GoogleのCloud Pub/SubでBigQueryと連携してみた

分析屋の下滝です。
前回は、Pub/Subをさらっと触ってみました。
今回は、Pub/Subに送信したメッセージを、BigQueryに格納する方法を試してみます。
BigQuery サブスクリプション
Pub/Sub には3つのタイプのサブスクリプションがあります。
・pull
・push
・エクスポートサブスクリプション
・BigQuery サブスクリプション
・Cloud Storage サブスクリプション
前回は、Pullサブスクリプションを試しました。今回は、エクスポートサブスクリプションの一種である、BigQuery サブスクリプションを試します。
詳しくは公式の説明を参照してください。
ざっくり、準備としては
・BigQueryを使えるようにしておく
・Pub/Sub サービス アカウントに BigQuery のロールを割り当てる(上記の公式を参照)
・BigQuery にテーブルを作成しておく
ことが必要になります。
最初の2つは、公式の説明を参照してください。
BigQueryには、次のようなデータセット(pub_sub_test)、テーブル(pub_sub_test_table)を作成しました。

pub_sub_test_tableのdataフィールドに、Pub/Subからのメッセージ内容が格納されます。後に見るように、スキーマを定義して、特定のフィールドにデータを格納することもできます。
では、残りの設定をしていきます。
使うトピックは、前回の記事と同じものを使います。test-topicという名前です。

Pub/Subの画面からBigQueryサブスクリプションを作成してみます。

右上の「サブスクリプションを作成」を押します。
次のような設定で入力します。
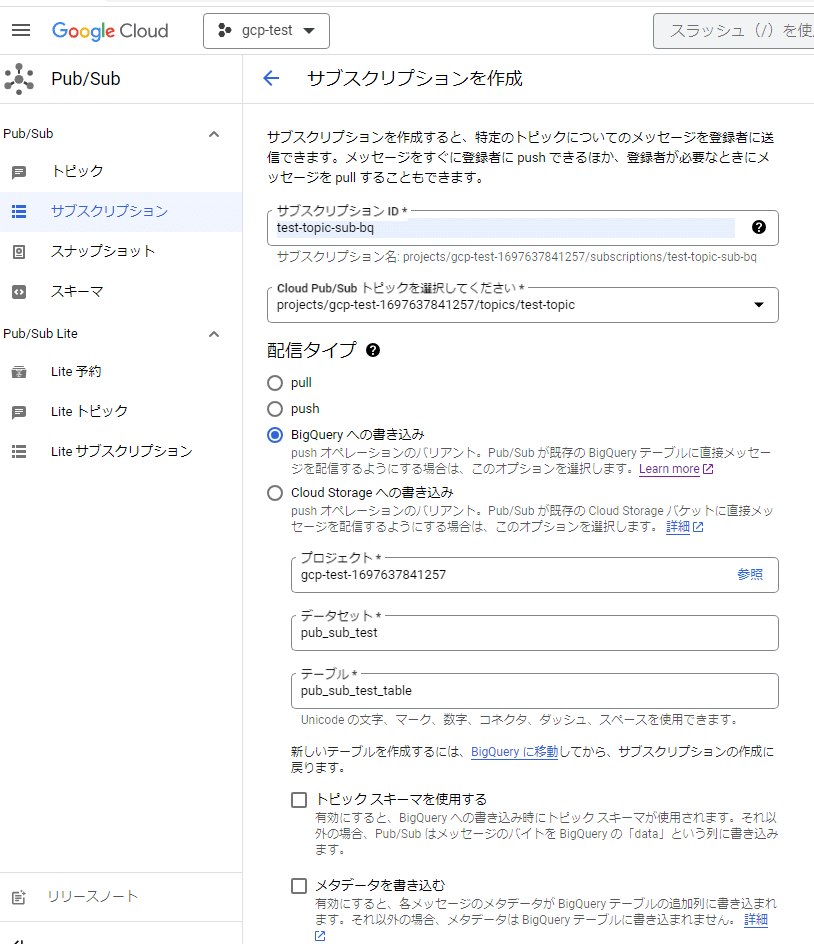
サブスクリプションID
トピック
配信タイプには、「BigQueryへの書き込み」を選択
プロジェクト
データセット
テーブル
を選択・入力してください。
続いて、トピックへのメッセージの送信です。前回の記事と同じです。project_idは、適切なものを設定してください。
"""Publishes multiple messages to a Pub/Sub topic with an error handler."""
from concurrent import futures
from google.cloud import pubsub_v1
from typing import Callable
project_id = "gcp-test-1697637841257"
topic_id = "test-topic"
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_id)
publish_futures = []
def get_callback(
publish_future: pubsub_v1.publisher.futures.Future, data: str
) -> Callable[[pubsub_v1.publisher.futures.Future], None]:
def callback(publish_future: pubsub_v1.publisher.futures.Future) -> None:
try:
# Wait 60 seconds for the publish call to succeed.
print(publish_future.result(timeout=60))
except futures.TimeoutError:
print(f"Publishing {data} timed out.")
return callback
data_list = ["あああ", "いいい"]
for data in data_list:
# When you publish a message, the client returns a future.
publish_future = publisher.publish(topic_path, data.encode("utf-8"))
# Non-blocking. Publish failures are handled in the callback function.
publish_future.add_done_callback(get_callback(publish_future, data))
publish_futures.append(publish_future)
# Wait for all the publish futures to resolve before exiting.
futures.wait(publish_futures, return_when=futures.ALL_COMPLETED)
print(f"Published messages with error handler to {topic_path}.")メッセージ内容が「あああ」と「いいい」となる2通のメッセージをトピックに送ります。
実行結果は以下となります。
>python pub_sub.py
8903378788073495
8903378788073496
Published messages with error handler to projects/gcp-test-1697637841257/topics/test-topic.8903378788073495のような数字は、メッセージIDとなります。詳しくはresultメソッドを参照してください。2通分のメッセージIDが取得できていることが分かります。
送信したメッセージがBigQueryに格納されているか確認します。

