
入社して1年で取り組んだ3つのこと

株式会社ラフールでSREをしている伊藤です。弊社の技術的な取り組み等を理解してもらうために、不定期ですが技術的な事を書いています。
※SREとは、Site Reliability Engineer(サイト信頼性エンジニア)の略称で、サービスやインフラの信頼性を支えているエンジニア。
私のプロフィールについては第1回目の記事(リンク)に記載していますので、興味のある方はぜひ一読していただけると幸いです。
株式会社ラフールに入社して1年が経ち、会社としても自身としても新しいことに色々取り組んできましたが、今回はその中でも思い入れのある3つの取り組みについて簡単に紹介したいと思います。
1:サービスの状態を見える化
入社時、サービスそのものは安定稼働しており大きな問題は無かったのですが、定量的なサービスの状態把握がやや不足していました。
そのため、2回目の「その2 とにかく見える化」のように、まずは最低限押さえておきたいサービスの「エラーレート」や「レスポンスタイム(95%タイル)」、「サーバーのディスク使用率」等を見える化しました。
見える化するために、見える化に特化したサービスを新たに導入することも検討したのですが、まずはコストをかけずにスピード感持って対応するという観点から、既にあるツールを極力有効活用するようにしました。
具体的には、当社サービスがAWS上で稼働していることから、日々発生したエラーやスロークエリ、週間でのエラーレートを見える化するために、AWSのCloudwatchを使ってダッシュボードを作成したり、AWSのLambda、Step Functions、Cloudwatch Eventsを使ってSlackで定期的に通知するようにしました。
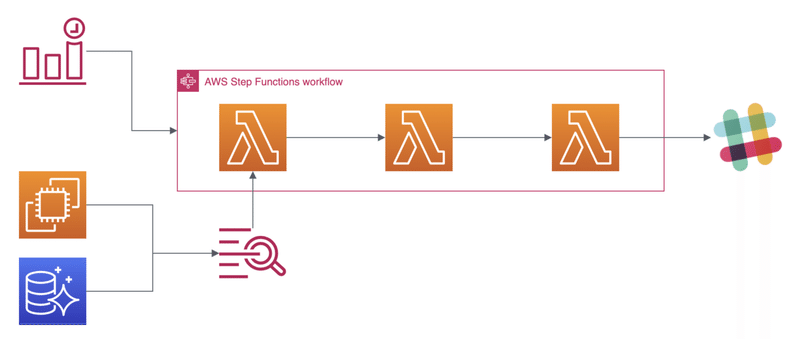
↑AWS構成イメージ
↑ダッシュボードのイメージ
↑Slack通知のイメージ
この取り組みの結果、開発チーム全体でサービスの状態を定量的に知ることができ、エラーレートの改善を一つの目標として品質の改善に取り組む流れができました。
2:インフラの構成をコード化
入社時、専任のインフラエンジニアが不在であったことから、AWSのEC2インスタンス作成やALBの設定変更等は管理画面からポチポチと手作業で行う運用でした。
サービスのフェーズとして、「0→1」の頃はアプリケーションを開発するのにエンジニアリソースを全振りすることが多く、学習コストやメンテナンスコストの観点からこの運用でも問題は無いかとは思います。しかし、「1→10」の頃になるとサービスの拡大を意識するようになり、冗長化や各種環境の手配、様々なAWSの機能の活用等で、手作業では色々と面倒になり、サービス拡大のボトルネックになり得ます。
当社サービスが「0→1」から「1→10」のフェーズに移行しつつあることから、インフラの構成をコード化することを決意しました。
メインのクラウドサービスがAWSであるため、コード化のツールとして「Cloud Formation」も選択肢にはあったのですが、今後AWS以外のクラウドサービス利用の可能性がある点や、世の中の情報量の点から「Terraform」を採用しました。

