
Pythonを用いてWebスクレイピングの一例 ~吉野家の店舗情報を自動で取得~

1. はじめに
1.1 Webスクレイピングについて
Webスクレイピングとは、WebサイトからページのHTMLデータを取得し、HTMLのテキスト情報を解析することでマーケティングなどの必要な情報やデータを取得して、新たな価値を生むことができます。特に、Pythonなどのプログラミング言語を用いてHTMLのテキスト情報の取得を自動化することで業務の効率化を推進することができ、マーケティングなどの目的に対して効果的な情報を提供してくれます。
1.2 PythonによるWebスクレイピング
Pythonを用いてWebスクレイピングをする際に必要となる代表的なライブラリに、requests、BeautifulSoup、Selniumがあります。Selenium は Web ブラウザの操作を自動化するためのフレームワークです。webスクレイピングでは、HTMLのデータを取得してHTML内の要素を抽出したり、テキストボックスに文字を打込んだり、ページを遷移させたりします。
1.3 本記事の内容
本記事では、Seleniumを用いて吉野家の店舗検索ページを自動で操作して、店舗の「店舗名」, 「住所」, 「店舗情報が記載されたホームページのリンク」といった情報を自動で取得してCSV形式で保存する方法をご紹介します。
まずは、SeleniumによるWebブラウザの操作方法を示し、その後応用事例として、Webスクレイピングにより吉野家店舗の情報を自動で取得して、CSVファイルで保存する方法を紹介しました。
1.4 本記事のメリット
SeleniumによるWebブラウザの基本操作を学べる
SeleniumとWebdriver_managerを用いてGoogle Chromeを開く方法を学べる
Google検索ページを例に自動操作で検索を簡単に学べる
応用事例として、吉野家の店舗情報をSeleniumを用いて取得するコードの記載方法、WebページのHTML情報からコードの設計方法を学べる
2. SeleniumによるWebブラウザの操作
2.1 Seleniumについて
SeleniumはWebブラウザ操作を自動化するフレームワークです。
Seleniumは下記のコマンドでインストールできます。
pip install selenium2.2 seleniumによる要素の抽出方法
HTMLからseleniumを用いて要素を取得する方法はは下記の記事で示されています。
要素を取得するにはfind_element()、find_elements()を用います。find_element()では1つの要素を取得(複数ある場合には先頭の要素)、find_elements()では複数の要素を取得します。これらを用いてWebページのHTML情報の取得やページ内の操作を実行していきます。
id属性を指定して取得:find_element(By.ID, "id")
name属性を指定して取得: find_element(By.NAME, "name")
xpathを指定して取得: find_element(By.XPATH, "xpath")
link textを指定して取得: find_element(By.LINK_TEXT, "link text")
partical link textを指定して取得: find_element(By.PARTIAL_LINK_TEXT, "partial link text")
タグ名を指定して取得 :find_element(By.TAG_NAME, "tag name")
class属性を指定して取得: find_element(By.CLASS_NAME, "class name")
cssセレクタを指定して取得: find_element(By.CSS_SELECTOR, "css selector")