格納はされていますが、「あああ」と「いいい」となる文字ではありません。バイトで格納されているためです。
SAFE_CONVERT_BYTES_TO_STRING関数で文字列に変換します。
SELECT data, SAFE_CONVERT_BYTES_TO_STRING(data) FROM `gcp-test-1697637841257.pub_sub_test.pub_sub_test_table` LIMIT 1000文字列が格納されることが確認できました。

変換するのが面倒なので、dataフィールドの型をbytesからstringに変えてみます。pub_sub_test_tableを作り直しました。

メッセージを送信します。
>python pub_sub.py
9572941254597538
9572941254597539
Published messages with error handler to projects/gcp-test-1697637841257/topics/test-topic.文字列で格納されていることが確認できました。

スキーマを定義してみる
トピックには、スキーマを関連付けることができます。
スキーマは、Pub/Sub メッセージの data フィールドが従う必要がある形式です。スキーマは、メッセージの形式について、パブリッシャーとサブスクライバーの間の契約を作成します。Pub/Sub はこの形式を適用します。スキーマは、メッセージ タイプと権限を監視する中央機関を作成することで、組織内のデータ ストリームのチーム間消費を促進します。Pub/Sub メッセージ スキーマは、メッセージ内のフィールドの名前とデータ型を定義します。
では、スキーマを定義し、定義したスキーマの各フィールドが、BigQueryのテーブル上のフィールドに格納される方法を試していきます。
pub/subの画面からスキーマを作ります。
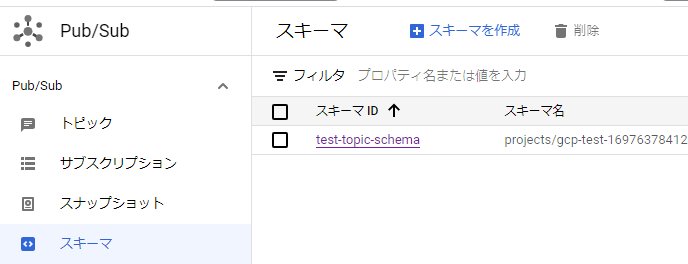
「スキーマを作成」を選びます。

