🔰国勢調査から収入予測を試してみました

1. はじめに
自己紹介
私は30代にして以前から興味のあったAI学習をスタートしました。
全くの未経験であったため、オンラインで学習できるスクールを探し、
Aidemyさんのデータ分析(3ヶ月コース)を受講しました。
学習のキッカケ
漠然と「AI」といった単語はよく聞いていましたが、それらがどういう仕組みで動いているのか、どうやって活用できるのかなど、何もわかりませんでした。 30代半ばにしてこれからのキャリアを考える機会も増え、思い切って学んでみようと思いました。
受講を通して感じたこと
やはり、何一つ知識もない状態から独学で勉強していくのは難しいかなと思いました。何をどの順番で勉強していくべきなのかなど、やはり指針があるのとないのでは大きな違いがあるなと感じました。
また、このコースは「専門実践教育訓練給付金」の対象となるため、しっかりと受講すれば最大70%分の受講料が給付金として還付されることも大きかったです。
2. 今回取り組むこと
国勢調査からの収入予測
これまで受講してきた内容の復習を兼ねて、「SIGNATE」の練習問題として提供されている、収入予測のコンペにチャレンジしてみました。今回取り組む収入予測は、職業や学歴、家族構成等のデータを用いて、年収5万ドルを越えるか否かを予測する二値分類問題です。
SIGNATEとは
AIデータ分析の開発コンペティションを多数催すサイトです。開催中のコンペでは、好成績者への賞金などもあり、多くの技術者が参加しています。
基本的にはコンペへの参加は無料ですし、データ分析に必要なデータも豊富に入手できるので、私のような初学者にもとても優しいサイトです。
3. 実行環境とデータセット
実行環境は以下の通りです。
Google Colaboratory
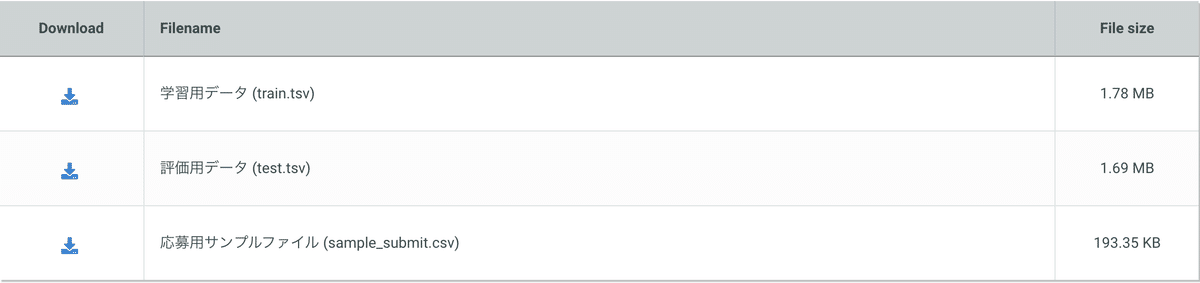
データセットは上述の「SIGNATE」サイトより、
【練習問題】国勢調査からの収入予測のデータを使用します。
4. 実行
データの読み込み
まずはダウンロードしたデータを読み込み、内容を確認します。
# googledriveをマウント
from google.colab import drive
drive.mount('/content/drive')
# 必要なライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib_venn import venn2
# データの読み込み
train_df = pd.read_csv('/content/drive/MyDrive/Dataset/train.tsv', delimiter = '\t')
test_df = pd.read_csv('/content/drive/MyDrive/Dataset/test.tsv', delimiter = '\t')
sample_sub = ('/content/drive/MyDrive/Dataset/sample_submit.csv')
# 訓練データの確認
train_df訓練データは以下のようになっています。
同様に、テストデータも確認します。

# テストデータの確認
test_df訓練データと違い、Targetとなるカラム”Y”がテストデータにはありません。

続いて、訓練データとテストデータの内容について重複の確認をします。
重複があまりにも少ないと、予測時に学習していない状況の予測を行うことになり、テストデータを予測した際に影響が出てしまいます。
今回の場合は、データの偏りはないようです。
# 訓練データとテストデータの重複を確認
fig ,axes = plt.subplots(figsize=(12,12),ncols=8,nrows=1)
for col_name,ax in zip(
['workclass','education','marital-status','occupation','relationship','race','sex','native-country']
