:.7f}, "
f"lr_unet:{optimizer_unet.state_dict()['param_groups'][0]['lr']}")
if embedding_dir is not None and steps_done % save_embedding_every == 0:
# Before saving, change name to match current checkpoint.
embedding_name_every = f'{embedding_name}-{steps_done}'
last_saved_file = os.path.join(embedding_dir, f'{embedding_name_every}.pt')
save_embedding(embedding, checkpoint, embedding_name_every, last_saved_file, remove_cached_checksum=True,
use_negative=use_negative, embedding_neg=embedding_neg, unet_layers=unet_part_list)
embedding_yet_to_be_embedded = True
# write_loss(log_directory, "prompt_tuning_loss.csv", embedding.step, len(ds), {
print('ds --- ',ds)
write_loss(log_directory, "prompt_tuning_loss.csv", 8000, 10, {
"loss": f"{0}",
# "loss": f"{losses.mean():.7f}",
"learn_rate": scheduler.learn_rate
})
(中略)3,GPUが足りない
…
続いて「DreamArtist > Train」タブ内を以下のように設定。
(中略)
これでトレーニングを開始させ、(中略)となれば成功です!
…となるはずだったんですが!
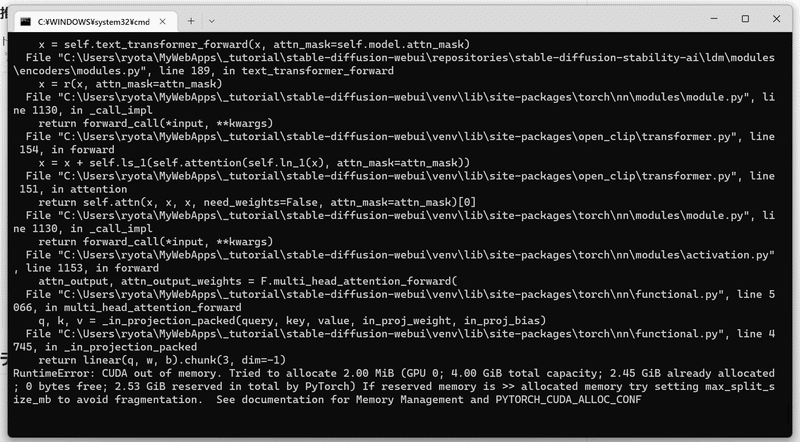
つまり「GPU 4GBしかないよ、足りないよ」ということみたいです。解決策を探ると「taskkillerで実行中の処理を中断させよう」とのことだったのでやってみたところ、たしかに余裕はできました。けれども! もともと今回の機械学習でほとんど使っていたので、改めて画像を生成しようとすると同じエラーに。
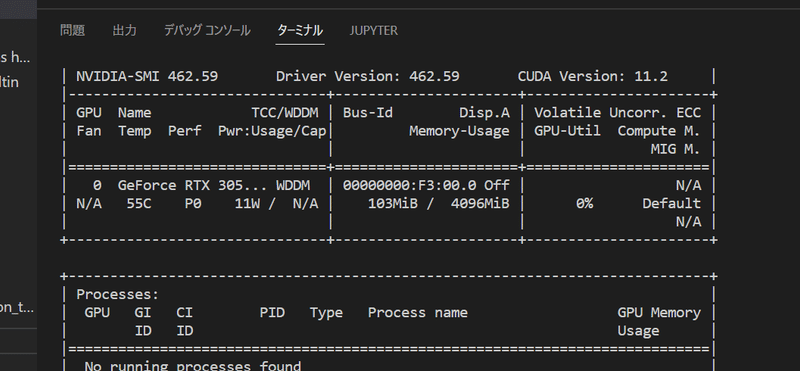
調べてみると、機械学習ではよくあることみたいですね、GPU足りない問題。今回みたいに「train」させる場合は最低でもGPU 8GBが必要みたいです。
「いやでも他にGPUないし…デスクトップも昔のだし」
一応Google Colabは高機能のGPUを使えるのですが、今回みたいに拡張機能を入れられるほどColab上で柔軟な操作はできず。
卒論で機械学習をしていたという友人に相談したところ「うん、たしかに今のPCだと厳しいね」とのことだったので、思い切ってGPUを買うことにしました。
こんなに高いんですね、高性能のGPUって。2年間コツコツ投資をして貯まっていたお金があったので、ここから出すことにします。今までは絶対に手を出さないとしていたお金ですが、大学中しかも時間に余裕ある時に一度使い切ろう、できること全部やろうと決めていたため、ついに使うことになります。
ありがとう過去の自分。責任持って使わせてもらいます。
そんなわけで、(ほとんど友人に決めてもらったけど)パソコンの組み立てへ。もはやアプリ開発とは何の関係もありません。
4,機械学習用のパソコンを組み立てる
本当にありがとう友人T。去年の夏にFlutterでネイティブアプリを作るきっかけになったのも彼でした。あの時会ってなかったら、本当に今頃ネイティブアプリの開発経験はしてなかったです。
何より彼はもともとこういった機器、ハードウェアはめっぽう強く、部屋にも床に穴開くんじゃないかってくらい様々なデバイスが並んでいます。今回相談したときもすぐ電話してくれて、「じゃあこれくらいのスペックが必要だね」「ここで買うと安いよ、揃えようか」と細部まで丁寧に教えてくれました。自分だけだと絶対ネットでセット探して割高な分スペックも限定せざるをえない、なんてことになっていたので、本当に感謝しかありません。
じゃあ私に何ができる? 病気を治したり紹介状書いてあげるくらいしかできません。勉強頑張ります。
といってもここは本当に個人的な話ばかりで備忘録とは遠ざかってしまうので、結果だけ載せておきます!


届きましたNVIDIA GeForce RTX 3090!
なんとGPU 24GBと超強力な仕様。機械学習させてるときも、不安になるくらいファンの音がすごいです。サーバー動かしてる!って感じで、テンション上がります笑
これで改めていろいろインストールしてStable Diffusionを起動したら、無事動きました!
参考サイト
stable diffusion 本家(インストールの手順)
拡張機能の大本(今回は使っていません。今回は上の大本+下の拡張機能を使っていますが、これはそれをセットでインストールできる、というものです)
今回使った拡張機能
この記事が気に入ったらサポートをしてみませんか?