スキーマ名は「test-topic-schema」としました。スキーマのタイプとしてはAvroを選びました。スキーマの定義は以下となります。
{
"type": "record",
"name": "Avro",
"fields": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
]
}int型のid
string型のstring
からなるスキーマを定義しました。
続いて、トピックとスキーマを関連付けます。作成済みのtest-topicにスキーマを関連付けます。トピックの編集を押して、編集画面に開きます。「スキーマを使用する」を選んで、先程作成した「test-topic-schema」を選びます。
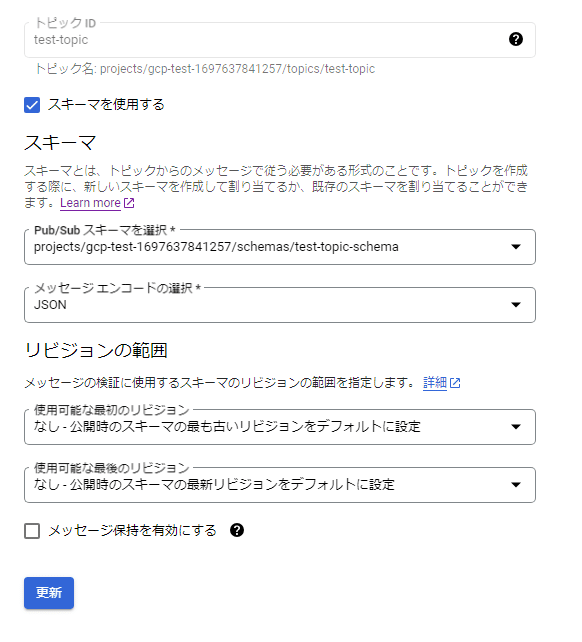
メッセージエンコードではJSONかBINARYを選べます。どういう違いがでるのか分かりませんがひとまずJSONを選びました。
では、メッセージを送信してみます。
メッセージを送信すると、次のようなエラーが出ました。ここでは、例外の一部のみ載せています。
google.api_core.exceptions.InvalidArgument: 400 Invalid data in message: Message failed schema validation. [reason: "INVALID_JSON_AVRO_MESSAGE"
domain: "pubsub.googleapis.com"
metadata {
key: "revisionInfo"
value: "Could not validate message with any schema revision for schema: projects/43450852642/schemas/test-topic-schema, last checked revision: revision_id=070d0c32 failed with status: Tried to parse invalid JSON."
}
metadata {
key: "message"
value: "Message failed schema validation"
}
]スキーマに従っていないためエラーとなっています。
送信プログラムを修正します。
"""Publishes multiple messages to a Pub/Sub topic with an error handler."""
from concurrent import futures
from google.cloud import pubsub_v1
from typing import Callable
import json
# TODO(developer)
project_id = "gcp-test-1697637841257"
topic_id = "test-topic"
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_id)
publish_futures = []
def get_callback(
publish_future: pubsub_v1.publisher.futures.Future, data: str
) -> Callable[[pubsub_v1.publisher.futures.Future], None]:
def callback(publish_future: pubsub_v1.publisher.futures.Future) -> None:
try:
# Wait 60 seconds for the publish call to succeed.
print(publish_future.result(timeout=60))
except futures.TimeoutError:
print(f"Publishing {data} timed out.")
return callback
data_list = [{"id" : 1, "name" : "あああ"}, {"id" : 2, "name" : "いいい"}]
for data in data_list:
# When you publish a message, the client returns a future.
publish_future = publisher.publish(topic_path, json.dumps(data).encode("utf-8"))
# Non-blocking. Publish failures are handled in the callback function.
publish_future.add_done_callback(get_callback(publish_future, data))
publish_futures.append(publish_future)
# Wait for all the publish futures to resolve before exiting.
futures.wait(publish_futures, return_when=futures.ALL_COMPLETED)
print(f"Published messages with error handler to {topic_path}.")json形式で送信するように変更しました。以下2つのメッセージを送ります。
[{"id" : 1, "name" : "あああ"}, {"id" : 2, "name" : "いいい"}]
>python pub_sub.py
9521785915757866
9521785915757867
Published messages with error handler to projects/gcp-test-1697637841257/topics/test-topic.正常に送信されました。
BigQueryではどのように扱われているでしょうか?

