
【OCR】Linuxでスクリーンショット画面のテキストOCRを実現する【tesseract】

はじめに
この記事では、WindowsのSnipping Toolのように、Linuxでスクリーンショット画面をOCRする方法をシェルスクリプトを使って紹介します。スクリーンショット内にQRコードが含まれている場合は、QRコードを優先して表示します。
Windowsでは最近標準機能として実装されました。<ctl>+<win>+s で部分スクリーンショット→Snipping Toolの起動→テキストアクションでOCR機能を利用できます。しかし、Linuxでは(今のところ)自分で作るしかありません。
Linuxでは定番のスクリーンショット取得アプリFlameshotとtesseract OCRコマンドを利用して、<ctl>+<win>+t →チェックアイコンクリックのみでテキスト変換する機能を作ります。コマンドを入力する必要はありますが、プログラミングの知識は必要ありません。
※ やり方とコマンドはすべて無料公開しています。有料欄にはそれらを繋げて1ファイルにしたスクリプトのダウンロードができます。記事支援いただける場合はお願いします。
必要なソフトウェア(コマンド)
flameshot
オープンソースのLinuxの画面キャプチャソフトです。
https://flameshot.org/
xsel
クリップボードをコントロールするコマンドです。
tesseract
日本語も扱える多言語オープンソースOCRソフトです。
https://github.com/tesseract-ocr/tesseract
zbarimg
バーコードやQRコードを扱うオープンソースのコマンドです。
https://github.com/mchehab/zbar
これらをインストールします。
sudo apt install flameshot xsel tesseract-ocr-jpn zbar-toolsTesseract(OCRソフトウェア)の設定
tesseractは標準でもそれなりに利用できますが、速度よりも認識精度を上げる設定を行います。
上記URLより、ベスト版jpnデータをダウンロードします。
jpn.traineddata
jpn_vert.traineddata
ダウンロードしたファイルを「/usr/share/tesseract-ocr/4.00/tessdata/」へ上書きコピーしてください。
sudo cp -i jpn.traineddata /usr/share/tesseract-ocr/4.00/tessdata/jpn.traineddata
sudo cp -i jpn_vert.traineddata /usr/share/tesseract-ocr/4.00/tessdata/jpn_vert.traineddataシェルスクリプト実装
オプションと初期化
#!/bin/bash
# 利用するコマンド
# flameshot, tesseract, zenity, zbarimg, xsel, mktemp
if [ $# != 1 ]; then
echo "`basename $0` <language>"
exit -1
fi
language="$1"
# 一時ファイルを作成
image_tmp=`mktemp`<language>にはengとjpnが利用できます。flameshotスクリーンショット画像はGNUコアユーティリティの「mktemp」コマンドを利用して「/tmpディレクトリ」に作成します。パーミッション等を正しく設定してくれます。
画像認識
# クリップボードの画像をファイル保存
flameshot gui --raw > "$image_tmp"
# アウトプット用ファイル生成
txt_tmp=`mktemp`
# QRコードがあれば、それをそのまま表示する。
if zbarimg --raw --quiet PNG:"$image_tmp" > $txt_tmp; then
:
else
# QRコードがなければ、通常のOCR
# OCR解析
tesseract "$image_tmp" - -l $language --oem 1 -c page_separator="---------" > $txt_tmp
# 空白削除
if [ "$language" = jpn ];then
sed -i -e 's/[[:blank:]]//g' $txt_tmp
fi
fiQRコードの読み取りは「zbarimg」、テキストの読み取りは「tesseract」が行います。「--oem 1」としてより精度が良いとされる LSTM AI エンジンを指定します。
※ 日本語を読み取る場合は、空白が文字間に挟まれる事が多く、コピペ用途で使いにくいため、ここで空白すべてを削除しています。必要がない場合はコメントアウトまたは削除してください。
画面表示と終了処理
# 画面表示
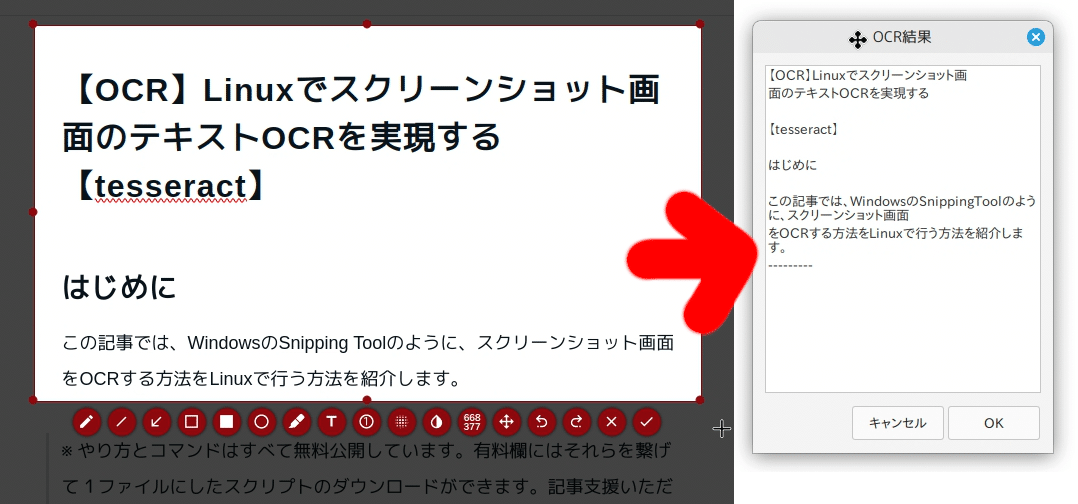
text_edit=`zenity --editable --text-info --filename="$txt_tmp" --title "OCR結果"`
response=$?
# OK ボタンが押されたらクリップボードにコピー
if [ $response -eq 0 ]; then
echo "クリップボードへ転送"
echo "$text_edit" | xsel -ib #clipboard
else
echo "キャンセルまたはエラー"
fi
# 終了処理
rm -f "$image_tmp"
rm -f "$txt_tmp"読み取り後に結果をGUIで表示します。OKボタンで自動的にクリップボードへコピーされます。
キーボード・ショートカットへ登録
シェルスクリプトのファイル名を「ocr-image-raw.sh」とします。パスが通っている適当な場所へ保存してください。「chmod +x ocr-image-raw.sh」 として実行属性をつけます。
日本文を読み取る場合は、
ocr-image-raw.sh jpn英文や数字を読み取る場合は、
ocr-image-raw.sh engとして起動します。最初にflameshotが起動するので、範囲を指定して「チェックアイコン」をクリックすると、読み取ったテキストが表示されます。

ショートカットを割り当てる場合は、Windowsと同じ「<shift>+<win>+s」だとLinuxの別の機能になっているので、Powertoys時代の「<shift>+<win>+t」に割り当てます。


実際に機能するのかを確認して終了です。

付録
記事内のスクリプトを繋げてひとつのファイルにしただけのものです。記事支援いただける場合はよろしくお願いします。
ここから先は
この記事が気に入ったらサポートをしてみませんか?