下記の記事にて簡単なHTMLデータから要素を取得する方法を紹介していますので、ご確認ください。
2.3 webdriver managerによるGoogle Chromeの操作
従来はGoogle ChromeのバージョンとChrome Driverのバージョンを一致させる必要があり、毎回そのバージョンに合わせたChrome Driverのバージョンをインストールする煩雑さがありました。下記リンク記事のような作業をする必要がありました。
しかし、現在ではWebdriver_managerを用いることで、自動的にchromeのバージョンを確認してくれるので上記の作業は不要となり、簡便にGoogle ChormeのWeb画面を自動的に操作できるようになりました。
webdriver_managerは下記のコマンドでインストールできます。
pip install webdriver_manager2.4 seleniumとwebdriver_managerを用いてChrome検索ページの表示
それでは上記で動作環境ができたと思いますので、seleniumとwebdriver_managerを用いてChrome検索ページの表示を実施してみたいと思います。下記プログラムを実行すると、Chrome検索ページが10秒間表示されます。
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Google Chromeの検索ページ
url = 'https://www.google.com/'
# Googleのブラウザを開く
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(url)
# 10秒待機
time.sleep(10)
#chromeを閉じる
driver.close() 2.5 Google検索ページで自動操作で検索
さて、Chrome検索ページを表示できたところで、続いてGoogle検索ページで自動的に検索欄に検索ワードを挿入して、検索結果を表示させたいと思います。
まず、下記リンクのページを開き、キーボードの「Ctrl」+「Shift」+「i」を押してデベロッパーツールを表示させてください。デベロッパーツールとはGoogle Chromeに標準搭載されている開発者用の検証ツール(デバッグツール)です。
デベロッパーツールは下図のように表示されます。右側に暗い画面が表示されてHTML情報が表示されるようになりました。
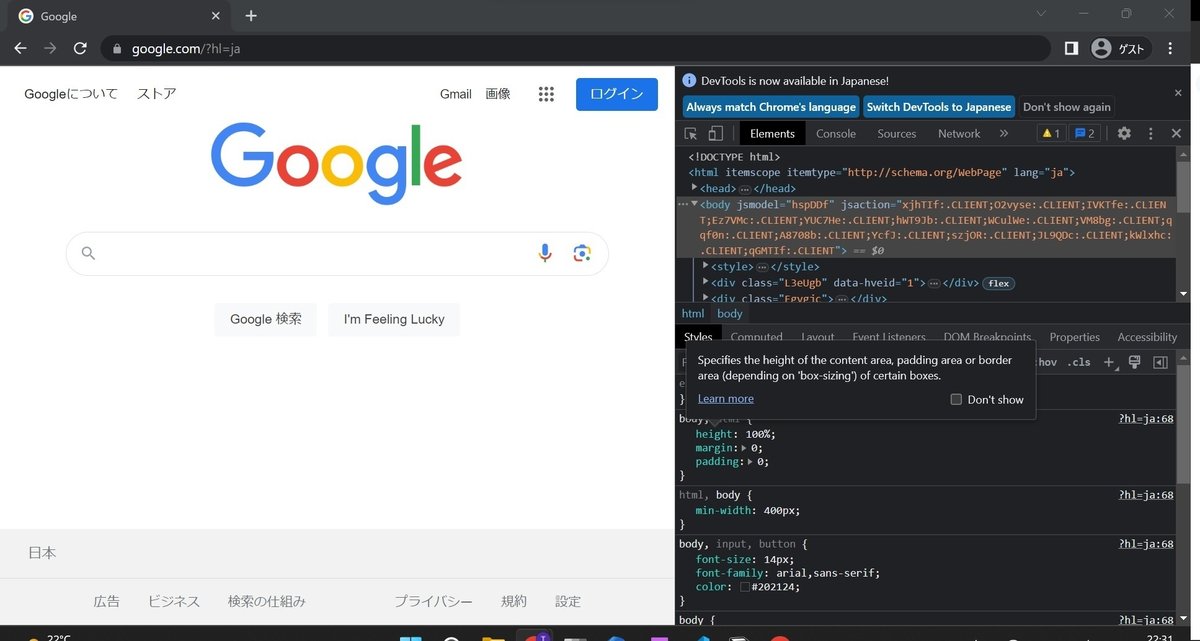
次に、キーボードの「Ctrl」+「Shift」+「C」を押してページの要素を選択できるようにしましょう。そして検索欄をクリックしてみてください。
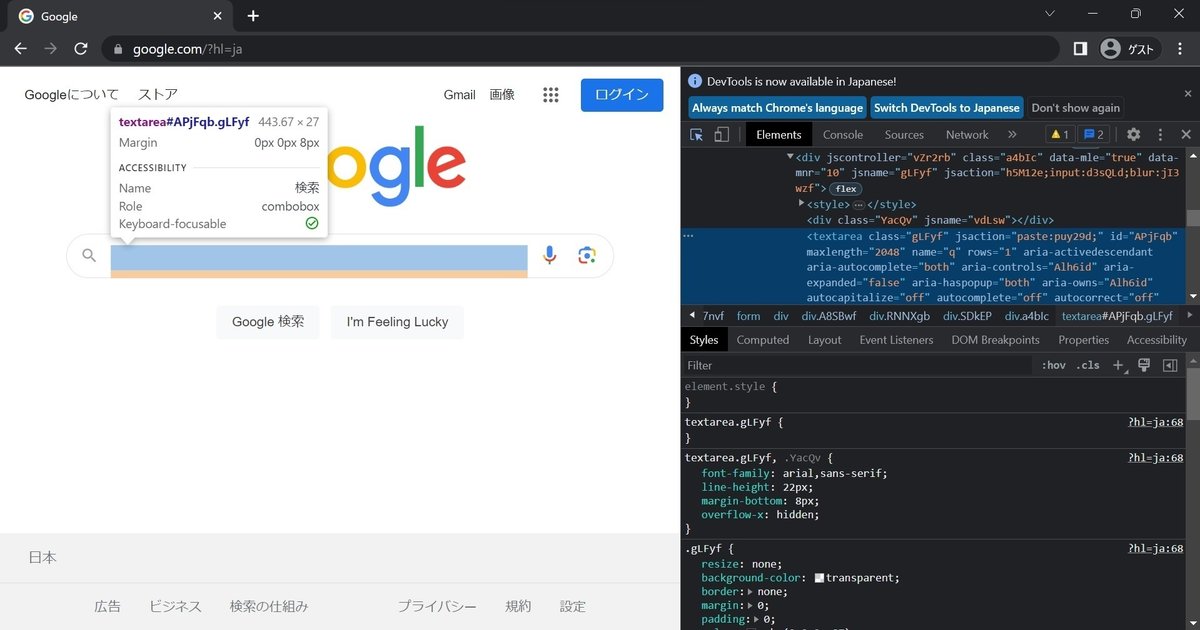
この時に右側の黒い画面も選択した要素に青っぽく色が付きます。その内容が以下です。
<textarea class="gLFyf" jsaction="paste:puy29d;" id="APjFqb" maxlength="2048" name="q" rows="1" aria-activedescendant="" aria-autocomplete="both" aria-controls="Alh6id" aria-expanded="false" aria-haspopup="both" aria-owns="Alh6id" autocapitalize="off" autocomplete="off" autocorrect="off" autofocus="" role="combobox" spellcheck="false" title="検索" type="search" value="" aria-label="検索" data-ved="0ahUKEwjpzKO0uvz-AhVVMN4KHcqqBggQ39UDCAY" style=""></textarea>検索欄にseleniumを用いて検索ワードを挿入していきたいと思います。ここで先ほど確認した検索欄のコードを確認すると、name属性がqになっているのがわかると思います。