dataフィールドにjson文字列がそのまま格納されています。
BigQueryサブスクリプションを変更してスキーマに対応できるように修正します。
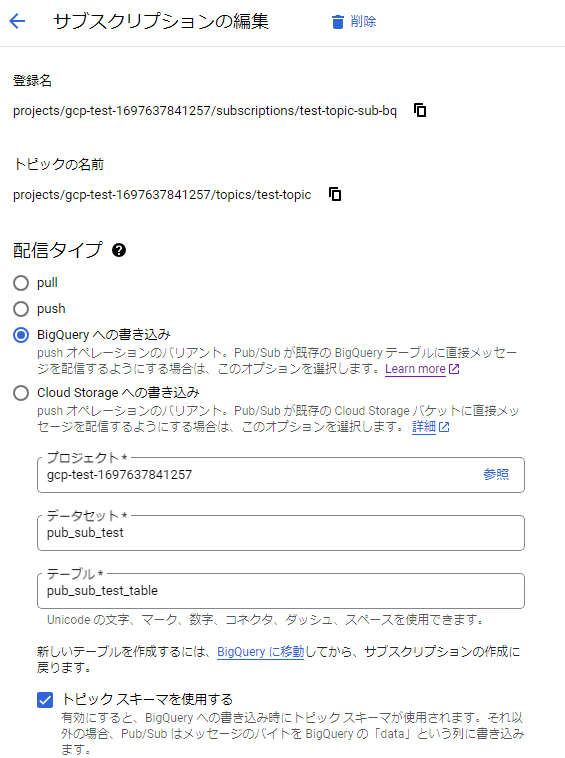
「トピック スキーマを使用する」にチェックを入れて更新します。

スキーマに対応するフィールドがないというエラーが出ました。テーブルにフィールドを作成します。

BigQueryサブスクリプションに戻って更新すると、エラーなく更新されました。
メッセージを送信します。
>python pub_sub.py
8913809496903133
8913809496903134
Published messages with error handler to projects/gcp-test-1697637841257/topics/test-topic.問題なく送れます。
BigQueryで確認します(以前のデータは消しています)。
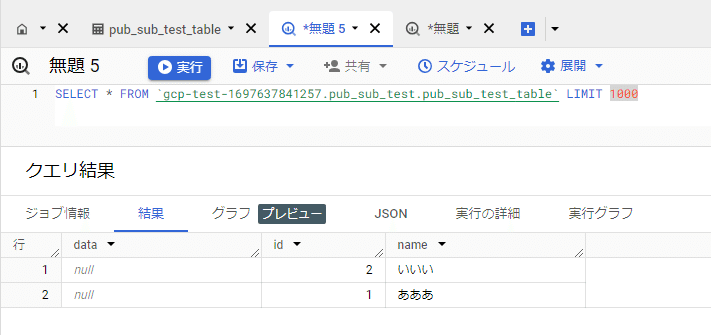
idとnameフィールドに予想通りにデータが格納されていることが分かります。
今回は以上です。
株式会社分析屋について
ホームページはこちら。
noteでの会社紹介記事はこちら。
専用の採用ページはこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。