,axes.ravel()
):
venn2(
# train_dfとtest_dfのユニークな要素を抽出し、セットにする
subsets=(set(train_df[col_name].unique()), set(test_df[col_name].unique())),
set_labels=('Train', 'Test'),
ax=ax
)
ax.set_title(col_name)
データの結合と統計量の確認
続いて、後のデータの前処理のために予め訓練データとテストデータを結合します。
# データをまとめて処理するために、訓練データとテストデータを結合する
all_df = pd.concat([train_df,test_df],axis=0).reset_index(drop=True)
all_df['Test_Flag'] = 0
all_df.loc[train_df.shape[0]: , 'Test_Flag'] = 1量的データ(数値)・質的データ(カテゴリ)を確認します。
これにより、データの個数や欠損値の有無、データのばらつきなどが確認できます。
# 数値データの統計量を確認
all_df.describe()
# カテゴリカルデータの統計量を確認
all_df.describe(exclude='number')

データの欠損値を確認
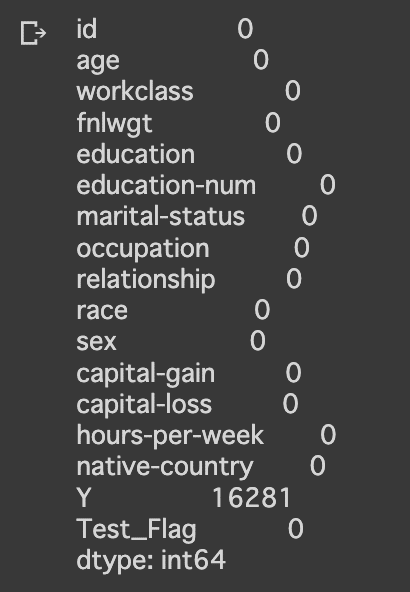
# 欠損データの確認
all_df.isnull().sum()欠損値は以下の通り、特になさそうです。
(Yにおける欠損値は、テストデータによるものです)
データの可視化
次に、データの傾向や特徴を掴むために、グラフを用いてデータを可視化します。これにより、年収5万ドルを達成する人の特徴が掴めると思います。
# 数値データの各変数間の相関をヒートマップで可視化
sns.heatmap(
all_df[['age','fnlwgt','education-num','capital-gain','capital-loss','hours-per-week','Y']].corr(),
vmax=1,vmin=-1,annot=True
)
各数値の相関関係
(1に近いほど正の相関、−1に近いほど負の相関)
各数値データの相関を図で表してみました。そこまで強い相関関係は確認できない(?)ような気がします。
(年齢データ)
# Ageについて可視化
fig = sns.FacetGrid(all_df, col="Y", hue="Y", height=5)
fig.map(sns.histplot, "age", bins=15, kde=False)
30代〜50代の世代は年収5万ドル超の割合が多いことがわかります。
(学歴データ)
#educationについて可視化。
plt.figure(figsize=(30,10))
sns.countplot(x="education", hue="Y", data=all_df)
学位が高いほど、やはり年収も高くなる傾向にあるようです。
(婚姻状況)
#marital-statusについて可視化。
plt.figure(figsize=(30,10))
sns.countplot(x="marital-status", hue="Y", data=all_df) 
婚姻状況にある方が、未婚や離婚者に比べて年収5万ドルの達成率が高いようです。
(Capital-gain、Capital-loss)
# Capital-gainについて可視化
fig = sns.FacetGrid(all_df, col="Y", hue="Y", height=5)
fig.map(sns.histplot, "capital-gain", bins=15, kde=False)
