
【Difyアプリ】補助金PDFを読み込ませてその情報をもとに回答するチャットボットを作成する

こんにちは
今回は豊島区の事業者向け補助金のご案内というPDFを読み込ませてその内容をもとに回答を作成するチャットボットを作成してみようと思います。
アプリの全体像

処理は以下の流れになっています。
チャット上でユーザーの質問を受け付ける
事前に登録していた豊島区のPDFから情報検索
取得した情報をもとに回答を作成
チャット上で回答
ナレッジの登録
独自のナレッジを使用したチャットボットにおいて一番のチューニングポイントはここだと思います。Difyは読み込み後の情報が可視化されて直感的だったり最小限の設定でもある程度の精度で出力できるようなインターフェイスになっているので非エンジニアの方でも使いやすいのではないかと思います。
それでは登録の仕方を解説していきます。

ナレッジを選択するとテキストファイルをアップロードがあるのでそこから対象のファイルをアップロードします。(今回は事前に用意していた豊島区の補助金PDFを使用します。)
アップロード後次へが活性化するので押下して次に進みます。
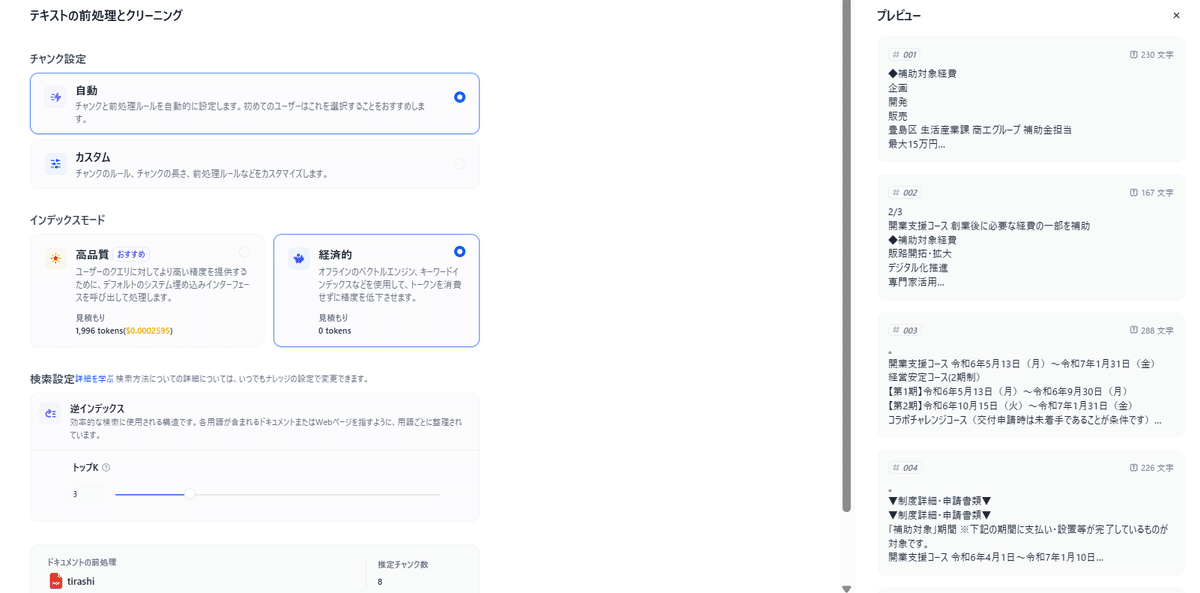
テキストの前処理とクリーニングに進みます。
チャンク設定
自動とカスタムがありますが最初は自動でよいと思います。どの粒度でチャンクにするかが検索精度に影響しますが実際に動かしながら変えていく部分なので最初はプレビューである程度いい感じの粒度でまとまっていればOKです。
インデックスモード
こちらもチャットボットの要件によって変えていく項目になりますが、最初は設定項目のない経済的の選択でOKです。
検索設定
トップKは検索した際に何個のチャンクを持ってくるかという設定でこれも実際に動かしながら値を変えていく項目になるので初期値でOKです。
保存して処理を押下しナレッジを登録します。
ワークフローの作成

チャットボットの作成でChatflowを選択し作成するを押下します。

開始とLLMの間に知識取得のノードを追加します。

知識に先ほどナレッジ登録したPDFを追加します
N-to-1 リトリーバルと書いているところを押下すると下部に推論モデルが選択できる欄があるので好みの推論モデルを選択してください。精度に直結するので能力の高い推論モデルがおすすめです。
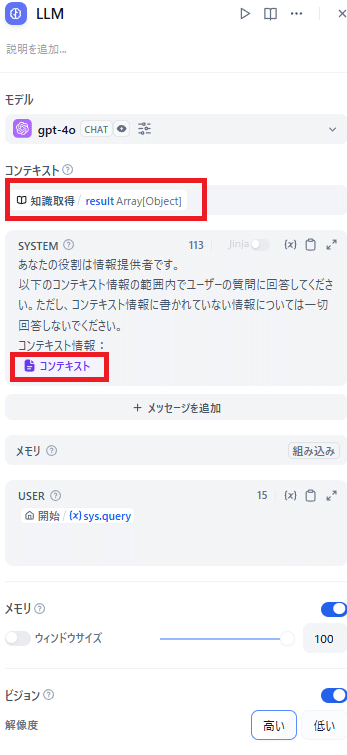
LLMではコンテキストに知識取得のresultを設定します。設定したコンテキストはSYSTEMプロンプト内で使用します。

また、SYSTEMプロンプトに関してはキャプチャのように事前にGPT-4oに最適なプロンプトを考えてもらいました。

デバッグとプレビューからテストしてみます。
うまくPDFから値を取得でき回答することができているようです。
ここで回答がうまく得られない場合、知識取得のデータ取り込みのチューニングを行ったり推論モデルを変えてみたりといったチューニングを行います。
知識取得はあらゆるものをデータソースにできるのでいろいろ置き換えて自作のチャットボットを作ってみてください。
最後に
弊社BizDBでは生成AI関連の相談を承っております。
相談事ありましたらXよりDMいただけると幸いです。
https://x.com/tmatsu06180702
この記事が気に入ったらサポートをしてみませんか?