よってseleniumを用いてname属性がqの要素を取得して、そこでsend_keys()によって検索ワードを挿入することができることがわかります。具体的には以下のコードを用いて確認することができます。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
import time
# Chromeの起動
driver =webdriver.Chrome(ChromeDriverManager().install())
#URLのページにアクセス
URL = 'https://www.google.com/'
driver.get(URL)
# 検索ワード
search_word = 'selenium'
# name属性がqの要素を取得し、send_keys()で挿入
driver.find_element(By.NAME,'q').send_keys(search_word)
#10秒間待機
time.sleep(10)
#chromeを閉じる
driver.close() 実行すると以下の様に検索欄にseleniumの文字が入力されたページが10秒間表示されると思います。

まだこの状況では検索結果を見ることはできません。それでは、Google Chormeで検索を実施してきたいと思います。
Google Chormeで検索するには、上記の内容に加えてエンターキーを押す必要があります。キーボードのボタンを押す操作を行うにはsend_keys(Keys.***)を使用します。***はキーボード名を入れます。Enterキーの場合は、send_keys(Keys.ENTER)となります。検索ワードを入力してエンターキーを押す場合には、send_keys('検索ワード' + Keys.ENTER)となります。以下のコード例を実行すると検索が開始されて検索結果が表示されると思います。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
import time
#Chromeの起動
driver =webdriver.Chrome(ChromeDriverManager().install())
#URLのページにアクセス
URL = 'https://www.google.com/'
driver.get(URL)
# 検索ワード
search_word = 'selenium'
# name属性がqの要素を取得し、send_keys()で挿入 + Enterキーを押す操作
driver.find_element(By.NAME,'q').send_keys(search_word + Keys.ENTER)
#10秒間待機
time.sleep(10)
#chromeを閉じる
driver.close() 3.応用事例:吉野家店舗検索ページから店舗情報を自動で取得
3.1 吉野家店舗検索ページ
下記リンクが吉野家の店舗検索ページです。今回はこのページのHTMLの形式を分析してWebスクレイピングするコードを記載していきます。
3.2 吉野家店舗検索ページの構成の確認
まずは検索ページの分析をして、ページ内の構成を確認したいと思います。
第一に、下図に示す検索欄の確認をします。
ここから先は
¥ 500
この記事が気に入ったらサポートをしてみませんか?