# Capital-lossについて可視化
fig = sns.FacetGrid(all_df, col="Y", hue="Y", height=5)
fig.map(sns.histplot, "capital-loss", bins=15, kde=False)
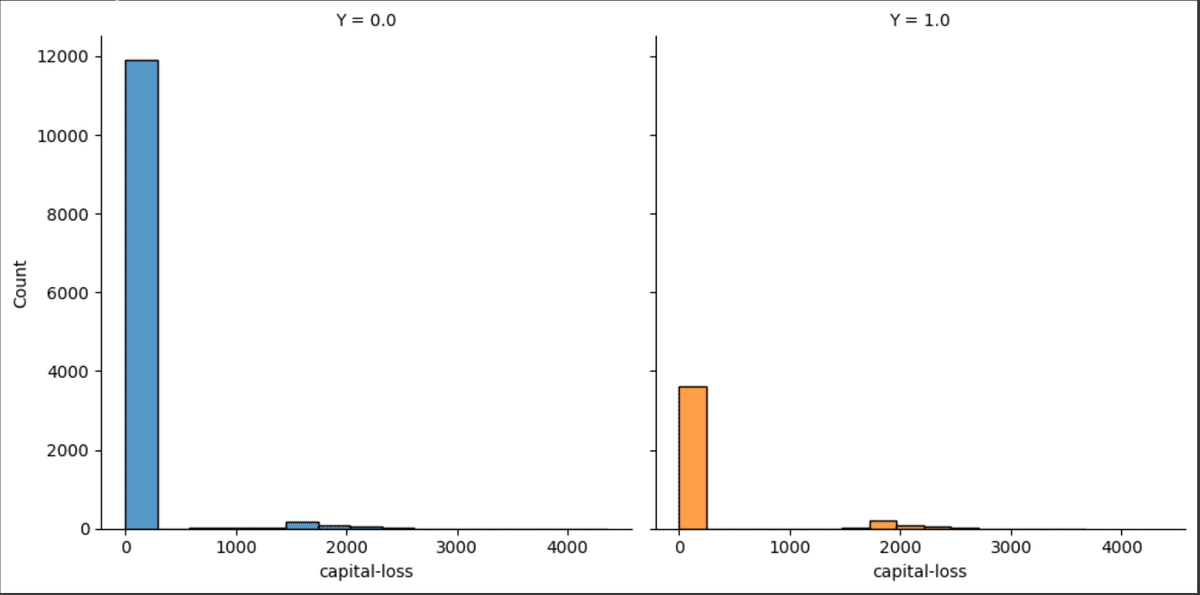
いずれのデータもゼロの対象者が多いことがわかります。データにばらつきがあるのでこのまま学習させてしまうと悪影響を及ぼしそうです。
データの前処理
ここまで色々とデータを見てきました。ある程度の特徴や推測を立てたあと、学習に入る前にデータを加工します。これは、文字列のデータを数値に置き換えたり、高次元のデータを低次元のデータに変換することでより学習の精度を上げるための作業です。
# Ageを年代にまとめる
all_df['age'] = round(all_df['age'],-1)
all_df = all_df.replace({'age': [20]}, 0)
all_df = all_df.replace({'age': [30,40]}, 1)
all_df = all_df.replace({'age': [50,60]}, 2)
all_df = all_df.replace({'age': [70,80,90]}, 3)
# workclassのカテゴリをまとめる
all_df = all_df.replace({'workclass': ['?','Never-worked','Without-pay']}, 0)
all_df = all_df.replace({'workclass': ['Private','Self-emp-not-inc']}, 1)
all_df = all_df.replace({'workclass': ['Local-gov','Federal-gov','State-gov']}, 2)
all_df = all_df.replace({'workclass': ['Self-emp-inc']}, 3)
--------
-(省略)--
--------
# hours-per-weekを40時間で区切る
all_df['hours-per-week'].unique()
all_df['hours-per-week'] = pd.cut(all_df['hours-per-week'],bins=[-1,39,99],labels=['<40','>40'])
# hours-per-weekをOne-Hot encodingで変換
all_df = pd.get_dummies(all_df, columns= ["hours-per-week"])
# capital-gain, capital-lossを分割
all_df['capital-gain']= pd.cut(all_df['capital-gain'],[-1,0,50000,100000],
labels = ['0','<50K', '>50K'])
all_df['capital-loss']= pd.cut(all_df['capital-loss'], [-1,0,5000],
labels = ['N','Y'])
# capital-gain, capital-lossをOne-Hot encodingで変換
all_df = pd.get_dummies(all_df, columns= ['capital-gain','capital-loss'])訓練・検証データへの分割、モデルを構築
結合していた訓練データとテストデータを再度分割し、さらに訓練データを訓練用と検証用に分割します。まずはロジスティック回帰と呼ばれるモデルを構築し、学習を実施、正答率を算出してみます。
# 訓練データと検証データを作成
from sklearn.model_selection import train_test_split
