
datatable vs pandas ~処理が速いのはどっちだ!?~

分析屋の藤島です。
この度行政の案件に参画することになり、pandasやnumpyを使って前処理や集計をすることになりました。先輩から「datatableでpandasに変換する方法を調べてほしい」と話があり、調べて実行してみました。
その際にdatatableとpandasで処理させたときに、どちらが速いのかが個人的に気になったので、簡単に検証してみました。
ぜひ、最後までお読みください!
1.datatableとは
datatableとは高速でデータ処理が可能なライブラリで、Pandasと同様にデータの前処理が行うことができます。
大規模なデータを扱う場合、pandasと比較するとdatatableを使用してデータの前処理を行った方が速いといわれています。
2.今回の検証について
今回検証で使用した環境やデータは下記の通りです。
実行環境 :Colaboratory
バージョン:3.10.12
検証データ:20000×785のデータ(※1)
補足1:datatableのインストールについて
datatableのインストールは下記のコマンドを入力すると、インストールすることが可能です。
# datatableをインストール
!pip install python-datatableただし私がColaboratoryでインストールしたときは、実行途中でエラーが発生してしまいました。
何度か実行することで、ようやくインストールをすることができました。
また、ローカルでインストールしてみたところ、ローカルの方がスムーズにインストールすることができたので、ローカルで実行した方が良いかもしれません。
参考URL:https://pypi.org/project/python-datatable/
補足2:※1について
試しにColaboratoryにあるmnistのデータを使用して、datatableとPandasでデータを読み込んでみました。
その結果、0.5秒差でdatatableの方がわずかに速いことが分かりました。
ちなみに、mnistのサンプルデータは下記のようなデータで、データの中身はすべて1桁の数値でした。
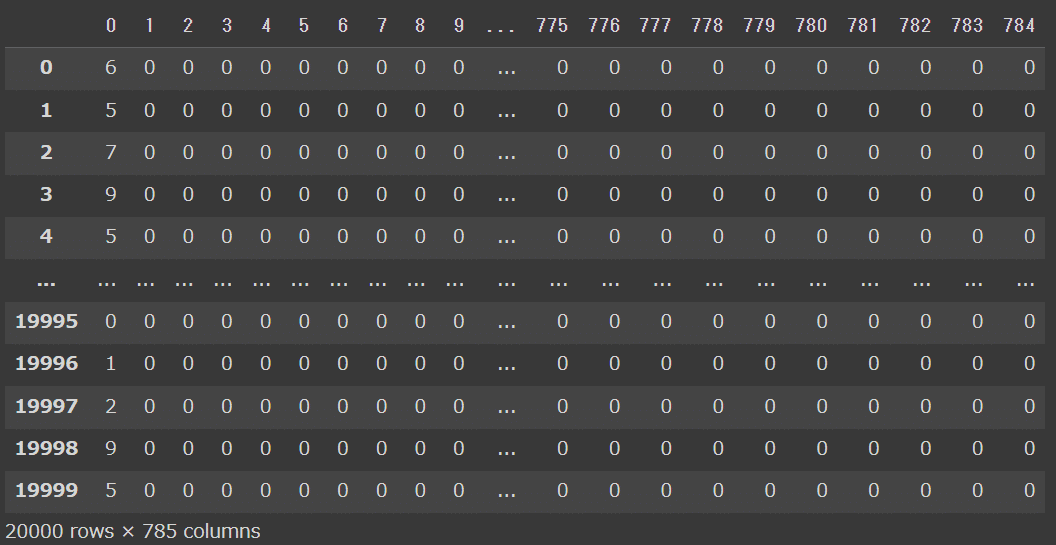
このことからデータの行数と列数を変えずに数値の桁数を大きくすると、mnistのときよりも差が出るのではないかと考えて、5桁〜7桁の数値からなる検証データを作成しました。
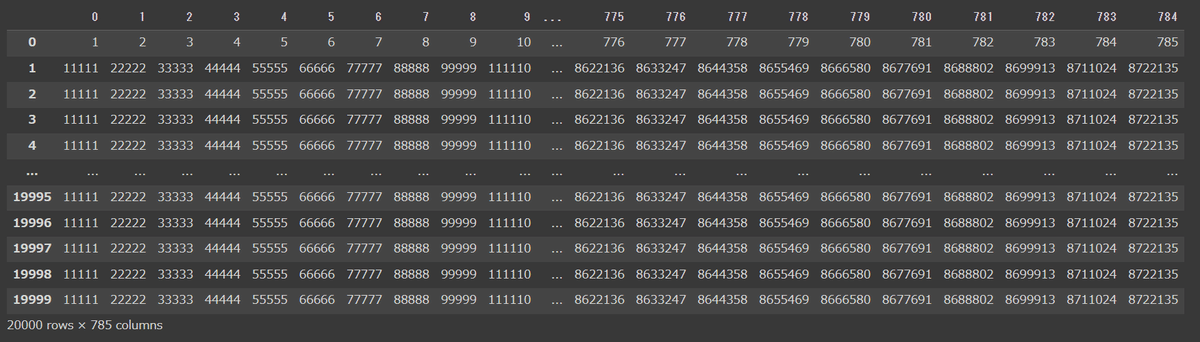
3.データを読み込む
まず、作成した検証データを読み込んでみました。
実行1:datatableで実行