いきなり全てのインフラの構成管理をTerraform化するのは色々な点からややリスクかと思い、新規サービスや既存サービスの新しい環境からTerraformを使い始めました。
これは使った人にしかわかりませんが、Terraformを一度使い始めると、Terraform無しでは耐えられない体になってしまいました(笑)

Terraformを使い始めたことで、以下の3つのメリットがありました。
・環境構築や設定変更が短時間で行えるようになった。
・コードとして表現されることで細かい設定まで漏れなく把握できるようになった。
・Git等のバージョン管理システムと組み合わせることで、変更履歴が残せるようになった。
しかし、この手のツールを使うデメリットとして、属人化してしまい中長期的に技術的負債になり得る場合があり、この点については今後のタスクとして、運用マニュアルを整備したり、TerraformのCI/CDパイプラインを構築したりしていきたいです。
もし、実際の運用でいきなりTerraformを使うのが難しいという方も、ひとまずterraformerというツールを使って既存の構成をTerraformのコードに落としておくだけでもオススメします。
このツールはGoogleが開発したもので、既存のインフラ構成をTerraformのコードとして簡単に出力してくれます。コード化しておくことで、万が一誤ってインスタンスを削除してしまったとしても、インスタンス自体は容易に復旧することが可能となります。
3:本番システムでのコンテナ利用
1回目でも触れましたが、当社サービスではローカルでの開発環境以外ではEC2をベースとしたインフラ構成となっています。
いずれ全サービスのコンテナ化を進めたいのですが、ひとまず新規サービスから試してみようということで、昨年社内向けにローンチしたサービスで初めて本番システムでコンテナを利用しました。
AWSですので、ECSかEKSか悩んだのですが、当社内でのKubernetesの運用ノウハウが現時点では少ない点と、AWSでのECSの方が歴史が長い点から、今回はECSを採用しました。
さらに言えばCI/CDツールであるCircleCIと組み合わせて、デプロイパイプラインを構築しました。これにより、GitHubのリポジトリからコンテナイメージの作成、ECRへのプッシュ、ECSのコンテナ入れ替えまで一気通貫で行うことができるようになりました。
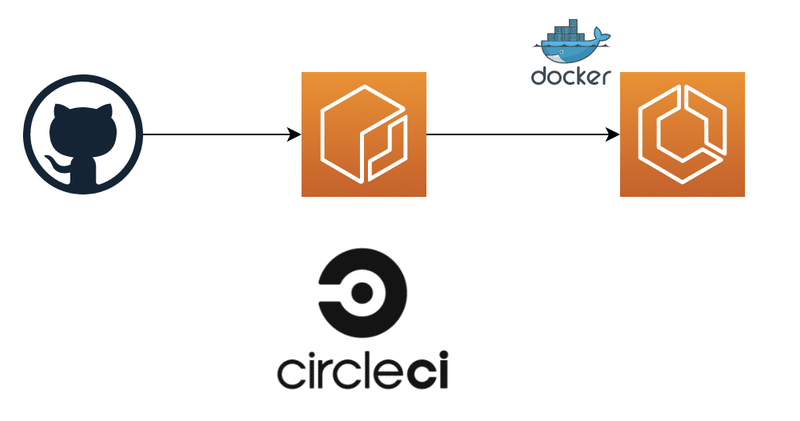
これまで既存サービスではデプロイサーバ上でのコマンド実行によるデプロイでしたが、GitHub上のPRマージをトリガにデプロイが行われるのは、少しではありますが開発者の負担を減らすことができたかと思います。
今後は、メインのサービスでもECS+CircleCIによるデプロイパイプラインを構築していければと考えています。また、技術的な面での選択肢を増やす観点からEKSも触ってみたいです。
まとめ
今回は私が入社して1年で取り組んだ3つのことについて書かさせていただきました。それぞれの詳細な話は今後の記事で触れられればと思います。
拙い文章となってしまいましたが、最後まで読んでいただき誠にありがとうございました。次回記事も読んでいただけると幸いです!
この記事が気に入ったらサポートをしてみませんか?