
【79日目】100日後にベイズ統計ができるゆーみん

Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P., & Dolan, R. J. (2011) 『Model- based influences on humans’ choices and striatal prediction errors.』の計算論モデルについてまとめました。
※このまとめは元論文、計算論的精神医学、行動データの計算論モデリング、片平先生の『モデルベース強化学習とモデルフリー強化学習について』を元に作成されています!
〜SARSA〜
モデルフリー学習は状態行動価値の推定を環境のモデルを使わず行います。
今回はSARSAを改変したSARSA(λ)を使用しています。
先にSARSAの説明から......
行動価値を推定する場合、「次の時刻の行動価値を何にするか」を考える必要があります。SARSAは次の時刻の行動価値を「実際に次の時刻で選択する行動価値」としています。
状態行動価値の更新式は以下のようになります。
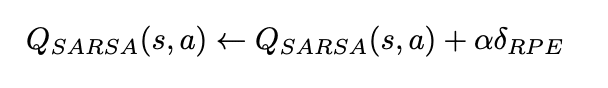

ここでこの↓部分は、
![]()
現在の選択の結果遷移した先の状態で得られた報酬r(s')に、その状態で選択する行動の状態行動価値を足し合わせたものです。
ここから報酬関数の期待値を推定したい場合、QSARSA(s', a') が報酬関数の期待値の推定量であると考えて、以下のようになります。
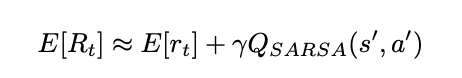
〜SARSA(λ)〜
Daw et al. (2011) では、モデルフリー学習のアルゴリズムとしてSARSA に適格度トレースを導入した SARSA(λ) を用いてい ます。
適格度トレースを用いると、ステージ 2 の結果を直ちにステージ 1 の状態行動価値に反映させることができます。
状態行動価値の更新式は以下のようになります。
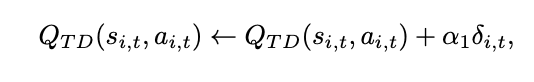
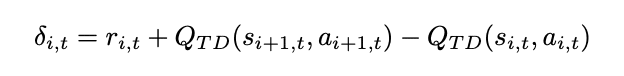
ポイントはここからで、適格度トレースを使って逆向きにステージ 1 の状態行動価値も更新します。
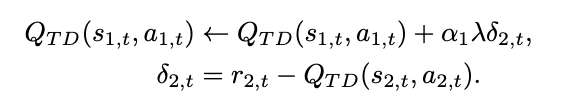
これによりステージ2の報酬予測誤差の結果を元にステージ1で行った選択が良かったのかどうかを評価します。
で、このように計算された状態行動価値を用いて、ソフトマックス関数によって状態sにおける行動aの選択確率が求められます。
モデルベース、ハイブリッドモデルについてはまた明日......
あと21日
この記事が気に入ったらサポートをしてみませんか?