
Nishika 小説家になろう ブクマ数予測コンペ振り返り

2021/11/29まで、Nishikaで行われていたNLPテーブルコンペ、”小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~”に参加しました。以前参加したProbspaceの論文引用数予測コンペ時の知識で突撃しましたが、最終29位でフィニッシュ。銀メダルとはいえ上位とは大きな差を作ったまま終わりました。本記事では公開していただいた上位陣の解法を参考にしながら、コンペの振り返りをします。
コンペ概要
コンペ”小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~”は、小説投稿サイト「小説家になろう」へ過去投稿された小説について、そのタイトル、概要、キーワードタグなどの情報からそのブックマーク数を予測するコンペです。予測すべきブックマーク数は5段階にビニングされており、そのどのクラスに属するのか、を予測する分類問題となっています。予測の評価に用いるのはloglossです。
上位陣の解法と私の反省
一位と二位の方の解法が公開されています。共通する点は以下の3つであると思います。
時間で区切ったデータについてBERTモデルで訓練および推論し、その予測値をスタッキングしてcatboostで最終予測
訓練にメインに用いるデータは、2007~2021年あるうちの2020年以降のみ
特定のキーワードを含むかどうかのone-hot特徴量を追加
BERT乱舞な解法でした。さらに一位の方は与えられたデータを元にMasked Language Model の形でBERTモデルのfine tuningをしていました。私は以前の論文引用数予測コンペと同じ竹槍(word2vec, topic model)で戦いに臨んだのですが、上位陣はBERTというライフル銃で戦っていたようです。ただ竹槍なりにも上位解法のようにうまくスタッキングするとスコアは良くなるのかもしれません。(BERTと同様試さねば)
また2の用いるデータの期間については、後で詳しく述べますが、評価に用いるテストデータが2021年のもののみであることから、2007~2021年の内容が含まれている教師データとの間で性質が異なっていそうな感じがありました。私もこの事実には(遅い段階で)気づいており、なんとなくでデータを2016~にしていました。ちゃんと実験をしないといけませんね。。
最後の特定ワードに関する特徴量については、私もブックマーク数に応じて、このキーワードがあれば何点追加、みたいに緩いターゲットエンコーディングをしてみたのですが、過学習したのかむしろスコアが悪化しました。きっとその特徴量を作るにあたっても用いるデータの期間を限定する必要があったように思います。
このコンペの目的は、ブックマーク数が伸びる小説のメタデータはどんなものか?というものです。解法を振り返りますと、ブックマーク数は直近の流行りに影響されるということなのでしょう。ただ、その流行を作り出す作品を予測できるかどうかには、評価指標を変えたりするなど別の問題にする必要がありそうです。
以下は私が気づいたこのコンペの特徴を書いていきます。おまけ+備忘録
課題の特徴
1. 不均衡データ
小説家になろうへ投稿された小説の数はかなり多いですが、その中でもブックマーク数が多いものは当然限られます。今回与えられたデータも同様で、ブックマーク数のクラス0~4の中で4をとるデータは非常に少ないです。

このように不均衡なクラスを持つデータについては、教師データ数が少ないクラスに属するデータを予測するのが難しくなるため、いくつかの工夫がとられます。例えばデータ数自体をいじる手段として、少ないクラスに属するデータを補完して増やすupsampling、多いデータを削減するdownsamplingがあります。どちらもimblearnというライブラリで容易に実装できました。
また損失関数についての工夫では、データ数が少ないために正解率が低くなっているクラスの損失を余分に増やすfocal lossを用いることが挙げられます。focal lossはこちらの記事を参考にコピペ実装しました。
以上の不均衡データへの対策手法は、実際のところほぼ効果がありませんでした。この理由は、後から気づいたのですが、たぶん後述するテストデータと教師データの年別分布についての性質にあります。
2. データの投稿年分布(なろうはここ数年でスゴイ!)
与えられたデータは、2007年から2021年まで投稿された小説を対象にしています。年別にデータ数をみると、圧倒的に2021年の数が多いです。
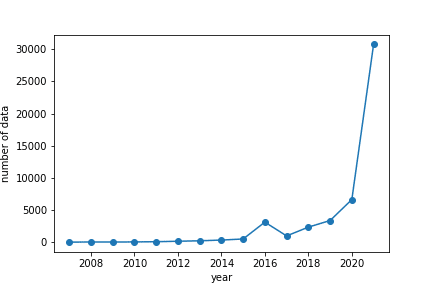
また推論に用いるテストデータは、一番直近の2021年の投稿小説からのみ構成され、それ以前の投稿日の小説を教師データとして与えられていました。よってテストデータには、そもそもブックマーク数が高くなりにくい性質が伺えます。下に教師データを2020年以前、2021年に分けてブックマーク数分布をプロットします。
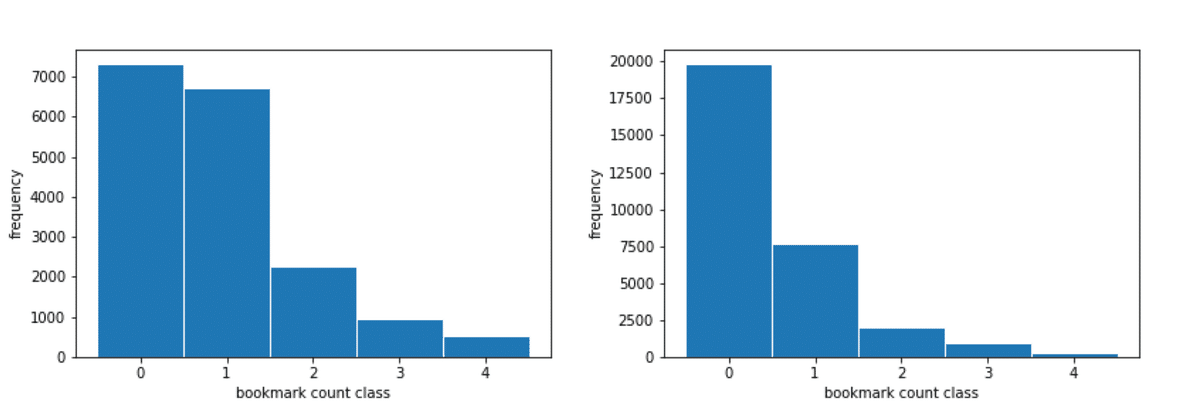
左: 2020年以前、右: 2021年
このように2021年とそれ以前では分布が異なっており、すなわちテストデータと2007~の教師データ全体とでは分布がちょっと異なっている可能性が大きいです。(ちょっと、というのはそもそも2020年以前のデータ数が少ないため) またこれだけ投稿数の差があると、ブックマークをする方の状況も変わっているはずで、2010年の流行りが2021年に流行るか、というと難しいでしょう。上で述べた不均衡データへの対処法は、テストデータからの乖離を促すのみであり、スコアには貢献できなかったのだと想像します。もしかしたら2021年のデータのみを用いる学習の時に施せば有効だったのでしょうか?
以上
この記事が気に入ったらサポートをしてみませんか?