# 訓練データとテストデータを元に戻す
train = all_df[all_df['Test_Flag']==0]
test = all_df[all_df['Test_Flag']==1].reset_index(drop=True)
# 訓練データのカラムYを目的変数とする
target = all_df[all_df['Test_Flag']==0]['Y']
# 今回学習に用いないカラムを削除
drop_col = [
'id', 'fnlwgt','occupation','native-country', 'Y', ]
train = all_df[all_df['Test_Flag']==0].drop(drop_col, axis=1)
# 訓練用と検証用に分ける
X_train ,X_val ,y_train ,y_val = train_test_split(
train, target,
test_size=0.2, shuffle=True, random_state=0
)
# ライブラリのインポート。 予測モデル(ロジスティック回帰)を構築
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier # K近傍法
from sklearn.svm import SVC # サポートベクターマシン
from sklearn.tree import DecisionTreeClassifier # 決定木
from sklearn.ensemble import RandomForestClassifier # ランダムフォレスト
from sklearn.metrics import accuracy_score
# モデルを定義し学習
model = LogisticRegression(max_iter=1500)
model.fit(X_train, y_train)
# 訓練データに対しての予測を行い、正答率を算出
y_pred = model.predict(X_train)
print(accuracy_score(y_train, y_pred))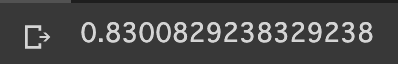
他にも様々なモデルがあるので、いくつかのモデルを比較したいと思います。
# いくつかのモデルを実行
names = ["Nearest Neighbors",
"RBF SVM", "Decision Tree","Random Forest"]
classifiers = [
KNeighborsClassifier(),
SVC(kernel="rbf"),
DecisionTreeClassifier(),
RandomForestClassifier(),
]
# 指定した複数のモデルを順番実行、正答率を算出
result = []
for name, model in zip(names, classifiers):
model.fit(X_train, y_train)
score1 = model.score(X_train, y_train)
score2 = model.score(X_val, y_val)
result.append([score1, score2])
# 正解率の大きい順に並べる
df_result = pd.DataFrame(result, columns=['train', 'val'], index=names).sort_values('val', ascending=False)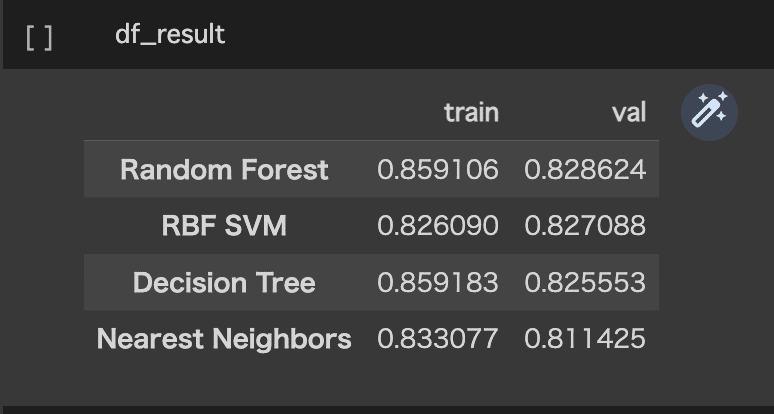
結果を比較すると、
正答率0.828のRandom Forestによる分析が一番良さそうです。
ハイパーパラメータの調整と再学習
ハイパーパラメータとは、機械学習の学習過程を最適化するために人手で調整する値を指します。今回は、グリッドサーチと呼ばれる設定手法を用います。グリッドサーチでは、各設定値の組み合わせを試行し、一番最適な数値の組み合わせを教えてくれます。 ここで得られた数値を元にハイパーパラメータを設定し、モデルの精度向上を図ります。