import datatable as dt
# 検証データ読み込み
dfr = dt.fread("/content/drive/MyDrive/ColabNotebooks/Pandas/n_test.csv")
dfr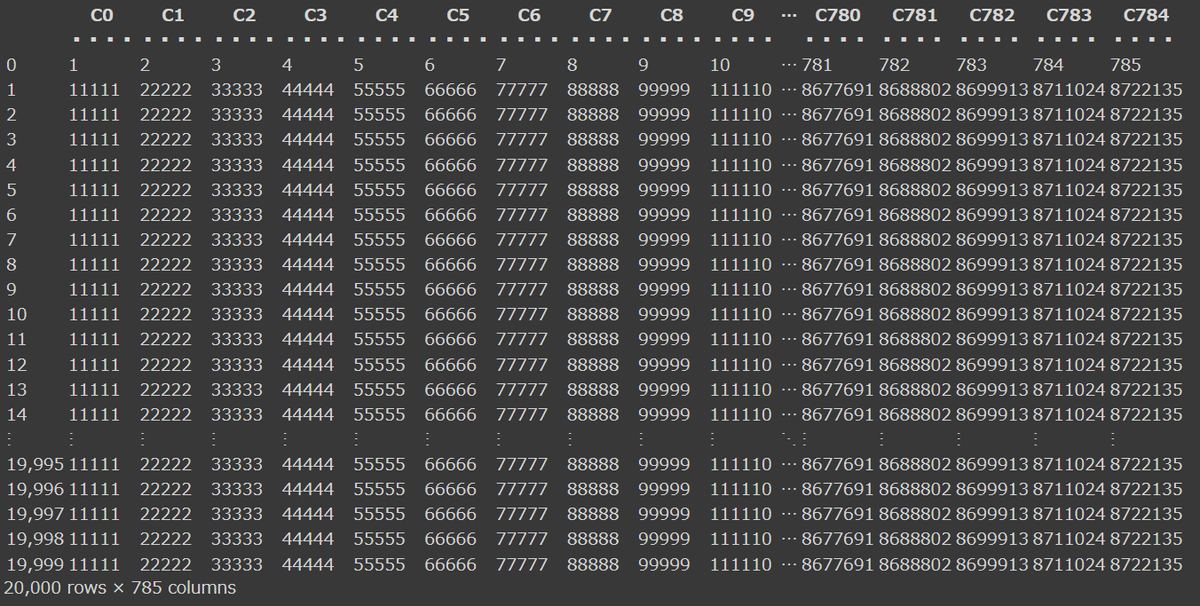
実行2:pandasで実行
import pandas as pd
# pandasでデータ読み込み
pd = pd.read_csv("/content/drive/MyDrive/ColabNotebooks/Pandas/n_test.csv",header=None)
pd
実行時間はそれぞれ下記の通りでした。
datatable:約1.1秒
pandas :約3.3秒
実行時間の差は約2.2秒で、datatableの方が速いことがわかりました。
4.データを読み込んで、カラムを抽出する
次に検証データを読み込んで、カラムを抽出してみました。
実行3:datatableでデータを抽出
import datatable as dt
import pandas as pd
# サンプルデータ読み込み
dfr = dt.fread("/content/drive/MyDrive/ColabNotebooks/Pandas/n_test.csv")
dfr
# pandasに変換
b = dfr.to_pandas()
b
# 条件指定(特定のデータを取り出す)
b[["C0","C1"]]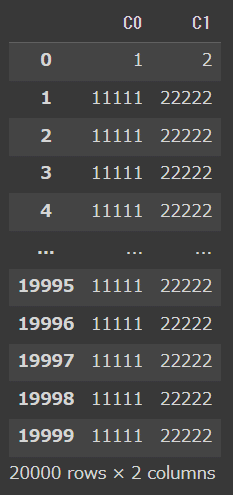
実行4:pandasでデータを抽出
import pandas as pd
pd = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/Pandas/n_test.csv",header=None)
pd
# 条件指定(特定のデータを取り出す)
pd[[0,1]]
実行時間はそれぞれ下記の通りでした。
datatable:約1.1秒
pandas :約3.8秒
実行時間の差は約2.7秒で、datatableの方が速いことがわかりました。
今回の案件ではpandasとnumpyを使用して前処理や集計を行うため、datatableで抽出せずにpandasに変換後、pandasで抽出を行いました。
5.最後に
今回扱ったデータよりもさらに規模が大きいと、datatableの方が便利だなとより実感できるのかなと思いました!
ぜひ皆さんもdatatableを使ってみてください!
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。