# グリットサーチによるパラメータの最適化
from sklearn.model_selection import GridSearchCV
# 試すパラメータを指定
parameters = {
"max_depth": [10, 20, 30, 40, 50],
"n_estimators":[25, 50, 100],
"min_samples_split": [2, 4, 6],
"min_samples_leaf": [3, 5],
}
# ランダムフォレストの定義
dmodel = RandomForestClassifier()
# グリットサーチの定義
grid = GridSearchCV(dmodel,
parameters,
cv = 3, # 交差検証の回数
)
# グリットサーチの実行
grid.fit(X_train, y_train)
# 最適なパラメータの表示
print(grid.best_params_)上記のコードを実行することで、下記のハイパーパラメータの設定が最適であることがわかりました。この結果を反映させ、再度学習を実行します。

# 最適化したパラメータで再度学習
fgrid = RandomForestClassifier(max_depth=30,
min_samples_leaf= 5,
min_samples_split= 6,
n_estimators= 100)
fmodel = fgrid.fit(X_train, y_train)
fpred = fmodel.predict(X_val)
# モデルの評価
from sklearn import metrics
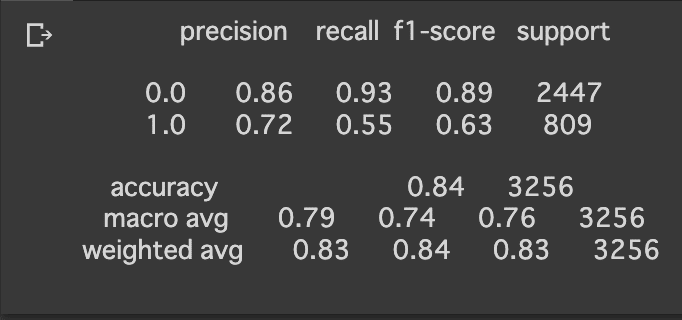
print(metrics.classification_report(y_val, fpred))正答率が0.84になったので、若干の精度向上が確認できました。
テストデータで分析を実施、結果の提出
モデルの作成が完了したので、実際にテストデータの分析を行い、結果をSIGNATEに提出してスコアを確認します。
# testデータの不要なカラムを削除
test = all_df[all_df['Test_Flag']==1].drop(drop_col, axis=1)
# 学習済モデルで評価
pred_test = fmodel.predict(test)
# 結果をDataFrameへ変換
test = pd.DataFrame(pred_test, columns = ['sample_submit'])
# 提出用の形式へ変換
test = test.replace({'sample_submit': {0: '<=50K', 1: '>50K'}})
test = pd.concat([test_df['id'], test], axis=1)
# csvデータで保存
test[['id', 'sample_submit']].to_csv('./submit.csv', header=False, index=False)結果は0.842ということでした。

5. 振り返り
結果はまだまだというところでした。
男女比率の不均衡や外れ値の存在など、データをより多角的に分析することで知見を増やし、それらに柔軟に対応できるようなスキルを身につけられるようになりたいと思いました。
6. まとめ
間違っているところも多々あるとは思いますが、なんとかデータ分析の一連の流れを実装するところまでできるようになりました。 まだまだ未熟ではあるものの、確実に新しい世界への扉を開くことができました。
興味はあるけど今一歩踏み出せない方は、Aidemyさんの講座を受講することをおすすめします!
この記事が気に入ったらサポートをしてみませんか?